本文主要是介绍【命运只会眷顾努力的人六】原来正则表达式这么简单(先看懂再应用),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
 生命不息,奋斗不止!(送给也曾迷茫的你)
生命不息,奋斗不止!(送给也曾迷茫的你)
目録
- 1. 正则表达式
- 2. 修饰符
- 3. 元字符
- 4. 限定符
- 5. 集合
- 6. 转义字符
- 7. 零宽断言
- 【每日一面】
- 正则表达式中 ( ) 、[ ] 、{ } 的区别
1. 正则表达式
Regex (Regular Expression)是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符(元字符)、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。是一种文本模式,描述在搜索文本时要匹配的一个或多个字符串。
- 常用表达式
| 用途 | 正则表达式 | 实例 |
|---|---|---|
| 正整数 | [1-9]\d* | 20 |
| 负整数 | -[1-9]\d* | -20 |
| 浮点数 | (-?\d+)(\.\d+)?$ 或 ^-?([1-9]\d*\.\d*|0\.\d*[1-9]\d*|0?\.0+|0) | 20.21 |
| 中国邮政编码 | [1-9]\d{5}(?!\d) | 100001 |
| 邮箱 | \w[-\w.+]*@([A-Za-z0-9][-A-Za-z0-9]+\.)+[A-Za-z]{2,14} | ITGodRoad@gmail.com |
| 帐号是否合法 | ^[a-zA-Z][a-zA-Z0-9_]{4,15}$ | ITGodRoad |
| 中文 | [\u4e00-\u9fa5]+ | 常用正则表达式 |
| 双字节字符(包含汉字) | [^\x00-\xff]+ | 常用正则表达式 |
| 时间(时:分:秒) | ([01]?\d|2[0-3]):[0-5]?\d:[0-5]?\d | 9:51:23 |
| 月份(12) | (0?[1-9]|1[0-2]) | 02 |
| 天数(31) | ((0?[1-9])|((1|2)[0-9])|30|31) | 20 |
| 日期(年-月-日) | (([0-9]{3}[1-9]|[0-9]{2}[1-9][0-9]{1}|[0-9]{1}[1-9][0-9]{2}|[1-9][0-9]{3})-(((0[13578]|1[02])-(0[1-9]|[12][0-9]|3[01]))|((0[469]|11)-(0[1-9]|[12][0-9]|30))|(02-(0[1-9]|[1][0-9]|2[0-8]))))|((([0-9]{2})(0[48]|[2468][048]|[13579][26])|((0[48]|[2468][048]|[3579][26])00))-02-29) | 2021-02-20 |
| 域名 | [a-zA-Z0-9][-a-zA-Z0-9]{0,62}(\.[a-zA-Z0-9][-a-zA-Z0-9]{0,62})+\.? | www.csdn.net |
| IP(IPV4) | ((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})(\.((2(5[0-5]|[0-4]\d))|[0-1]?\d{1,2})){3} | 127.0.0.1 |
| xml文件 | ([a-zA-Z]+-?)+[a-zA-Z0-9]+\\.[x|X][m|M][l|L] | ITGodRoad.xml |
| HTML标记 | <(\S*?)[^>]*>.*?|<.*? /> | <p> |
2. 修饰符
| 修饰符 | 含义 | 描述 |
|---|---|---|
| i | ignore - 忽略大小写 | 搜索时不区分大小写: A 和 a 没有区别 |
| g | global - 全局匹配 | 查找所有的匹配项,默认只搜索单个匹配 |
| m | multiline - 多行匹配 | 使边界字符 ^ 和 $ 匹配每一行的开头和结尾,而不是整个字符串的开头和结尾 |
| s | singleline(dotall) - 圆点匹配 | 默认情况下的圆点.是匹配除换行符 \n 之外的任何字符,加上 s 修饰符之后.中包含换行符 \n。 |
| u | unicode - 编码匹配 | 可以使用\x{FFFFF}形式的扩展unicode转义 |
| y | sticky - 粘性匹配 | 仅从正则表达式的lastIndex只读属性表示的索引处搜索,指定y会自动忽略g |
- 在线验证
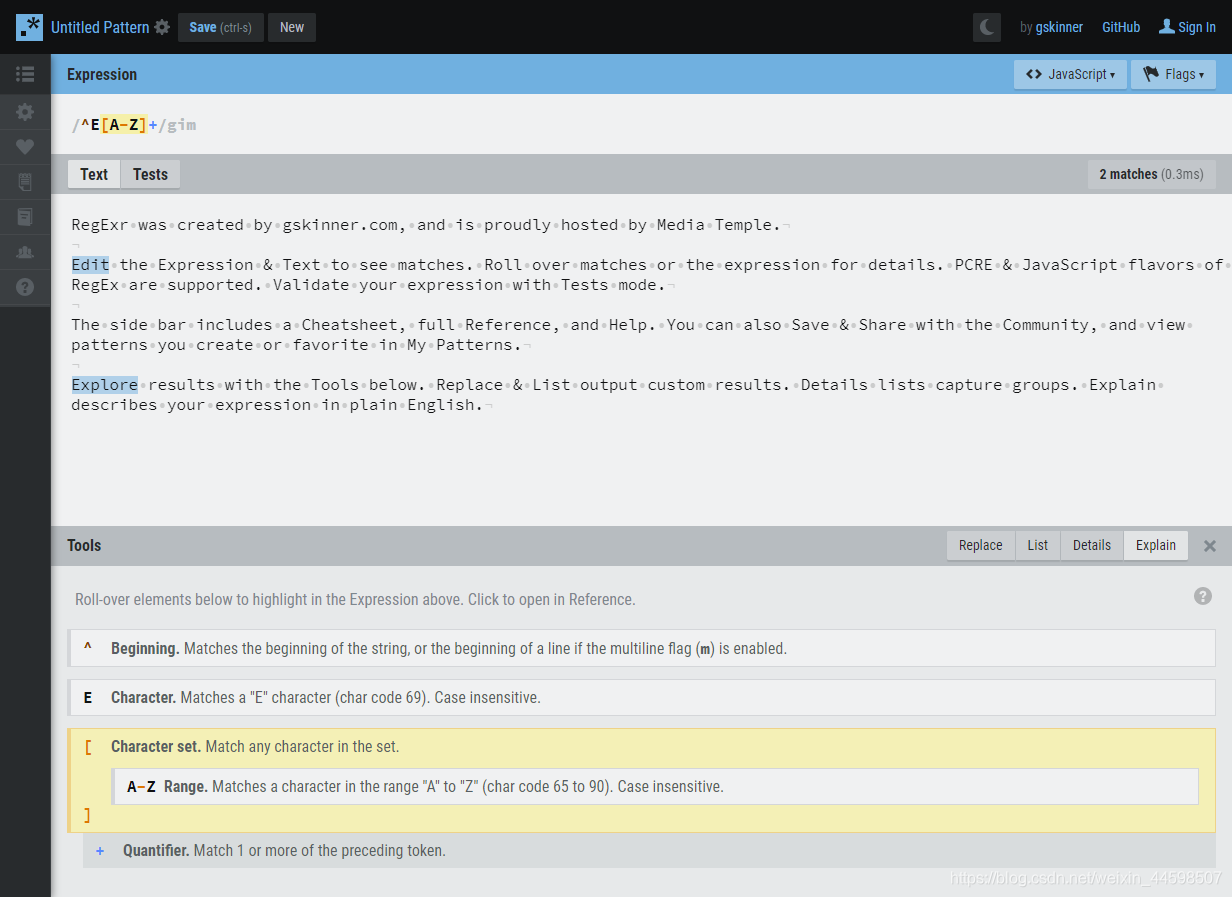
正则匹配开头为E的单词,全局多行不区分大小写搜索
3. 元字符
| 元字符 | 描述 |
|---|---|
| \ | 转义字符,’\n’,’\r’ 匹配一个换行。 |
. | 单个字符,匹配除 ‘\n’,’\r’ 之外的任意一个字符 |
| ^ | 从开始位置匹配,如果指定修饰符m,也匹配 ‘\n’ 或 ‘\r’ 之后的位置(集合中表示非匹配) |
