本文主要是介绍Redis面试文章观后,持续更新知识中,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
https://zhuanlan.zhihu.com/p/32540678?utm_source=wechat_session&utm_medium=social&from=singlemessage
Geo比较简单,直接看api即可
布隆过滤器仔细看了一遍
主要是这4方面 即BloomFilter的以下参数:
- m 位数组的长度
- n 加入其中元素的数量
- k 哈希函数的个数
- f False Positive 可以理解为误识别率
但是Redis String最大量为512M,最大值为,如果超过超过这个量了怎么办呢,分散计算,通过bitmap的进行hash分块。
https://redis.io/topics/data-types-intro
布隆过滤器Java实现https://github.com/MagnusS/Java-BloomFilter
布隆过滤器Redis实现https://github.com/olylakers/RedisBloomFilter
Redis在实现字典时用到了两种不同的哈希算法,MurmurHash便是其中一种(另一种是djb)
优点:规律性较强的key,MurmurHash的随机分布特征表现更良好
适用范围:是一种非加密型哈希函数,适用于一般的哈希检索操作。
Redis与数据库事务的区别
Redis的事务是这样的
multi
命令1
命令2
命令3
exec如果命令2失败,仍然会提交,也就是发现命令执行出现问题了,不能自动回滚,而要手动通过程序回滚。
还有一点关于watch,watch可以对3个命令的key进行监控,如果key的value改变,那么此次事务失败,对key的监控取消。
keys指令与scan指令的区别
keys指令是阻塞指令,可能服务卡顿, 结果准确
scan指令是无阻塞指令,不影响服务使用,结果不准确,可能有重复。
Redis 发布订阅 与MQ的局别
1.Redis的发布订阅无法消费离线的数据,而MQ通过消息持久化是可以的。
2.Redis没有ack的功能
关于Redis的队列
rpush生产消息,lpop消费消息。
lpush生产消息,rpop消费消息。
redis list源码 http://zhangtielei.com/posts/blog-redis-quicklist.html
Redis优先级队列实现
可以通过两种方式来实现,List或者Sorted Set。
List方式适用于优先级类型比较有限的情况,就是用穷举法生产多个优先级List,然后从高到低循环取List的数据。
Sorted Set方式对于优先级类型没有限制,多少均可,但是性能呢,感觉要稍差一些了,代码如下,稍后给出性能测试,
Jedis jedis = pool.getResource(); System.out.println("begin");try {Pipeline pl=jedis.pipelined();String key="Priority";pl.del(key);for(int i=0;i<10;i++){pl.zadd(key, 0.1d, "member"+i);}for(int i=10;i<20;i++){pl.zadd(key, i+0.1d, "member"+i);}Response<Set<String>> res=pl.zrevrange(key, 0, 0);pl.sync();Set<String> result=res.get();String member=null;if(!result.isEmpty()){Iterator it=result.iterator();member=it.next().toString();}System.out.println(member);pl.zrem(key, member);pl.sync();System.out.println("end");} catch (Exception e) {e.printStackTrace();}finally{if(jedis!=null){pool.returnResource(jedis);}}menber为10个字符 10万级别 14毫秒
100万级别 76毫秒
1000万级别 我的客户端挂了...
