本文主要是介绍超大规模企业的经验教训:对象存储如何推动下一波托管服务的成功浪潮,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

在过去的几个月里,我们看到基于对象存储的超快速分析数据库的托管服务有所增加。随着企业意识到将闪电般快速的数据准备与对象存储相结合的战略优势,尤其是对于 AI 和 ML 应用程序,这些托管服务越来越受欢迎,吸引了人们的兴趣和工作负载。
MotherDuck 和 ClickHouse 的托管服务 ClickHouse Cloud 的成功就是这一趋势的例证。两者都利用对象存储在性能和成本节约方面获得战略优势。MotherDuck 入围 2023 年 GeekWire 奖年度最佳交易奖,在 B 轮融资中筹集了 5250 万美元,使其总融资额达到 1 亿美元。同样,ClickHouse在2021年筹集了2.5亿美元的B轮融资,并于最近宣布与阿里云在中国大陆建立重要的合作伙伴关系。
这些托管服务成功的核心是存储和计算的解耦,这是通过在对象存储之上构建数据产品来实现的。我们将看到越来越多的托管服务使用这种确切的架构构建,因为这种模型允许存储和计算独立扩展,从而有效地为每个服务解锁无限和特定于工作负载的规模。
超大规模企业正在这些托管服务中利用这种架构,但分离存储和计算的好处并非他们独有。一旦云被识别为运营模式而不是物理位置,规模和性能都可以在超大规模之外实现。随着 AI 和 ML 模型对干净、快速和准确数据的永不满足的需求不断增长,我们必须从这些超大规模提供商那里吸取教训,并了解对象存储如何帮助他们取得成功。
分解成功:ClickHouse Cloud的经验教训
ClickHouse长期以来一直承认其用户在私有托管的高性能对象存储(如MinIO)上为其开源产品体验到的卓越吞吐量。他们的产品ClickHouse Cloud提供了该产品的托管服务版本。
由于实现了 SharedMergeTree 引擎,ClickHouse Cloud 速度很快。SharedMergeTree 表引擎通过利用多个 I/O 线程访问对象存储数据并异步预取数据,从服务器中分解数据和元数据。
此外,ClickHouse 对这两种产品的固有设计有助于提高其速度。ClickHouse对数据进行列处理,从而提高CPU缓存利用率,并允许使用SIMD CPU指令。ClickHouse可以利用所有可用的CPU内核和磁盘来执行查询,不仅在单个服务器上,而且在整个集群上。这些架构选择与矢量化查询执行相结合,有助于 ClickHouse 的卓越性能。