| $ | 从结束位置匹配,如果指定修饰符m,也匹配 ‘\n’ 或 ‘\r’ 之后的位置(同时指定开头和结尾匹配为精确查找) |
| | “或”,指明两项之间的一个选择 |
| ( ) | 标记一个子表达式的开始和结束位置 |
| [ ] | 标记一个集合的开始和结束位置 |
| { } | 标记一个限定符的开始和结束位置 |
4. 限定符
| 限定符 | 描述 |
|---|---|
| * | 表达式零次或多次。zo* 能匹配 “z” 以及 “zoo”,等价于{0,} |
| + | 表达式一次或多次。zo+ 能匹配 “zo” 以及 “zoo”,等价于{1,} |
| ? | 表达式零次或一次(可选项)。“do(es)?” 可以匹配 “do” 或 “does”,等价于 {0,1} |
| {n} | 非负整数,匹配确定的 n 次。‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o |
| {n,} | 非负整数,至少匹配 n 次。‘o{2}’ 不能匹配 “Bob” 中的 ‘o’,但是能匹配 “food” 中的两个 o |
| {n,m} | 均为非负整数,n <= 匹配次数 <=m 。“o{1,3}” 将匹配 “fooooood” 中的前三个 o |
5. 集合
| 集合 | 描述 |
|---|---|
[xyz] | 字符集合,'[abc]' 可以匹配 “plain” 中的 ‘a’ |
[^xyz] | 非字符集合,'[^abc]' 可以匹配 “plain” 中的’p’、‘l’、‘i’、‘n’ |
[a-z] | 字符范围,'[a-z]' 可以匹配 ‘a’ 到 ‘z’ 范围内的任意小写字母字符 |
[^a-z] | 非字符范围,'[^a-z]' 可以匹配任何不在 ‘a’ 到 ‘z’ 范围内的任意字符 |
[0-9] | 数字范围,'[0-9]' 可以匹配 ‘0’ 到 ‘9’ 范围内的任意数字字符 |
[^0-9] | 非数字范围,'[^0-9]' 可以匹配任何不在 ‘0’ 到 ‘9’ 范围内的任意字符 |
6. 转义字符
[\s\S]表示匹配所有
‘(.)\1’ 匹配两个连续的相同字符
| 转义字符 | 描述 |
|---|---|
| \cx | 匹配由x指明的控制字符。 \cM 匹配一个 Control-M 或回车符。x 的值必须为 A-Z 或 a-z 之一。否则,将 c 视为一个原义的 ‘c’ 字符 |
| \f | 匹配一个换页符,等价于 \x0c 和 \cL |
| \n | 匹配一个换行符,等价于 \x0a 和 \cJ |
| \r | 匹配一个回车符,等价于 \x0d 和 \cM |
| \t | 匹配一个制表符,等价于 \x09 和 \cI |
| \v | 匹配一个垂直制表符,等价于 \x0b 和 \cK |
| \b | 匹配一个单词边界,即字与空格间的位置 |
| \B | 非单词边界匹配 |
| \d | 匹配一个数字字符。等价于 [0-9] |
| \D | 匹配一个非数字字符。等价于 [^0-9] |
| \s | 匹配所有空白符,包括换行等字符,等价于 [\f\n\r\t\v] |
| \S | 匹配所有非空白符,等价于 [^ \f\n\r\t\v] |
| \w | 匹配字母、数字、下划线,等价于 [A-Za-z0-9_] |
| \W | 匹配非字母、数字、下划线,等价于 [^A-Za-z0-9_] |
| \xn | 匹配十六进制数,’\x41’ 匹配 “A” |
| \n | 匹配八进制数,如果 \n 之前至少 n 个获取的子表达式,则 n 为向后引用 |
| \un | 匹配Unicode字符, \u00A9 匹配版权符号 (?) |
7. 零宽断言
Assert 用于查找在某些内容之前或之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言),它们只匹配某些位置,在匹配过程中,不占用字符,所以被称为"零宽"。
在正则表达式中断言分为先行和后行:
先行断言,是当扫描指针位于某处时,引擎会尝试匹配指针还未扫过的字符,先于指针到达该字符,故称为先行;
后行断言,引擎会尝试匹配指针已扫过的字符,后于指针到达该字符,故称为后行。但后行断言的表达式必须是定长的,因为要确定要回溯多少步。
| 断言 | 说明 |
|---|---|
| ( ? = pattern ) | 零宽正向先行断言(zero-width positive lookahead assertion) |
| ( ? ! pattern ) | 零宽负向先行断言(zero-width negative lookahead assertion) |
| ( ? < = pattern ) | 零宽正向后行断言(zero-width positive lookbehind assertion) |
| ( ? < ! pattern ) | 零宽负向后行断言(zero-width negative lookbehind assertion) |
-
零宽正向先行断言示例
例如对 “a regular expression” 这个字符串,要想匹配 regular 中的 re,但不能匹配 expression 中的 re,可以用 re(?=gular),该表达式限定了 re 右边的位置,这个位置之后是 gular,但并不消耗 gular 这些字符。

