本文主要是介绍experience,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
![]()
编程有个说法,能用组合就不用继承。说说继承的好处。
学过设计模式的都听说过,能用组合就别用继承。
- 不破坏封装,整体类与局部类之间松耦合,彼此相对独立
- 具有较好的可扩展性
- 支持动态组合。在运行时,整体对象可以选择不同类型的局部对象
- 整体类可以对局部类进行包装,封装局部类的接口,提供新的接口
缺点
- 整体类不能自动获得和局部类同样的接口(在整体类的东西全都需要暴露出去的时候)
- 创建整体类的对象时,需要创建所有局部类的对象
参考:重新认识java(四) — 组合、聚合与继承的爱恨情仇_Sharember的博客-CSDN博客
一个判断方法是,问一问自己是否需要从新类向基类进行向上转型。如果是必须的,则继承是必要的。反之则应该好好考虑是否需要继承。
![]()
htttp1.1 和2.0 的关系,区别
json rpc
kafka rabbit mq
![]()
lambda 表达式的用法
lambda 表达式的基本用法
Lambda表达式使用详解教程 - 知乎
Lambda 规定接口中只能有一个需要被实现的方法(即只能有一个抽象方法),不是规定接口中只能有一个方法,这也称之为“函数式接口”,比如:java.lang.Runnable就是一个函数式接口
jdk 8 中有另一个新特性:default, 被 default 修饰的方法会有默认实现,不是必须被实现的方法,所以不影响 Lambda 表达式的使用。
Java8 用法优雅的函数式编程与stream,看这一篇就够了!_郎涯技术的博客-CSDN博客
andThen 的用法
JAVA 8 函数式接口--Consumer - 简书
看代码就懂了
andThen 实现:default Consumer<T> andThen(Consumer<? super T> after) {Objects.requireNonNull(after);return (T t) -> { accept(t); after.accept(t); };
}示例代码:class Solution {public static void main(String[] args) {Consumer consumer = (o) -> System.out.println(0);Consumer consumer1 = (o) -> System.out.println(1);Consumer consumer2 = (o) -> System.out.println(2);Consumer consumer3 = System.out::println;consumer.andThen(consumer1).andThen(consumer2).andThen(consumer3).accept("abc");}}输出:
1
2
3
abc
java 8 的几个接口的使用
Java8新特性学习-函数式编程(Stream/Function/Optional/Consumer)
consumer 中:
有个accept 方法,无返回值
有个default 的andThen
Function 中:
有个apply() 方法,有输入,有输出
还有andThen
compose
identity
/*** Function测试*/
public static void functionTest() {Function<Integer, Integer> f = s -> s++;Function<Integer, Integer> g = s -> s * 2;/*** 下面表示在执行F时,先执行G,并且执行F时使用G的输出当作输入。* 相当于以下代码:* Integer a = g.apply(1);* System.out.println(f.apply(a));* compose: 组合*/System.out.println(f.compose(g).apply(1));/*** 表示执行F的Apply后使用其返回的值当作输入再执行G的Apply;* 相当于以下代码* Integer a = f.apply(1);* System.out.println(g.apply(a));*/System.out.println(f.andThen(g).apply(1));/*** identity方法会返回一个不进行任何处理的Function,即输出与输入值相等;* identity:身份、特点、个性*/System.out.println(Function.identity().apply("a"));
}
Predicate 中:
predicate:断言、断定。
predicate 里面有个test 方法,再结合其中的and、or、equal 那些。
![]()
stringBuilder 和String 的区别
java 中String 是final 修饰的,是不可变的。
- String 是不可变的,而 StringBuffer 和 StringBuilder 是可变类。
- StringBuffer 是线程安全和同步的,而 StringBuilder 不是。这就是 StringBuilder 比 StringBuffer 快的原因。
- 字符串连接运算符 (+) 在内部使用 StringBuilder 类。
- 对于非多线程环境中的字符串操作,我们应该使用 StringBuilder 否则使用 StringBuffer 类。
由于 String 在 Java 中是不可变的,因此每当我们执行字符串拼接操作时,它都会生成一个新的 String 并丢弃旧的 String 以进行垃圾收集。
这些重复的操作会在堆中产生大量垃圾冗余。所以 Java 提供了 StringBuffer 和 StringBuilder 类,应该用于字符串操作
参考:Java 中 String 与 StringBuffer 和 StringBuilder 的区别-阿里云开发者社区
- 堆:存放所有new 出来的对象
- 栈:存放基本数据变量和对象的引用,对象(new出来的对象)本身不存在在栈中,而是存放在堆中或者常量池中(字符串对象存放在常量池中)
- 常量池:存放基本类型常量和字符串常量
对于字符串(String是类):其对象变量都是存储在栈中的,如果是编译期已经创建好(直接用双引号定义的)的就存储在常量池中,如果是运行期(new出来的)才能确定的就存储在堆中。
