本文主要是介绍linux: ip rule 用法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 策略路由
- ip rule 描述
- 语法
- 参数
- 例子
- ip rule,ip route,iptables 三者之间的关系
- 参考
策略路由
我们不仅要根据目的地地址,还要根据其他数据包字段(源地址、IP 协议、传输协议端口甚至数据包有效负载)来不同地路由数据包。此任务称为策略路由。Linux 策略路由是一种基于策略的路由机制,相对于传统的基于目的地址的路由机制,它可以提供更灵活和强大的路由控制能力。
在 Linux 中,策略路由通过使用路由策略数据库(RPDB)来实现,它可以根据不同的源地址、传输层端口和 payload 等条件进行更细致的路由控制。
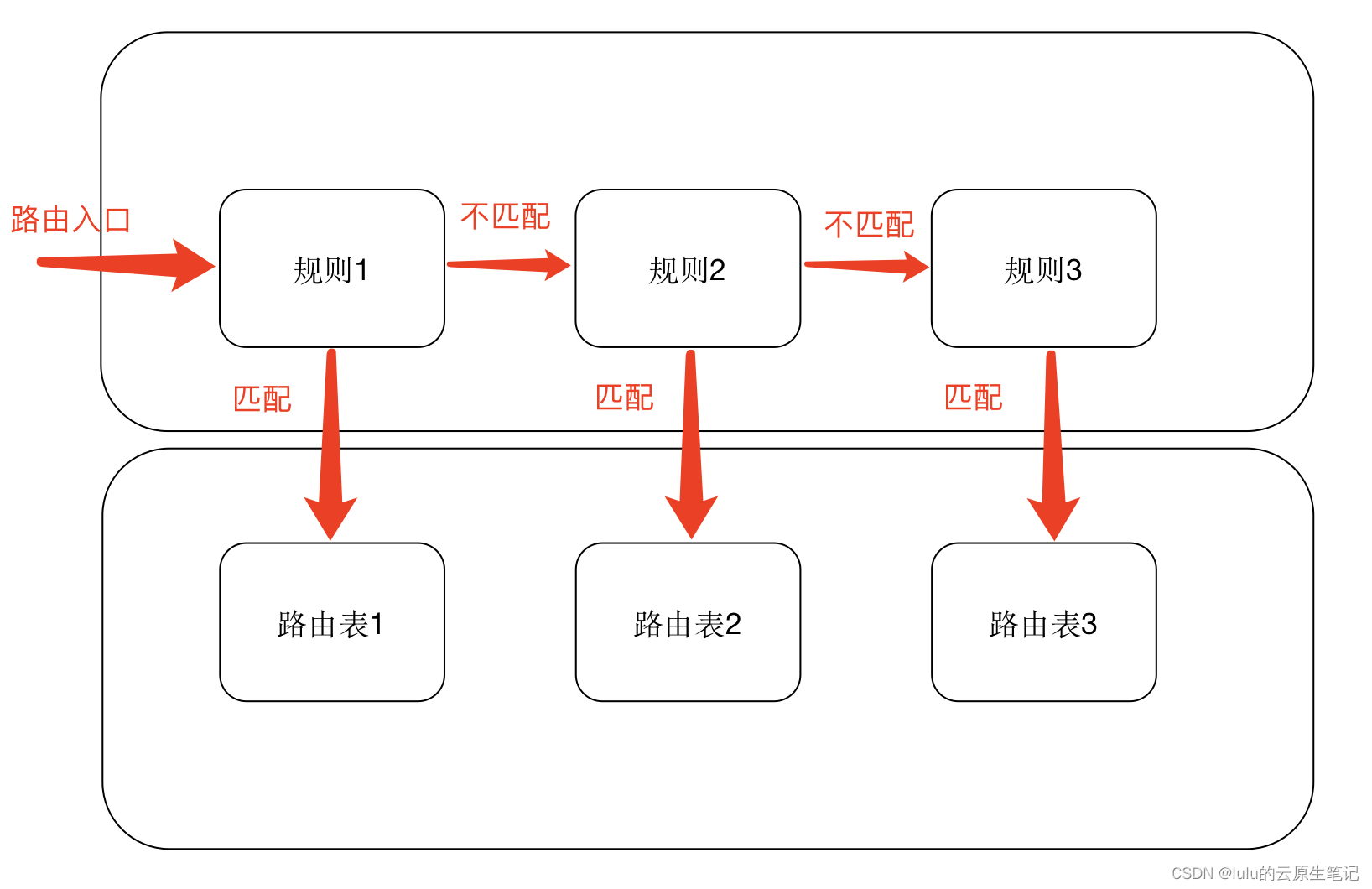
每条策略路由的规则由一个选择器和一个动作组成,RPDB 按照优先级顺序进行规则匹配,优先级数字越小越优先。被选择器匹配的报文会执行对应的操作,操作如果成功,则根据指定的路由转发数据,之后终止 RPDB 匹配;如果执行失败,则报错并且终止 RPDB 匹配。否则 RPDB 将继续执行下一条规则。
在启动时,内核配置默认的 RPDB,包括三个规则:
- 优先级:0,选择器:匹配任何内容,操作:查找路由表本地(ID 255)。本地表是一种特殊的路由表,包含本地和广播地址的高优先级控制路由
- 优先级:32766,选择器:匹配任何内容,操作:查找路由表main(ID 254)。主表是包含所有非策略路由的常规路由表。此规则可以被删除和/或由其他规则覆盖管理员
- 优先级:32767,选择器:匹配任何内容,操作:查找路由表default(ID 253)。默认表为空。如果没有先前的默认规则选择数据包,则它将保留用于某些后处理。这条规则也可能将被删除
**注:**不要混淆路由表和策略:规则指向路由表,多个规则可以引用一个路由表,而且某些路由表可以策略指向它。如果系统管理员删除了指向某个路由表的所有规则,这个表没有用了,但是仍然存在,直到里面的所有路由都被删除,它才会消失。
linux 系统中,可以自定义从 1-252个路由表,其中,linux 系统维护了4个路由表:
0#表: 系统保留表
253#表: default table 没特别指定的默认路由都放在该表
254#表: main table 没指明路由表的所有路由放在该表
255#表: local table 保存本地接口地址,广播地址、NAT地址 由系统维护,用户不得更改
每个 RPDB 条目都有附加属性。每个规则都有一个指向某个路由表的指针。NAT 和伪装规则有一个属性来选择要翻译/伪装的新 IP 地址。除此之外,规则还有一些可选的路由拥有的属性,即领域。这些值不会覆盖路由表中包含的值。它们仅在路由未选择任何属性时使用。
RPDB 可能包含以下类型的规则:
- unicast:规则规定返回在规则引用的路由表中找到的路由
- blackhole:规则规定悄悄地丢弃数据包