redis锁与zk锁对比 http://blog.csdn.net/pzqingchong/article/details/52516602
运维如何进行慢查询排查
检查慢查询配置
config get slowlog-log-slower-than
config get slowlog-max-len
config set slowlog-log-slower-than 1000 (单位毫秒,1000毫秒即1微秒,)
config rewrite
查询慢查询列表长度
slowlog len
查看慢查询日志
slowlog get
redis4版本的日志有变化,3.x的版本中有4个字段 标识id、发生时间戳、命令耗时、执行命令和参数;4中加入了client的ip和端口、客户端名称。详见https://redis.io/commands/slowlog
tcp-backlog:TCP三次握手后,会将接受的连接放入队列中,tcpbacklog
就是队列的大小,它在Redis中的默认值是511。如果/proc/sys/net/core/somaxconn小于tcp-backlog,那么在Redis启动时会
看到如下日志,并建议将/proc/sys/net/core/somaxconn设置更大
echo 511 > /proc/sys/net/core/somaxconn

config set client-output-buffer-limit "normal 1048576 1048576 60 slave 268435456 67108864 60 pubsub 33554432 8388608 60"找到omem非零的客户端连接:
redis-cli client list | grep -v "omem=0"./redis-cli -h 192.168.112.133 -p 6379 client list | grep -v "omem=0"
RDB
SAVE 阻塞当前Redis服务器,线上环境不建议使用。
BGSAVE Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
执行lastsave命令可以获取最后一次生成RDB的时间,对应info统计的rdb_last_save_time选项。需要设置sysctl vm.overcommit_memory=1允许内核可以分配所有的物理内存,防止Redis进程执行fork时因系统剩余内存不足而失败。
Redis的内存上限可以通过config set maxmemory进行动态修改共享对象池与maxmemory+LRU策略冲突,使用时需要注意。对于ziplist编码的值对象,即使内部数据为整数也无法使用共享对象池,因为ziplist使用压缩且内存连续的结构,对象共享判断成本过高,ziplist编码细节后面内容详细说明。
低一致性业务建议配置最大内存和淘汰策略的方式使用。
高一致性业务可以结合使用超时剔除和主动更新,这样即使主动更新
出了问题,也能保证数据过期时间后删除脏数据。
bigkey问题
Redis将在4.0版本支持lazy delete free的模式,
UNLINK命令,此命令是一个非阻塞命令。
Redis过期数据删除策略
定期删除为主动删除:Redis会定期主动淘汰一批已过去的key
惰性删除为被动删除:用到的时候才会去检验key是不是已过期,过期就删除
惰性删除为redis服务器内置策略,key过期的时候不删除,每次从数据库获取key的时候去检查是否过期,若过期,则删除,返回null。
定期删除可以通过:
第一、配置redis.conf 的hz选项,默认为10 (即1秒执行10次,100ms一次,值越大说明刷新频率越快,最Redis性能损耗也越大)
第二、配置redis.conf的maxmemory最大值,当已用内存超过maxmemory限定时,就会触发主动清理策略
自己碰到的redis 主从同步失效的问题
原有情况是节前启动了3个redis节点,1个master2个slave节点,3个Sentinel node,节后发现
1.master原来ip为15变成了slave节点,而且状态是down的状态