Equals方法看的两个对象在常量池里面的值是否相等,“= =”方法看的是对象的引用是否相等,比如s1,s2,s3都指向常量池的“china”,那么“= =”方法返回true,ss1,ss2,ss3指向堆中不同的new对象,所以==方法返回false。对于equals相等的字符串,在常量池中永远只有一份,在堆中有多份。
String s1 = "china";
String s2 = "china";
String s3 = "china";
String ss1 = new String("china");
String ss2 = new String("china");
String ss3 = new String("china");解释一下堆指向常量池这3个箭头,对于通过new产生一个字符串(假设为”china”)时,先去常量池中查找是否已经有了”china”对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此“china”对象的拷贝对象。
这也就是有道面试题:String s = new String(“xyz”);产生几个对象?一个或两个,如果常量池中原来没有”xyz”,就是两个。
指针是ss1先指向堆里面new的引用变量,堆里面new的引用变量再指向常量池里面的“china”
对于成员变量和局部变量:局部变量必须初始化。形式参数是局部变量,局部变量的数据存在于栈内存中。栈内存中的局部变量随着方法的消失而消失。成员变量存储在堆中的对象里面,由垃圾回收器负责回收。
![]()
==,equals和hashCode()区别
= =:比较的是内存中的地址。
1. 对于基本类型:相当于比较的就是值是否相同;
2. 对于引用类型:比较的就是地址值是否相同
- Equals:用来判断两个对象的值是否相等。如果一个类没有定义自己的equals()方法,那么它默认的equals()方法就是从Object类继承的相当于==运算符,即比较两个变量指向的对象内存是否相等。如果一个类希望能比较两个实例对象的值是否相等,那么就可以覆盖Object类的equals()方法。例如String类的equals()方法就是用于比较两个独立对象的内容是否相等(即堆中的内容是否相等)。
- hashCode():Obejct类的 hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数,其实就是对象的内存地址值十进制表示。这个哈希码的作用是确定该对象在哈希表中的索引位置。在Java中任何一个对象都具备equals(Object obj)和hashCode()这两个方法,因为他们是在Object类中定义的。如果重写了一个对象的equals方法,那么它的hashcode方法也重写。
假设两个对象的equals方法返回true,那么hashCode方法也必须返回相同int数
equals方法的结果为false,那么hashCode方法返回的结果可以为相同int数也可以为不同int数。
反之,hashCode方法返回不同int数,那么equals方法一定返回false;
如果hashCode方法返回相同int数,equals方法返回的结果可以为true也可以为false
上面四句话的总结:
1. equal 返回true,hashcode 返回必定相等
2. hashcode 返回相等,equal 不一定相等
面试官:说说堆、栈和字符串常量池它们之间的关系_吴师兄学算法
java的字符串存储在堆中还是常量池中_java 字符串存在什么区域_编码大神经的博客-CSDN博客
java的字符串存储在堆中还是常量池中_java 字符串存在什么区域_编码大神经的博客-CSDN博客
如果某个类,重写了hashcode() 方法,如果这个类对象当做map 的key,对于map 会怎么样,冲突吗,链吗
Key {
@Override
hashcode() {
return 4;
}
Key key = new Key();
Key key2 = new Key();
map.put(key) map.put(key2)
![]()
另外,对于hashCode 和equal 的面试题
看似简单的hashCode和equals面试题,竟然有这么多坑!_徐刘根的博客-CSDN博客
hashcode 和equal 的存在都是为了比较两个对象是否相等一致。
两个角度对比:一个是性能,一个是可靠性。二者的区别也在这里。
1. 既然equal 已经实现了对比的功能,还要hashcode 干什么
重写的equal 里一般比较全面且复杂,这样效率就比较低;而利用hashcode 进行对比,只要生成一个hash 值进行比较就可以了,效率高。
2. hashcode 效率高,为什么还是需要equal
hashcode 不可靠,有时候不同的对象,根据hash 公式得到的值却是一样的。
hashcode 大部分的时候是可靠的,但不是绝对可靠。所以得出结论:
equal 相等,那么hashcode 一定相等;hashcode 相等,equal 不一定相等。
使用场景:
在大量且快速对比的场景中,先使用hashcode,如果不一致,再用equal。
这种场景一般存在于hash 容器中。
什么情况需要重写hashcode 和equals 方法
遵循规则:
- 两对象若equals相同,则hashCode方法返回值也得相同
- 两个对象的hashCode返回值相同二者equals不一定相同
所以说,重写equals,必须重新hashcode(因为hashCode是对堆内存的对象产生的特殊值,如果没有重写,不同对象产生的哈希值基本是不同的)
集合中判断对象是否相同,也是先判断hashcode,再判断equals
(equal 里面是判断(obj == this),即判断二者的地址是否相同)
(默认的hashcode方法是根据对象的内存地址经哈希算法得来的)
参考:重写equals和hashCode方法 - 云+社区 - 腾讯云
实际应用中,如果需求,只要内容一致,那么就认为一致,那就要重写
比如说string 的equal 的用法
- 里面首先判断地址是否一致(判断是否为自身)
- 如果不一致,判断待比较对象是否为String 类型(如果不是返回false)
- 如果是,判断长度、判断每个字符是否相等