- unreachable:规则规定生成“网络不可达”错误
- prohibit:规则规定生成“管理禁止通信”错误
- nat:规则规定将IP数据包的源地址转换为其他值
ip rule 描述
在 Linux系统中,ip rule 命令用于管理和配置策略路由(Policy-Based Routing)。策略路由允许根据数据包的特定属性(如源地址、目标地址、IP报文头部标记等)来选择不同的路由表进行路由决策,而非仅基于目的IP地址。这是传统路由(即使用 ip route 设置的主路由表)功能的一个补充和扩展。
语法
Usage: ip rule { add | del } SELECTOR ACTIONip rule { flush | save | restore }ip rule [ list [ SELECTOR ]]
SELECTOR := [ not ] [ from PREFIX ] [ to PREFIX ] [ tos TOS ][ fwmark FWMARK[/MASK] ][ iif STRING ] [ oif STRING ] [ pref NUMBER ] [ l3mdev ][ uidrange NUMBER-NUMBER ][ ipproto PROTOCOL ][ sport [ NUMBER | NUMBER-NUMBER ][ dport [ NUMBER | NUMBER-NUMBER ] ]
ACTION := [ table TABLE_ID ][ protocol PROTO ][ nat ADDRESS ][ realms [SRCREALM/]DSTREALM ][ goto NUMBER ]SUPPRESSOR
SUPPRESSOR := [ suppress_prefixlength NUMBER ][ suppress_ifgroup DEVGROUP ]
TABLE_ID := [ local | main | default | NUMBER ]
常用:
ip rule flush # 刷新路由规则,此命令没有参数
ip rule list # 列出路由规则,此命令没有参数
ip rule add/del SELECTOR ACTION
参数
ip rule add/del SELECTOR ACTION可选的 option:
- type TYPE (default):规则类型
- from PREFIX:选择要匹配的源前缀
- to PREFIX:选择要匹配的目的前缀
- iif NAME:选择要匹配的传入设备。如果接口是环回,则该规则仅匹配源自此主机的数据包。这意味着您可以为转发的数据包和本地数据包创建单独的路由表,从而完全隔离它们。
- oif NAME:选择要匹配的传出设备。传出接口仅适用于来自绑定到设备的本地套接字的数据包
- tos TOS/dsfield TOS:选择要匹配的TOS值
- fwmark MARK:选择要匹配的标记值
- priority PREFERENCE:此规则的优先级。每个规则都应该有一个显式设置的唯一优先级值
- table TABLEID:如果规则选择器匹配,则要查找的路由表标识符。也可以使用查找而不是表格