将表达式改为 re(?=gular).,将会匹配 reg,元字符 . 匹配了 g。

-
零宽负向先行断言示例
例如对 “regex represents regular expression” 这个字符串,要想匹配除 regex 和 regular 之外的 re,可以用 re(?!g),该表达式限定了 re 右边的位置,这个位置后面不是字符 g。

-
零宽正向后行断言示例
例如对 regex represents regular expression 这个字符串,有 4 个单词,要想匹配单词内部的 re,但不匹配单词开头的 re,可以用 (?<=\w)re,单词内部的 re,在 re 前面应该是一个单词字符。

-
零宽负向后行断言示例
例如对 “regex represents regular expression” 这个字符串,要想匹配单词开头的 re,可以用 (?<!\w)re。单词开头的 re,在本例中,也就是指不在单词内部的 re,即 re 前面不是单词字符。当然也可以用 \bre 来匹配。

【每日一面】
正则表达式中 ( ) 、[ ] 、{ } 的区别
( ):内的内容表示的是一个子表达式,( ) 本身不匹配任何东西,也不限制匹配任何东西,只是把括号内的内容作为同一个表达式来处理,例如 (ab){1,3},就表示 ab 一起连续出现最少 1 次,最多 3 次。如果没有括号的话,ab{1,3} 就表示 a,后面紧跟的 b 出现最少 1 次,最多 3 次。
[ ]:表示匹配的字符在 [ ] 中,并且只能出现一次,并且特殊字符写在 [ ] 会被当成普通字符来匹配。例如 [(a)],会匹配 “(”、“a”、")"、这三个字符。
{ }:匹配次数,匹配在它之前表达式匹配出来的元素出现的次数,{n}出现n次、{n,}匹配最少出现n次、{n,m}匹配最少出现n次,最多出现m次。
( ) 是子表达式,是一个整体;[ ] 是集合,匹配字符组内的字符;{ } 是限定符,限定匹配的次数
这篇关于【命运只会眷顾努力的人六】原来正则表达式这么简单(先看懂再应用)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