- 然后String 的hashCode() 方法也做了重写,通过遍历每个字符,得到一个最终的值
![]()
java 运行时启动命令参数介绍
- 执行类:java [-options] class [args…]
- 执行jar文件:java [-options] -jar jarfile [args…]
其中[-options] 配置JVM 参数;[args] 配置java 运行参数
java启动命令与参数配置_MrMoving的博客-CSDN博客
其中jvm 参数,分为标准参数和非标准参数:
1. -D 标准参数
2. -X 或者-XX 非标准参数
参考这个:https://www.cnblogs.com/haycheng/p/12781261.html
![]()
到底什么是服务治理? - 知乎
![]()
Java Hotspot G1 GC的一些关键技术 - 美团技术团队
![]()
https://segmentfault.com/a/1190000023846387
![]()
订阅与发布 — Redis 设计与实现
![]()
spring boot ,一个接口有多个实现类,如何通过一个autowire 进行一次性加载
或者怎么实现我的这个诉求,一次获取这三个实例
spring boot 怎么集成redis
kafka 的exactly once 如何去实现
provider 发出消息后,收到两个相同的确认信息(provider id 一样,offset 一样,这个什么情况)
partition 的确认信息里面内容是什么
ApplicationContext 如何get 到同一个接口的不同的实现
![]()
创建对象的几种方式
- new
- 反射
- Class 类的newInstance() 方法。默认调用的是类的无参构造方法创建对象。
如: Person p2 = (Person) Class. forName("com.ys.test. Person"). newInstance();
- 通过Constructor 类的newInstance() 方法,和第二种类似,都是反射。
Person p3 = (Person) Person.class.getConstructors()[0].newInstance(); 实际上第二种方法利用 Class 的 newInstance() 方法创建对象,其内部调用还是 Constructor 的 newInstance() 方法。
- Class 类的newInstance() 方法。默认调用的是类的无参构造方法创建对象。
- 使用clone 方法
无论何时我们调用一个对象的clone方法,JVM就会创建一个新的对象,将前面的对象的内容全部拷贝进去,用clone方法创建对象并不会调用任何构造函数。
- 反序列化
当我们序列化和反序列化一个对象,JVM会给我们创建一个单独的对象,在反序列化时,JVM创建对象并不会调用任何构造函数。
参考:Java中创建对象的5种方式,你都知道几种?【享学Java】 - 云+社区 - 腾讯云
default:指默认修饰符,什么都不加,实际上它限制的范围就是一个包内可以访问。 如果不在一个包内,即使继承关系任然是不能访问的。
protected:经常需要允许子类访问定义在父类中的数据和方法,但是不允许非子类访问这些数据和方法,这种情况下就可以使用protected,它允许任何包中的子类访问父类。

![]()
对象创建顺序
1. 父类静态代码块 / 静态成员变量(并列)
2. 子类静态代码块 / 静态成员变量(并列)
3. 父类普通代码块 / 普通成员变量(并列)
4. 父类构造方法
5. 子类普通代码块 / 子类普通成员变量(并列)
6. 子类构造方法
声明时为成员变量赋值,那么你一创建对象,这个赋值就进行,而且先于构造器执行。
而且你每次创建这个类的对象,都是同一个值。
构造方法初始化可以单独为每一个对象赋不同的值
![]()
深拷贝、浅拷贝
Java中的对象拷贝主要分为:浅拷贝(Shallow Copy)、深拷贝(Deep Copy)。
Java中的数据类型分为基本数据类型和引用数据类型。对于这两种数据类型,在进行赋值操作、用作方法参数或返回值时,会有值传递和引用(地址)传递的差别。
Java基本数据类型传递参数时是值传递;引用类型传递参数时是引用传递(地址传递)。 值传递时,将实参的值传递一份给形参;引用传递时,将实参的地址值传递一份给形参。
如何实现深拷贝,就自己实现Clonable 接口,重写每个对象的clone 方法。
这种拷贝对象的非对象属性(基本类型属性)、不可变对象属性,但是不拷贝 对象的对象属性(不含不可变对象) ,即为浅拷贝。
参考:Java 中的浅拷贝与深拷贝 - 知乎
clone 方法
clone 方法是浅拷贝,不是深拷贝。
clone 方法的作用就是复制对象,产生一个新的对象。
基本类型、引用类型
在 Java 中基本类型和引用类型的区别。
在 Java 中数据类型可以分为两大类:基本类型和引用类型。
基本类型也称为值类型,分别是字符类型 char,布尔类型 boolean以及数值类型 byte、short、int、long、float、double。
引用类型则包括类、接口、数组、枚举等。
Java 将内存空间分为堆和栈。
基本类型直接在栈 stack中存储数值
而引用类型是将引用放在栈中,实际存储的值是放在堆 heap中,通过栈中的引用指向堆中存放的数据。
浅拷贝
浅拷贝:创建一个新对象,然后将当前对象的非静态字段复制到该对象,如果字段类型是值类型(基本类型跟String)的,那么对该字段进行复制;如果字段是引用类型的,则只复制该字段的引用而不复制引用指向的对象(也就是只复制对象的地址)。此时新对象里面的引用类型字段相当于是原始对象里面引用类型字段的一个副本,原始对象与新对象里面的引用字段指向的是同一个对象。 因此,修改clonePerson里面的address内容时,原person里面的address内容会跟着改变。
只复制值类型的。对于引用类型的,只复制引用,传递引用。
深拷贝
Object 提供的clone 方法只能是实现浅拷贝的。
实现深拷贝的两种方式:
(1) 第一种是给需要拷贝的引用类型也实现Cloneable接口并覆写clone方法
引用类型不能实现深拷贝,那么我们将每个引用类型都拆分为基本类型,分别进行浅拷贝
(2)第二种则是利用序列化
参考:面试官:Java 是深拷贝还是浅拷贝 - 知乎
参考:clone方法是深拷贝还是浅拷贝?
