本文主要是介绍Prometheus实战篇:Alertmanager配置概述及告警规则,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Prometheus实战篇:Alertmanager配置概述及告警规则
在此之前,环境准备和安装我就不在重复一遍了.可以看之前的博客,这里我们直接步入正题.
Alertmanager配置概述
Alertmanager主要负责对Prometheus产生的告警进行统一处理,因此在Alertmanager配置中一般会包含以下几个主要部分:
- 全局配置(global) : 用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates) : 用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route) : 根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers) : 接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般告警路由使用;
- 抑制规则(inhibit_rules) : 合理设置抑制规则可以减少垃圾告警的产生
global:#163服务器smtp_smarthost: 'smtp.163.com:465'#发邮件的邮箱smtp_from: 'cdring@163.com'#发邮件的邮箱用户名,也就是你的邮箱 smtp_auth_username: 'cdring@163.com'#发邮件的邮箱密码smtp_auth_password: 'your-password'#进行tls验证smtp_require_tls: falseroute:group_by: ['alertname']# 当收到告警的时候,等待group_wait配置的时间,看是否还有告警,如果有就一起发出去group_wait: 10s# 如果上次告警信息发送成功,此时又来了一个新的告警数据,则需要等待group_interval配置的时间才可以发送出去group_interval: 10s# 如果上次告警信息发送成功,且问题没有解决,则等待 repeat_interval配置的时间再次发送告警数据repeat_interval: 10m# 全局报警组,这个参数是必选的receiver: emailreceivers:
- name: 'email'#收邮件的邮箱email_configs:- to: 'cdring@163.com'
inhibit_rules:- source_match:severity: 'critical'target_match:severity: 'warning'equal: ['alertname', 'dev', 'instance']
在全局配置中需要注意的是resolve_timeout,该参数定义了Alertmanager持续多长时间未接收到告警后标记告警状态为resolved(已解决).该参数的定义可能会影响到告警恢复通知的接收时间,读者可根据自己的实际场景进行定义,其默认值为5分钟.在接下来的部分,我们将以一些实例的例子解释Alertmanager的其他配置内容.
Prometheus告警规则
Prometheus中的告警规则允许你基于PromQL表达式定义告警触发条件,Prometheus后端对这些触发规则进行周期性计算,当1满足触发条件后则会触发告警通知.默认情况下,用户可以通过Prometheus的Web界面查看这些告警规则以及告警的触发状态.当Prometheus与Alertmanager关联后,可以将告警发送到外部服务可以对这些告警进行进一步的处理.
- 告警规则是配置在Prometheus服务器
与Alertmanager关联
Prometheus把产生的告警发送给Alertmanager进行告警处理时,需要在Prometheus使用的配置文件中添加关联Alertmanager组件的对应配置内容.
1.编辑Prometheus.yml文件加入关联Alertmanager组件的访问地址,示例如下:
# Alertmanager 配置
alerting:alertmanagers:- static_configs:- targets: ['alertmanager:9093']
2.添加监控Alertmanager,让Prometheus去手机Alertmanager的监控指标.
- job_name: 'alertmanager'scrape_interval: 15sstatic_configs:- targets: ['alertmanager:9093']
配置告警规则文件
vim promtheus/alert.yml
告警规则配置如下:
groups:
- name: Prometheus alertrules:# 对任何实例超过30秒无法联系的情况发出警报- alert: 服务告警expr: up == 0for: 30slabels:severity: criticalannotations:summary: "服务异常,实例:{{ $labels.instance }}"description: "{{ $labels.job }} 服务已关闭"
在告警规则文件中,我们可以将一组相关的规则设置定义在group下.在每一个group中我们可以定义多个告警规则(rule).一条告警规则主要由以下几部分组成:
- alert: 告警规则的名称
- expr: 基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件
- for: 评估等待时间,可选参数.用于表示只有当前触发条件持续一段时间后在发送告警.在等待时间新产生的告警的状态为pending
- labels: 自定义标签,允许用户指定要附加到告警上的一组附加标签
- annotations: 用于指定一组附加信息,比如用于描述告警详情信息的文字等,annotations的内容在告警产生时会作为参数发送到Alertmanager
指定加载告警规则
为了能够在Prometheus能够启用定义的告警规则,我们需要在Prometheus全局配置文件中通过rule_files指定一组告警规则文件的访问路径,Prometheus启动后会自动扫描这些路径下规则文件中定义的内容,并且根据这些规则计算是否向外部发送通知:
具体配置
# 报警(触发器)配置
rule_files:- "alert.yml"- "rules/*.yml"
重新加载配置
curl -x POST http://localhost:9090/-/reload
查看告警状态
重启Prometheus后,用户可以通过Prometheus WEB界面中Alerts菜单查看当前Prometheus下的所有告警规则,以及当前所处的活动状态.