- realms FROM/TO:选择规则是否匹配以及路由表查找是否成功的领域。 仅当路由未选择任何领域时才使用领域TO
- nat ADDRESS:要转换的IP地址块的基础(用于源地址)。 地址可以是NAT地址块的开始(由NAT路由选择),也可以是本地主机地址(甚至为零)。 在最后一种情况下,路由器不转换数据包,而是将其伪装到该地址。使用map-to代替nat意味着同样的事情
例子
ip rule add from 192.203.80/24 table inr.ruhep prio 220 # 通过路由表 inr.ruhep 路由来自源地址为192.203.80/24的数据包
ip rule add from 193.233.7.83 nat 192.203.80.144 table 1 prio 320 # 把源地址为193.233.7.83的数据报的源地址转换为192.203.80.144,并通过表1进行路由
ip rule,ip route,iptables 三者之间的关系
iptables:iptables 其实 不是真正的防火墙,我们可以把它理解成一个客户端代理,用户通过 iptables 这个代理,将用户的安全设定执行到对应的"安全框架"中,这个"安全框架"才是真正的防火墙,这个框架的名字叫 netfilter。

注:图中 “路由判断” 就是使用 ip rule,ip route 设置的规则,其中 ip route 配置的路由表服务于 ip rule 配置的规则。
以一例子来说明:公司内网要求192.168.0.100 以内的使用 10.0.0.1 网关上网 (电信),其他IP使用 20.0.0.1 (网通)上网。
1,首先要在网关服务器上添加一个默认路由,当然这个指向是绝大多数的IP的出口网关:ip route add default gw 20.0.0.1
2,之后通过 ip route 添加一个路由表:ip route add table 3 via 10.0.0.1 dev ethX (ethx 是 10.0.0.1 所在的网卡, 3 是路由表的编号)
3,之后添加 ip rule 规则:ip rule add fwmark 3 table 3 (fwmark 3 是标记,table 3 是路由表3 上边。 意思就是凡事标记了 3 的数据使用 table3 路由表)
4,之后使用 iptables 给相应的数据打上标记:
iptables -A PREROUTING -t mangle -i eth0 -s 192.168.0.1 - 192.168.0.100 -j MARK --set-mark 3
参考
https://zhuanlan.zhihu.com/p/144585950
https://www.kancloud.cn/chunyu/php_basic_knowledge/2137338
这篇关于linux: ip rule 用法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