参考:结合JVM解读浅拷贝和深拷贝
![]()
重载、重写
重载
重载,就是函数或者方法有相同的名称,但是参数列表不相同的情形。和返回值没关系。
比如说写了两个方法都叫test(),然后返回值不同。
class Test {int test() {return 0;}void test() {}public static void main(String[] args) {test();}
}在java 代码中,假设编译可以通过,但是在调用的时候,就不知道调用哪个方法了
java 识别一个方法是根据方法名加参数列表实现的,与返回值无关。
重写
即外壳不变,核心重写!
返回值、函数名、参数列表,都不变。
重写方法不能抛出新的 检查异常或者比被重写方法申明更加宽泛的异常。
toString
打印一个对象的时候,sout(person),方法内部会自动调用Person 类的toString() 方法。
在打印一个对象的时候,返回的是类名+@+hashCode 值,代表对象在内存中的位置。
如:com.yingjun.ssm.entity.Person@6d06d69c
![]()
![]()
泛型(广泛)
参数化类型。将类类型,作为参数,进行传递。
泛型接口、泛型类、泛型方法
// 泛型接口
public interface Test<T> {}// 泛型类
public class Target<T, E> implements Test<T> {}// 泛型方法
public <T> T add(Class<T> clz) {T instance = clz.getInstance();return instance;
}泛型接口、类的泛型形参,放置在接口名或类名的后面。
泛型方法的泛型形参,放置在方法返回类型的前面即可。java的泛型只是在编译时使用,用于检查传递给泛型类、方法的数据类型是否符合泛型定义,泛型类和方法中的泛型会在编译成功后擦除。
编译器并会在泛型数据操作时,自动添加类型转换。由于编译期间保证了泛型类型的正确使用,因此自动添加的类型转换是安全的。
泛型方法介绍:https://www.cnblogs.com/iyangyuan/archive/2013/04/09/3011274.html
泛型定义时的约束
定义泛型形参时,可以使用extends限制泛型的范围。
比如使用<T extends K>,表示T必须是类K的子类,或者接口K的实现类。
比如使用<T super K>,表示T必须是类K的父类,或类K实现的接口。
注意:extends并不表示类的继承含义,只是表示泛型的范围关系。
注意:extends中可以指定多个范围,实行泛型类型检查约束时,会以最左边的为准。
泛型擦除
执行结果是什么
public static void main(String[] args) { List<String> list1=new ArrayList<String>(); List<Integer> list2=new ArrayList<Integer>(); System.out.println(list1.getClass()==list2.getClass());
} 是true
getClass 方法获取的是对象运行时的类(Class,表示对象的类)
上面的问题就转化成了两个对象List<String> 和List<Integer> 在运行时的Class 是否相同。
答案是true
对它们的类型进行打印,结果都是
class java.util.ArrayList
虽然ArrayList<String>和ArrayList<Integer>在编译时是不同的类型,但是在编译完成后都被编译器简化成了ArrayList,这一现象,被称为泛型的类型擦除(Type Erasure)。
泛型的本质就是参数化类型,而类型擦除使得类型参数只存在于编译期,在运行时,jvm是并不知道泛型的存在的。
那么为什么要进行泛型的类型擦除呢?查阅的一些资料中,解释说类型擦除的主要目的是避免过多的创建类而造成的运行时的过度消耗。试想一下,如果用List<A>表示一个类型,再用List<B>表示另一个类型,以此类推,无疑会引起类型的数量爆炸。
2. 类型擦除做了什么
不同情况的类型擦除
(1)无限制类型擦除
当类定义中的类型参数没有任何限制时,在类型擦除后,会被直接替换为Object。
如:
// 原始类public class Car<T> {private T id;public T getId() {return id;}}// 编译后的类(反编译得到的结果)public class Car {public Car() {}private Object Id;public Object getId() {return Id;}}类定义中的类型参数没有任何限制,类型擦除之后,会被替换成Object(2)有限制类型擦除
当类定义中的类型参数存在限制时,在类型擦除中替换为类型参数的上界或者下界。下面的代码中,经过擦除后T被替换成了Integer:
// 原始类public class Car<T extends Integer> {private T id;public T getId() {return id;}}// 反编译后public class Car {public Car() {}private Integer Id;public Integer getId() {return Id;}}(3)擦除方法中类型的参数
和擦除类定义中的类型参数一致。(无限制直接擦除为Object,有限制的时候被擦除为上界或者下界)
3. 反射能获取泛型的类型吗
反射装的
比如说Map<Integer, String> map = new HashMap();
sout(Arrays.asList(map.getClass().getTypeParameters()));
最终只能得到[K, V]
可以看到通过getTypeParameters方法只能获取到泛型的参数占位符,而不能获得代码中真正的泛型类型。
但是通过反射还是很容易获取属性的泛型类型的,只需要通过getGenericType方法即可!