同时对于以及pending或者firing的告警,Prometheus也会将它们存储到时间序列ALERTS{}中.
可以通过表达式,查询告警实例:
AlERTS{}
样本值为1表示当前告警处于活动状态(pending或者firing),当告警从活动状态转换为非活动状态时样本值为0
测试告警规则
在主机上运行以下命令
docker stop node-exporter
Prometheus首次检测到满足触发条件后,由于告警规则中设置了1分钟(for: 1m)的等待时间,告警状态由INACTIVE变为Pending,如下图所示:
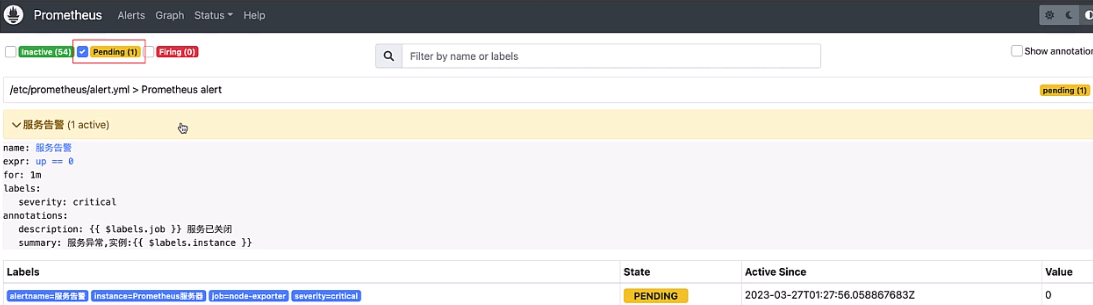
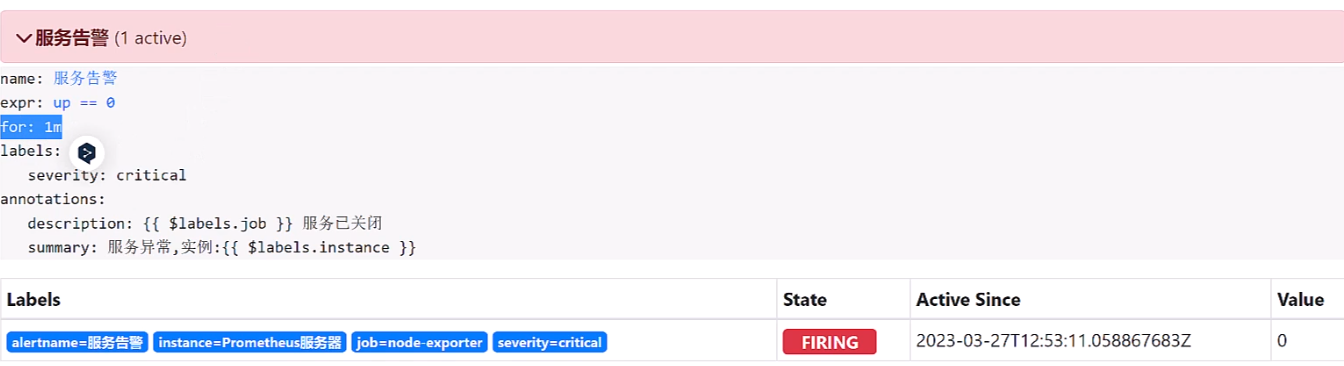
如果1分钟后告警条件持续满足,告警转台从Pending变为FIRING,并且会把告警信息发送给Alertmanager.如下图所示:
这篇关于Prometheus实战篇:Alertmanager配置概述及告警规则的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