释放 MotherDuck 的潜力:基于 DuckDB 的云分析服务
MotherDuck 是基于开源 DuckDB 构建的托管云服务。DuckDB 之所以如此快速,有几个关键因素,其中一些我们已经描述过了。特别值得注意的是,DuckDB 利用了列式存储和矢量化查询执行。与传统的基于行的数据库相比,这种方法使 DuckDB 能够更有效地处理数据,特别是对于分析工作负载,例如在为 ML 模型选择特征之前进行数据探索。
DuckDB 的性能不仅仅是一个要求;它在测试中展示了它的速度,优于 Postgres 等系统,尤其是对于中等大小的数据集。DuckDB 的与众不同之处在于它对简单性的承诺。它不吹嘘复杂的功能,而是专注于提供一种快速直接的方式来访问和分析数据。
分类案例研究
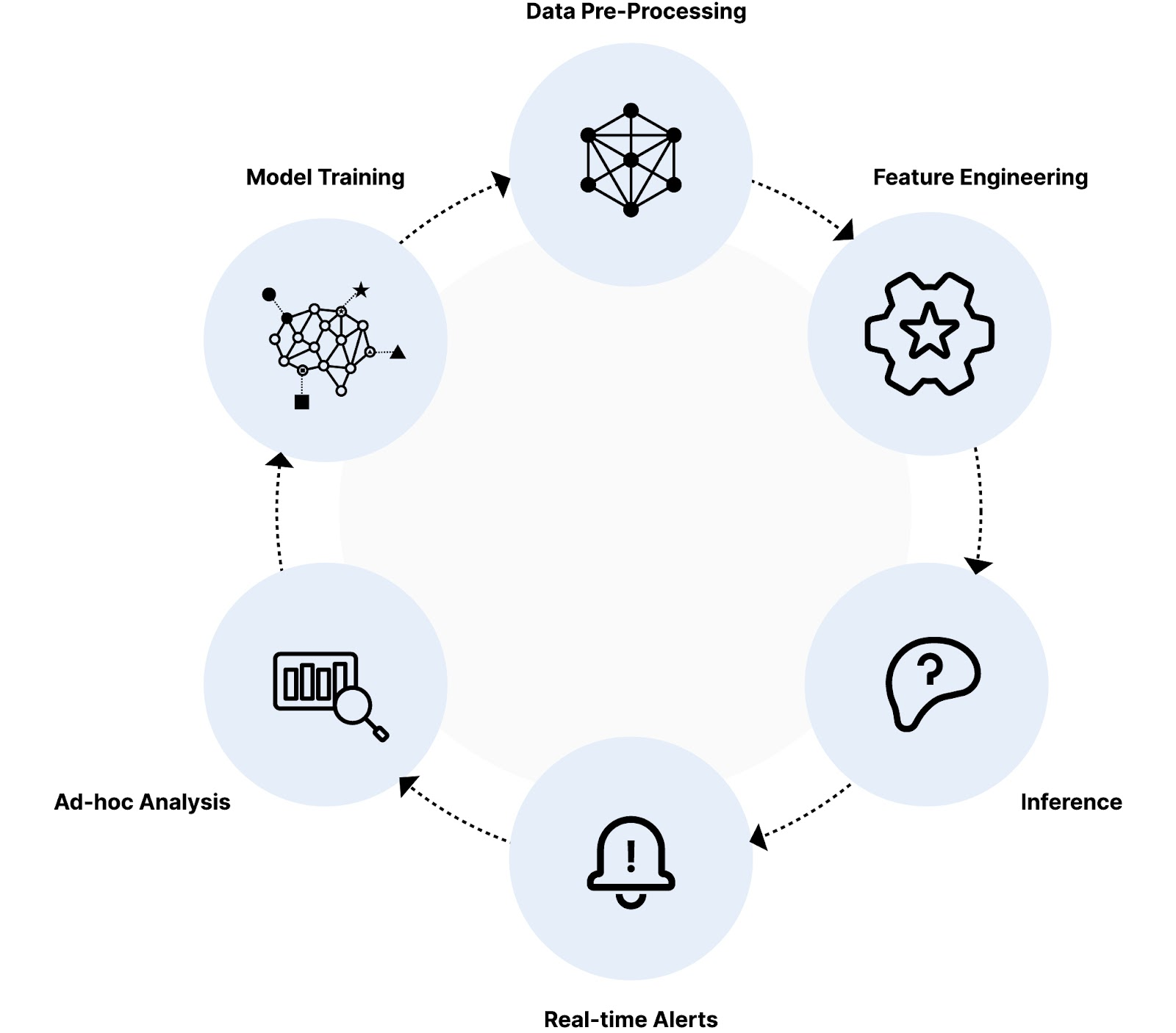
让我们将此体系结构应用于案例。 一家大型网上银行每天要进行数百万笔交易。每秒钟,数据对象都会被创建并淹没其系统,其中可能潜伏着欺诈活动。为了捕捉这些威胁,这家大型银行需要一个强大的人工智能系统来分析这些数据并标记可疑记录。这就是一个非常快速、可扩展的数据库变得至关重要的地方。
其工作原理如下:
-
数据预处理:分析数据库可以直接在对象存储中查询数据,无需引入并实时进行预处理。此预处理可能涉及数据清理、转换和特征提取。
-
特征工程:数据库存储并允许快速计算每个事务的各种特征。这些功能可能包括交易金额、位置、一天中的时间、用户行为模式和使用的设备等内容。目标是通过将所有内容转换为少量数字,使模型在训练和推理期间可以使用特征。
-
推理:人工智能模型根据历史数据和欺诈模式进行训练,实时分析每笔交易的特征。数据库需要支持对相关数据的高效查询和检索,以便模型快速准确地对每笔交易进行评分。
-
实时警报:根据异常分数,人工智能系统标记可疑交易。数据库需要有效地存储和更新这些信息,以便立即向欺诈团队发出警报以进行调查。
-
临时分析:分析数据库允许使用各种工具(如仪表板、可视化和异常检测算法)探索和调查可疑交易。人类应该保持警惕,以确保标记为欺诈的交易是欺诈性的,并且对于人工智能模型错过的任何交易。在这两种情况下,都需要一个非常快速的分析数据库,以确保快速完成,并且可以从这些数据中快速生成新的更好的模型。
-