参考:Java中的反射真的可以获取泛型属性吗 - 张小凯的博客
4. 能在指定类型的List中放入其他类型的对象吗?
我们知道运行时是没有泛型约束的,在运行的时候是可以吧一个类型的对象放进另一个类型的List 里。正常这么做会报出“编译错误”,但是可以用反射,在运行时写入。
public class ReflectTest { static List<String> list = new ArrayList<>(); public static void main(String[] args) { list.add("1"); ReflectTest reflectTest =new ReflectTest(); try { Field field = ReflectTest.class.getDeclaredField("list"); field.setAccessible(true); List list=(List) field.get(reflectTest); list.add(new User()); } catch (Exception e) { e.printStackTrace(); } }
} 而在get 元素的时候,会报错。
异常提示xx 类型无法被转成xx 类型。
对于list 的get 函数,有两个步骤。首先是rangeCheck,然后是return elementData(index)
在取出元素的时候,会将这个元素强制转换成泛型中的类型。在这一阶段程序会报错。通过这一过程,可再次证明了泛型可以对类型安全进行检测。
5. 类型擦除会引起什么问题
类型擦除的时候,会有一个覆盖的操作。但是这种覆盖(@Override)会发现,子类和父类的方法参数,在类型擦除之后,参数不一致。
针对这种情况,编译器会通过添加一个桥接方法来满足语法上的要求。同时保证了基于泛型的多态能够有效。
举例:
interface Fruit<T> {T get(T obj);
}// 如果Apple 类实现了Fruit 接口之后,正常的反编译代码应该如下(文章的部分摘抄)public Apple implements Fruit {public Apple() {}public Integer get(Integer param) {return param;}public Object get(Object obj) {return get((Integer) obj)}
}参考:面试官:说说什么是泛型的类型擦除? - 51CTO.COM
泛型中的上界和下界
<T extends E> -> T 必须是E 的实现
<T super E> -> E 必须是T 的实现
<T extends E,V> -> 最左原则
比如使用<T extends K>,表示T必须是类K的子类,或者接口K的实现类。
比如使用<T super K>,表示T必须是类K的父类,或类K实现的接口。
注意:extends并不表示类的继承含义,只是表示泛型的范围关系。
注意:extends中可以指定多个范围,实行泛型类型检查约束时,会以最左边的为准。
泛型的实现的原理
1. 为使用的泛型类,单独生成一份非泛型的具体类。
比如List<String> list = new ArrayList<String>
在程序编译的时候,生成一份StringArrayList类,并且类里面所有的操作元素都是String类。
2. 采用擦除机制,泛型接口或类中,所有使用泛型形参的地方,全部擦除,替换为Object类型(java中所有类的父类)。所有相同泛型类的实例共享使用泛型类的代码。在泛型类的实例进行数据操作的地方(泛型类外部,自定义的程序部分),由编译器检查操作的参数是否为泛型类实例定义时的类类型,必要时自动添加强制类型转换。
![]()
一文读懂Java类加载全过程,java类的加载机制及加载过程
Java 反射的介绍
除了自己使用new 创建一个,还可以使用反射创建。但是反射有什么用呢。
首先引入Class 对象。
Class 就是用来描述类的类。描述“类”的类。
- 一个
.java的文件经过javac命令编译成功后,得到一个.class的文件 - 当我们执行了初始化操作(有可能是new、有可能是子类初始化 父类也一同被初始化、也有可能是反射...等),会将
.class文件通过类加载器装载到jvm中 - 将
.class文件加载器加载到jvm中,又分了好几个步骤,其中包括 加载、连接和初始化 - 其中在加载的时候,会在Java堆中创建一个java.lang.Class类的对象,这个Class对象代表着类相关的信息。
于是,原来的类class 有什么,在Class 对象中都可以找得到。于是就可以通过Class 对象来判断其真正的类型。
(注意class 和Class 首字母大小写的区别)
反射就是围绕着Class 对象和java.lang.reflect 类库(各种api )来学习的。
学习的是有,掌握几种就够用了。
- 知道获取Class对象的几种途径
- 通过Class对象创建出对象,获取出构造器,成员变量,方法
- 通过反射的API修改成员变量的值,调用方法
--------------------------------
想要使用反射,就先要得到class文件对象,其实也就是得到Class类的对象
Class类主要API:
代表成员变量 - Field
代表成员方法 - Constructor
代表构造方法 - Method
获取class文件对象的方式(class 文件对象其实就是你关心的那个对象在内存中的表现形式):
