本文主要是介绍ubuntu 20.04下 Tesla P100加速卡使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.系统环境:系统ubuntu 20.04, python 3.8
2.查看cuDNN/CUDA与tensorflow的版本关系如下:
Build from source | TensorFlow

从上图可以看出,python3.8 对应的tensorflow/cuDNN/CUDA版本。
3.安装tensorflow
#pip3 install tensorflow
新版本tensorflow不用额外指定tensorflow gpu版本,默认安装的是tensorflow 2.13版本
4.安装Tesla P100 driver
Ubuntu 下执行 $ubuntu-drivers devices
可以看到系统支持的P100 driver情况,这里安装推荐的nvidia-driver-535
$sudo apt install nvidia-driver-535

安装完成后可以使用$nvidai-smi命令查看到显卡设备
5.安装CUDA
从https://developer.nvidia.com/cuda-toolkit-archive 下载cuda 11.8
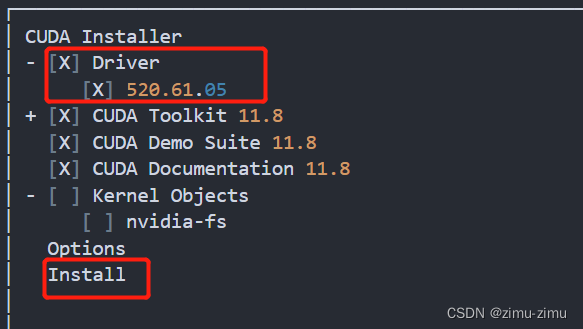
执行安装文件,因为前面已经安装过了driver,这里去掉选择Driver(尝试过不安装前面第四步的driver而在CUDA安装时再安装driver,会提示driver安装失败)。然后直接选择install
添加环境变量到~/.bashrc
export PATH=/usr/local/cuda-11.8/bin${PATH:+:${PATH}}
export LD_LIBRARY_PATH=/usr/local/cuda/lib64:/usr/local/cuda-11.8/lib64:/usr/local/cuda/extras/CUPTI/lib64:$LD_LIBRARY_PATH
export CUDA_HOME=/usr/local/cuda
7.安装cuDNN
从 CUDA Deep Neural Network (cuDNN) | NVIDIA Developer 下载cuDNN 8.6,下载完后解压,拷贝相应文件到CUDA目录:
$ sudo cp include/* /usr/local/cuda/include
$ sudo cp cuda/lib64/* /usr/local/cuda/lib64
8.解决tensorflow "could not load library libcublasLt.so.10"、"could not load library libcublas.so.10"问题
运行tensorflow时提示上面的问题,解决方法: 进入目录:/usr/local/cuda/targets/x86_64-linux/lib,建立两个链接文件
$ln -s libcublasLt.so.11 libcublasLt.so.10
$ln -s libcublas.so.11 libcublas.so.10
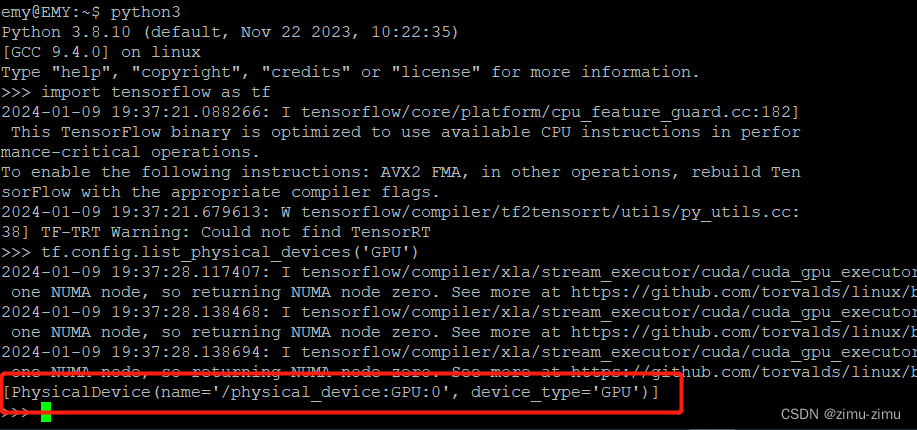
使用tensorflow查看显卡是否安装正常
$import tensorflow as tf
$tf.config.list_physical_devices('GPU')
参考:
Linux系统下安装TensorFlow的GPU版本 | AI柠檬
这篇关于ubuntu 20.04下 Tesla P100加速卡使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




