本文主要是介绍坑记(HttpInputMessage),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、背景知识
public interface HttpInputMessage
extends HttpMessage
Represents an HTTP input message, consisting of headers and a readable body.Typically implemented by an HTTP request on the server-side, or a response on the client-side.Since:
3.0
Author:
Arjen Poutsma
在实现接口的加密处理过程中, 我们一般选择使用SpringMVC的ResponseBody和RequestBody,实现接口报文的监听和处理操作。在监听时,需分别实现相关的Advice类,以帮助完成自己的逻辑实现。交互流程图可以参考:
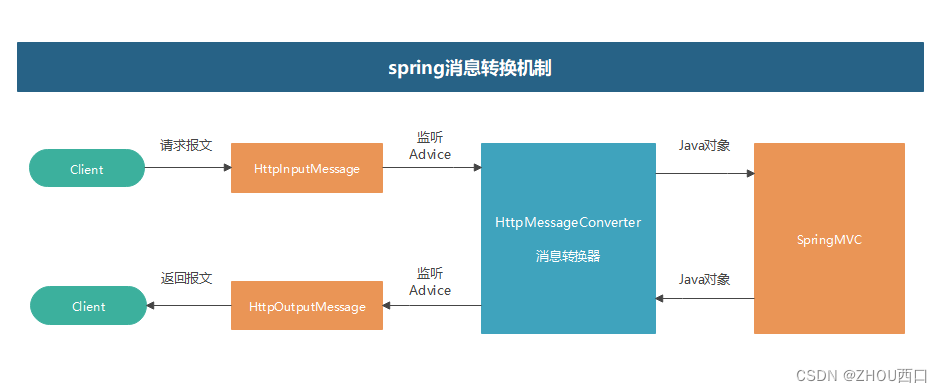
而HttpInputMessage正是我们需要获取header和请求body的关键。今天我们谈谈使用过程中可能遇到的问题。
二、情况说明
1. 问题描述
我们在实现RequestBodyAdvice时,通常会重写以下方法:
public HttpInputMessage beforeBodyRead(final HttpInputMessage inputMessage, MethodParameter parameter, Type targetType, Class<? extends HttpMessageConverter<?>> converterType) throws IOException {//读取请求bodybyte[] body = new byte[inputMessage.getBody().available()];inputMessage.getBody().read(body);
}
如我们使用以上方式,读取请求报文数据时,可能产生“读不完整”的现象。因为InputStream .available()方法描述如下:
public abstract class InputStream implements Closeable {
/*** Returns an estimate of the number of bytes that can be read (or* skipped over) from this input stream without blocking by the next* invocation of a method for this input stream. The next invocation* might be the same thread or another thread. A single read or skip of this* many bytes will not block, but may read or skip fewer bytes.** <p> Note that while some implementations of {@code InputStream} will return* the total number of bytes in the stream, many will not. It is* never correct to use the return value of this method to allocate* a buffer intended to hold all data in this stream.** <p> A subclass' implementation of this method may choose to throw an* {@link IOException} if this input stream has been closed by* invoking the {@link #close()} method.** <p> The {@code available} method for class {@code InputStream} always* returns {@code 0}.** <p> This method should be overridden by subclasses.** @return an estimate of the number of bytes that can be read (or skipped* over) from this input stream without blocking or {@code 0} when* it reaches the end of the input stream.* @exception IOException if an I/O error occurs.*/public int available() throws IOException {return 0;}
}
其中,有一句描述:
many bytes will not block, but may read or skip fewer bytes.
这就厉害了,不阻塞,但是可能丢包…所以如果使用上述方法,读取请求body时,数据并不完整,会导致后续逻辑出现异常。
2. 解决过程
上述方法有问题,可使用这个办法:
String reqBody = StreamUtils.copyToString(inputMessage.getBody(), Charset.defaultCharset());
亲测有效哦~
结束语
多看、多学、多试,总会找到解决的办法和途径。
这篇关于坑记(HttpInputMessage)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!