1:Object类的getClass()方法
2:数据类型的静态属性class
3:Class类中的静态方法:public static Class ForName(String className)
--------------------------------
获取成员变量并使用
1: 获取Class对象
2:通过Class对象获取Constructor对象
3:Object obj = Constructor.newInstance()创建对象
4:Field field = Class.getField("指定变量名")获取单个成员变量对象
5:field.set(obj,"") 为obj对象的field字段赋值
如果需要访问私有或者默认修饰的成员变量
1:Class.getDeclaredField()获取该成员变量对象
2:setAccessible() 暴力访问
---------------------------------
通过反射调用成员方法
1:获取Class对象
2:通过Class对象获取Constructor对象
3:Constructor.newInstance()创建对象
4:通过Class对象获取Method对象 ------getMethod("方法名");
5: Method对象调用invoke方法实现功能
如果调用的是私有方法那么需要暴力访问
1: getDeclaredMethod()
2: setAccessiable();
使用反射的原因:
1. 提高程序的灵活性
2. 屏蔽掉实现细节,让使用者更加方便好用
java的反射到底是有什么用处?怎么用? - 知乎
![]()
java 反射常用的api
JAVA反射机制是在运行状态中:
对于任意一个实体类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意方法和属性;
这种动态获取信息以及动态调用对象方法的功能称为java语言的反射机制
Java的反射机制允许编程人员在对类未知的情况下,
获取类相关信息的方式变得更加多样灵活,调用类中相应方法,
这是Java增加其灵活性与动态性的一种机制。
反射是通过一个类的Class 对象进行操作而取得该类的所有方法和属性的。
反射的源头在于Class 对象。
反射最常用到的操作:
取得属性的修饰符,属性名,属性值,设置属性值,取得所有的属性。
操作方法,取得方法的修饰符,方法名,方法参数,方法参数类型,方法返回值,取得一个类的所有方法。
反射可以动态的调用、修改一个对象的任何属性、方法(包括私有属性和方法)。
对于泛型擦除之后,程序处于运行之中,可以使用反射,为某个String 类型的List 塞入一个Integer 类型的元素。
getMethods()返回的是当前Class对象的所有公有的方法,包含从父类或父接口继承而来的方法。
getDeclaredMethods()返回的是当前Class对象的所有(包括:public,protected,default,private)方法,但是并不包括继承自父类或父接口的方法。
declared:宣告、断言、表态
常用api 参考如下链接:
参考:Java反射常用API_wenpan的博客-CSDN博客_java反射api是什么
java 反射的原理
通过类的对象(Class 对象)枚举出该类的所有方法。
可以通过Method.Accessible 绕过Java 语言的访问权限。在私有方法所在类之外的地方调用它。
spring 的IOC 底层原理使用的就是反射机制。
Web开发中,我们经常使用的各种通用框架为了保证框架的可扩展性,往往都使用Java反射功能,根据配置文件中的信息来动态的加载不同的类,还可以为类中的属性赋值等等。
原理:在JVM的层面,java的对象引用不仅要可以直接或间接的接触到对象类型,更应该可以根据索引能得到这个对象的类型数据(对象的Class对象)。这样的JVM设计使得JAVA可以拥有反射功能。
(举例:你怎么知道我电话的?我查的通讯录)
参考:面试官问我反射的实现原理是什么??
JAVA反射机制是在运行状态中,
对于任意一个类,都能够知道这个类的所有属性和方法;
对于任意一个对象,都能够调用它的任意一个属性和方法;
这种动态获取的信息以及动态调用对象的方法的功能称为 java语言的反射机制。
原理:Java在编译之后会生成一个class文件,反射通过字节码文件找到其类中的方法和属性等
可参考:java 反射原理(jvm是如何实现反射的) - 简书
为什么java 反射比直接调用效率低
有空可以看这个,反射的使用和低效率原因:都说 Java 反射效率低,究竟原因在哪里? - 知乎
- Method#invoke 方法会对参数做封装和解封操作
- 需要检查方法可见性
- 需要校验参数
- 反射方法难以内联
- JIT 无法优化
Class.forName() 和ClassLoader 的区别
在java中Class.forName()和ClassLoader都可以对类进行加载。ClassLoader就是遵循双亲委派模型最终调用启动类加载器的类加载器,实现的功能是“通过一个类的全限定名来获取描述此类的二进制字节流”,获取到二进制流后放到JVM中。
Class.forName()方法实际上也是调用的CLassLoader来实现的。
Class.forName加载类时将类进了初始化,而ClassLoader的loadClass并没有对类进行初始化,只是把类加载到了虚拟机中
参考:【003期】Java 中 Class.forName 和 ClassLoader 到底有啥区别?