2.使用slave of none和slave of 16后命令提示已经连接到ip为16的节点上,但是执行sync提示同步失败
3.在16上执行client list命令找不到15的client
4.15节点执行ping有回应
5.16节点新增加的数据在15上没有,而17节点上存在。
本来想查log日志,发现居然没有配置.....在心里重新过一遍复制的过程
1.保存主节点(master)信息。
2.与主节点建立网络连接
3.发送ping命令
4.权限验证
5.同步数据集
6.命令持续复制
因此怀疑是权限的问题,执行 config get masterauth发现为空,执行config set masterauth 密码,成功,提示连接成功。
在16上执行client list命令看到新出现了一个15的client。
优化配置
vm.swappiness 操作系统使用swap区的倾向程度,默认为60,建议修改为1,0在linux3.5以上的版本意味着OOM KILLER也不使用swap区。
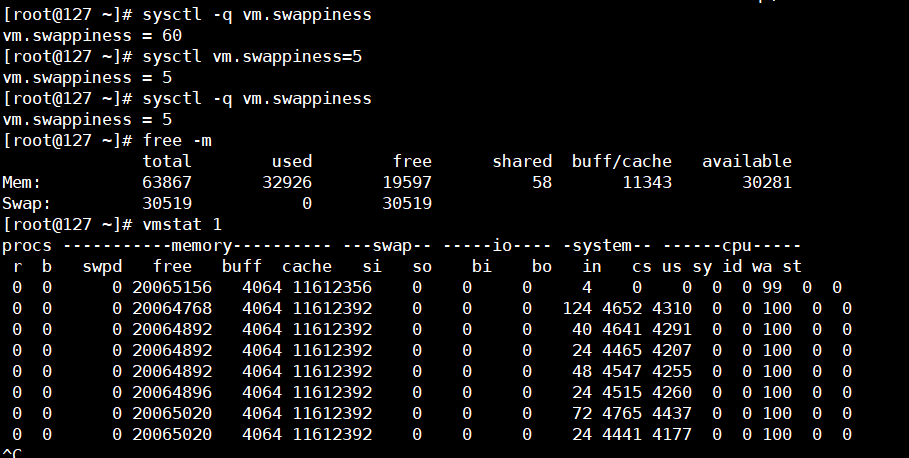
查看redis的swap区情况
redis-cli -h 10.1.8.15 -p 6379 info server | grep process_id
cat /proc/27372/smaps

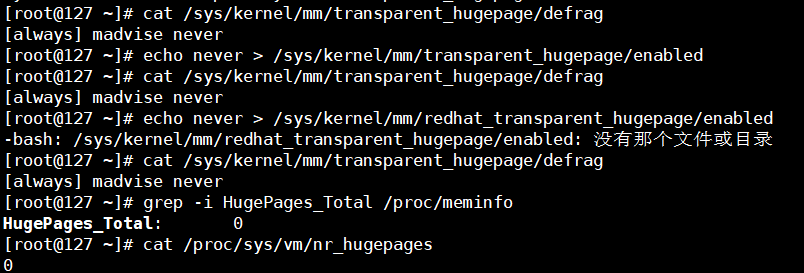
关闭THP
Transparent Huge Pages(THP)大页内存
cat /sys/kernel/mm/transparent_hugepage/defrag
echo never > /sys/kernel/mm/transparent_hugepage/enabled
grep -i HugePages_Total /proc/meminfo
cat /proc/sys/vm/nr_hugepages
查看链接
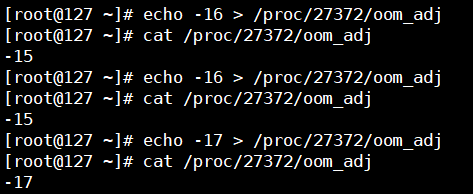
OOM killer
/proc/{progress_id}/oom_score
/proc/{progress_id}/oom_adj
echo {value} > /proc/${process_id}/oom_adj
cat /proc/{progress_id}/oom_score_adj
oom_adj介于 [-17,15]之间,越高的权重,意味着更可能被oom killer选中,-17表示禁止被kill掉。redis的默认为0,建议改小到-15,另外我发现,oom_adj的值只能为奇数。
TCP backlog
cat /proc/sys/net/core/somaxconn
echo 511 > /proc/sys/net/core/somaxconn
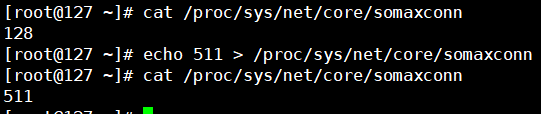
建议调大linux的值,大于等于redis对应的tcp backlog的值。
https://mp.weixin.qq.com/s?__biz=MjM5NjQ5MTI5OA==&mid=2651747704&idx=3&sn=cd76ad912729a125fd56710cb42792ba&chksm=bd12ac358a6525235f51e3937d99ea113ed45542c51bc58bb9588fa1198f34d95b7d13ae1ae2&mpshare=1&scene=23&srcid=03165gAv4AjKuRGn3FToo69J#rd
使用命令taskset可以为进程设置CPU亲缘性,操作十分简单,一句taskset -cp cpu-list pid即可完成绑定。经过一番压测,我们发现使用8个core处理中断时,流量直至打满双万兆网卡也不会出现丢包,因此决定将中断的亲缘性设置为物理机上前8个core,Redis进程的亲缘性设置为剩下的所有core。
未完待续
Lua语言
boolean numbers strings tables
这篇关于Redis面试文章观后,持续更新知识中的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