模型训练:此 AI 模型将持续保留。许多工件(包括模型本身和每个训练周期)都需要保存到对象存储中。
实施人工智能驱动的欺诈检测系统为银行带来了多项好处。它可以帮助他们及早发现和阻止欺诈易,减少经济损失。这不仅保护了银行,还确保了客户有更好的体验,因为他们知道他们的账户是安全的。人工智能系统不断学习和适应新的欺诈模式,使银行的安全性随着时间的推移而增强。此外,该系统可以在不减速的情况下处理更多交易,从而支持银行未来的增长。
为您自己的工作负载获得此体系结构的优势
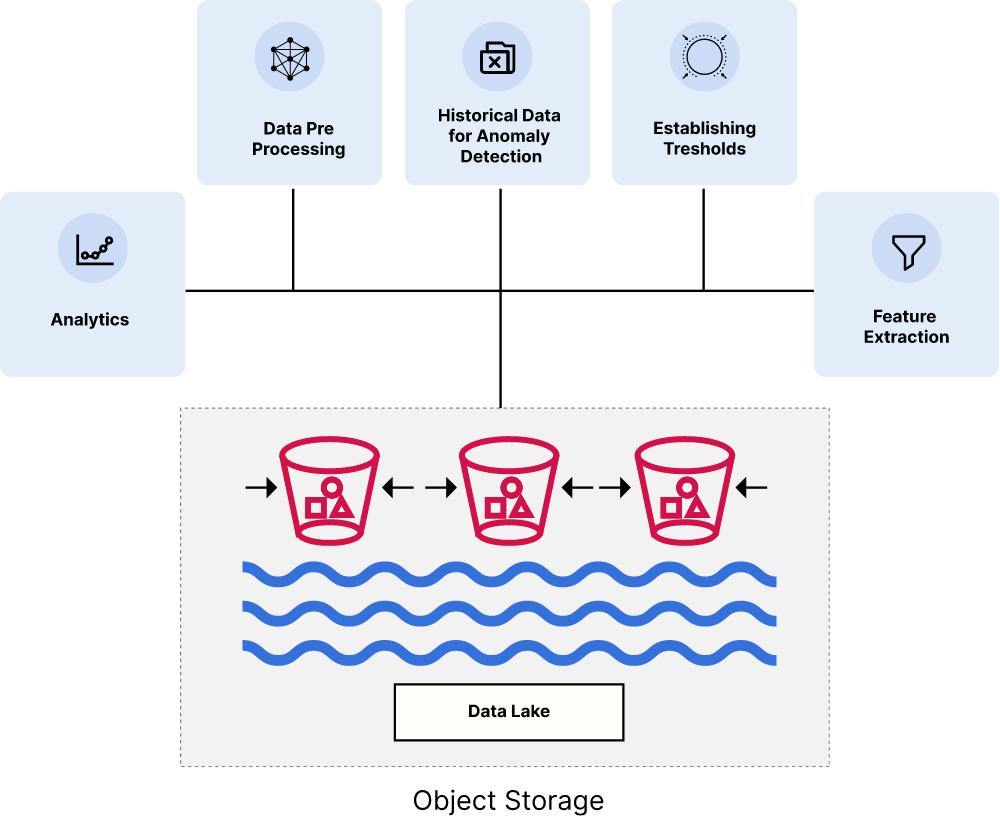
让我们深入了解如何实现分解存储和计算数据湖架构,以实现工作负载的规模和性能。您的主要目标必须是选择设计为可扩展和云原生的对象存储。以下是满足该标准的要求:
-
可扩展性和弹性:云原生设计和对 Kubernetes 编排的支持以实现无缝的可扩展性和弹性是绝对必要的。
-
存储效率和弹性:每个对象、内联纠删码和 bitrot 检测以现代方式确保数据保护,以保护数据的完整性。
-
云原生和 REST API 兼容:您必须能够随时随地使用广泛采用的相同 API 访问数据。这为数据湖架构提供了灵活性和可访问性,并支持系统之间的互操作性。
-
安全性和合规性:需要复杂的服务器端加密方案来保护动态和静态数据,确保数据安全并符合数据保护法规。
-
即插即用:必须与现代数据堆栈的所有其他元素配合使用。Kubeflow 和 MLFlow 只附带一个对象存储。
为什么要私有构建
我们已经确定云是一种运营模式,而不仅仅是一个物理位置。数据无处不在,无论是在公共云还是私有云上,在边缘,在colos,在数据中心,在世界各地的裸机上。这种云方法提供了自由度并避免了供应商锁定,使组织能够保持对其工作负载的控制和利用。
为成功而生
基于对象存储的超快速分析数据库的兴起不仅引起了广泛关注,而且已成为企业深入研究 AI 和 ML 应用程序的战略要务。MotherDuck 和 ClickHouse Cloud 的成功案例凸显了对象存储在实现性能和成本效益方面的关键作用。这些经验教训将推动越来越多的托管服务进入这一领域,同时也为企业提供了机会,通过在任何地方使用高性能对象存储构建数据湖仓一体来实现自己的成功。
这篇关于超大规模企业的经验教训:对象存储如何推动下一波托管服务的成功浪潮的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