对象的引用是存在“栈”中。对象的实例存在“堆”中。
当一个对象不声明,不赋值的时候,它只在栈中存在引用;在堆中是没有引用指向的。
![]()
解释执行、编译执行、JIT 的区别
整体流程:翻译(成机器码,或者字节码) -> 解释执行
编译器是把源程序的每一条语句都编译成机器语言,并保存成二进制文件,翻译与执行是分开的,这样运行时计算机可以直接以机器语言来运行此程序,速度很快;C,C++都是靠编译实现的。
解释器则是只在执行程序时,才一条一条的解释成机器语言给计算机来执行,翻译与执行一次性完成,所以运行速度是不如编译后的程序运行的快的,但是就启动效率而言,解释执行的速度更快,因为它不需要进行编译过程。
总的来说,编译执行只需要最开始编译一次,之后每次运行时都不需要再编译,所以运行效率会很快;解释执行在每一次运行时都需要经过解释的过程,所以执行效率较低。
通俗一点,编译就是饭菜全部做好再吃,解释就相当于火锅,边涮边吃。
从内存使用方面来看,编译执行需要生成编译后的机器码文件,而解释执行时逐句解释执行,所以解释执行对内存占用更少。
Java程序也需要编译,但是没有直接编译称为机器语言,而是编译成为字节码,然后在JVM上用解释方式执行字节码。
Python 的也采用了类似Java的编译模式,先将Python程序编译成Python字节码,然后由一个专门的Python字节码解释器负责解释执行字节码。
Java通过解释器解释执行字节码,这样的执行方式相对较慢,尤其是遇到一些运行频繁的代码块或者方法时。于是后来JVM引入了JIT即时编译器(just in time),当JVM发现某些代码运行频繁时就会认定为热点代码“hot spot code”,为了提高运行效率,就会把这些代码编译成为平台相关的机器码然后进行优化,JIT就是用来完成这项工作的。二者共同造就了java的优势——当程序需要迅速启动时,解释器首先发挥作用,省去编译时间,当程序运行时,编译器会逐渐将更多的代码编译成本地机器码从而获得更高的效率。
所以我的理解就是JAVA先编译(高级语言→字节码),后解释(字节码→机器码),在解释的过程中也可能进行编译(JIT编译热点代码)。
参考:解释执行与编译执行以及JIT的区别
![]()
重载,返回值是区分点吗?不是。
@Override
String run(String s)
String run(Object s)
根据以上方法签名,测试以下代码,分别调用哪个函数
run("abc") -> 调用第一个函数
run(null) -> 调用第一个函数

A().B(Integer.valueOf(1))在class A中没有找到类型匹配的方法,Java自动类型提升机制,对Integer进行向上转型后匹配到了了public void B(Number n) 方法,调用后输出字符串"Num"
![]()
向上转型、向下转型
父子类型之间的转换,分为向上转型和向下转型。它们的区别如下:
1. 向上转型:通过子类对象(小范围)实例化父类对象(大范围),这种属于自动转换
2. 向下转型:通过父类对象(大范围)实例化子类对象(小范围),这种属于强制转换
关注点,是在等号后面那个东西。
1)向上转型
父类引用指向子类对象为向上转型,语法格式如下:
fatherClass obj = new sonClass();
其中,fatherClass 是父类名称或接口名称,obj 是创建的对象,sonClass 是子类名称。
向上转型就是把子类对象直接赋给父类引用,不用强制转换。使用向上转型可以调用父类类型中的所有成员,不能调用子类类型中特有成员,最终运行效果看子类的具体实现。
2)向下转型
与向上转型相反,子类对象指向父类引用为向下转型,语法格式如下:
sonClass obj = (sonClass) fatherClass;
其中,fatherClass 是父类名称,obj 是创建的对象,sonClass 是子类名称。
向下转型可以调用子类类型中所有的成员,不过需要注意的是,如果父类引用对象指向的是子类对象,那么在向下转型的过程中是安全的,也就是编译是不会出错误。但是如果父类引用对象是父类本身,那么在向下转型的过程中是不安全的,编译不会出错,但是运行时会出现我们开始提到的 Java 强制类型转换异常,一般使用 instanceof 运算符来避免出此类错误。
例如,Animal 类表示动物类,该类对应的子类有 Dog 类,使用对象类型表示如下:
Animal animal = new Dog(); // 向上转型,把Dog类型转换为Animal类型
Dog dog = (Dog) animal; // 向下转型,把Animal类型转换为Dog类型参考:Java对象类型转换:向上转型和向下转型
![]()
到底什么是服务治理? - 知乎
Java Hotspot G1 GC的一些关键技术 - 美团技术团队
mysql 的锁
https://segmentfault.com/a/1190000023846387
订阅与发布 — Redis 设计与实现
![]()
@Bean 和@Autowire 的关系
@Autowire 的作用是“织入”:在上下文已经有了实例,请给我一个xxx 实例
@Bean:手动创建一个实例,并保留在IOC中(作用在方法上,所以是手动的,需要手动写)
@Bean
BookingService getBookingService() {return new BookingService();
}@Component 自动创建一个实例,并保存到IOC 中
@Component和@Bean和@Autowired之间的区别_autowired和component的区别_Stack Piston的博客-CSDN博客
@Component 作用于类;@Bean 作用于方法。
@Component 用来将识别的类装配到spring bean 容器中。
@Bean 注解的作用,是在标有该注解的方法中,定义产生了这个bean,@Bean 告诉spring 这是某个类的实例,当它需要的时候,请还给我。
@Bean 注解比 @Component 注解的自定义性更强,而且很多地方我们只能通过 @Bean 注解来注册 bean。比如当我们引用第三方库中的类需要装配到 Spring 容器时,只能通过 @Bean 来实现。
Autowire 和 @Resource 的区别
@Autowire 和 @Resource都可以用来装配bean,都可以用于字段或setter方法。
@Autowire 默认按类型装配,默认情况下必须要求依赖对象必须存在,如果要允许 null 值,可以设置它的 required 属性为 false。
@Resource 默认按名称装配,当找不到与名称匹配的 bean 时才按照类型进行装配。名称可以通过 name 属性指定,如果没有指定 name 属性,当注解写在字段上时,默认取字段名,当注解写在 setter 方法上时,默认取属性名进行装配。
注意:如果 name 属性一旦指定,就只会按照名称进行装配。
@Autowire和@Qualifier配合使用效果和@Resource一样
面试必问|Spring @bean 和 @component 注解有什么区别?-阿里云开发者社区
![]()
spring boot ,一个接口有多个实现类,如何通过一个autowire 进行一次性加载
使用Llist<xxxService> 上面标注@Autowire,参考:使用@Autowired批量注入某一个接口下边的所有实现类方法(并且进行工厂封装Factory)
![]()
1. 向一个类中注册两个相同接口的实现类。因为@Autowire 是按照类型加载的,所以通过@Autowire + @Qualifier 来完成注册。

![]()
spring boot 怎么集成redis
SpringBoot教程(十四) | SpringBoot集成Redis(全网最全) - 掘金
![]()
ApplicationContext 如何get 到同一个接口的不同的实现
使用ApplicationContextAware 接口
@Component
public class ServiceLocator implements ApplicationContextAware {private Map map;@Overridepublic void setApplicationContext(ApplicationContext applicationContext) throws BeansException {// 根据接口类型返回响应的所有beanmap = applicationContext.getBeansOfType(NameService.class);}// 获取所有实现集合public Map getMap() {return map;}// 获取对应服务public NameService getService(String key) {return (NameService) map.get(key);}
}ApplicationContextAware的作用是可以方便获取Spring容器ApplicationContext,从而可以获取容器内的Bean。
以上的实现是将相同的接口,放入到map 里面。
![]()
项目中权限校验怎么做的
专门的网关服务
对开发的rpc 接口进行配置
以http 接口给出
在获取到请求后
解析HttpServletRequest 的时候,取出来参数
进行dubbo 泛化调用
其中有前置校验

![]()
假设一个场景
name,id,subject 科目,grade 成绩
数据做插入的时候,如何避免重复
前端拦截
后端业务拦截
db 特性拦截
- 基于唯一索引,
报错,
或者insert ignore into xxTable (xxx, xxx, xxx) -> 忽略
或者insert into xxTable (xx, xx) on duplicate key update -> 更新
或者replace into xxTable -> 删除再插入
如果没有唯一索引,
insert if not exists -> 如果不存在,则正常插入,如果存在,则忽略
示例代码:insert ignore into living (room_id) VALUES("7758521")replace into living (room_id) VALUES("7758521")insert into living (room_id) VALUES("7758521") on duplicate key update source_type = "1"insert into living (room_id) SELECT "room_id" from living where not exists (select room_id from living where room_id = "7758521")
参考:Mysql 4种方式避免重复插入数据! - 云+社区 - 腾讯云
mysql数据库中避免重复数据插入_SUN_FEI的博客 - db 乐观锁思想,添加version 版本号
前端防重:
- PRG 模式(post redirect get)
当用户进行表单提交时,会重定向到另外一个提交成功页面,而不是停留在原先的表单页面。
这样就可以防止重复提交(前端防重策略)
- token 机制
先根据请求内容,到后端生成token,存入redis
然后拿着token 到后端做请求,如果有token 存在,则处理
如果没有token 存在,则失败。
对于大量请求,加锁;或者使用reids 的机制进行自增。类似于version
但是多一次请求,浪费资源
服务幂等
- 防重表
使用防重表,在该表中建立一个或多个字段的唯一索引作为防重字段,用于保证并发情况下,数据只有一条
向业务表中插入数据之前先向防重表插入,如果插入失败则表示是重复数据
不用悲观锁(锁表)的原因是防止造成死锁
- db 乐观锁,version 机制
- 利用zk 的机制,watch 机制,实现监听,也就是加锁。
一个大excel,如何load 到db 里面
前端上传excel 到某个cdn,拿到链接,给到后端,后端下载,然后后台执行写入。
提供给前端的api ,数据如何校验,如果有异常,怎么抛出,前端如何拿到
根据不同的规则校验
包装response 返回给前端
范式:MySQL数据库三范式 - 知乎
有两个db,先写上海学生成绩库,再写教育部学生成绩库
这个场景,两个库的关联事务如何做处理,两个场景,上海库成功了,教育部没成功,怎么两个都回滚,这样如何处理
分布式事务:Spring Boot多数据源事务管理_卓立的博客-CSDN博客_多数据源事务控制
分布式事务,看这篇就够了 - 知乎
两阶段提交:同一方法下两个数据源的回滚_分库分表下事务问题的一些解决思路
mysql 中事务的实现:『浅入深出』MySQL 中事务的实现 - 面向信仰编程
大量数据从db 导出到excel,怎么处理,从而避免out of memory
后台处理,返回链接,然后去下载
spring batch 是什么
参考链接:通过例子讲解Spring Batch入门,优秀的批处理框架 - 知乎
hive、hbase
![]()
java 8 的stream 原理与使用
list.stream().mapToDouble(Integer::doubleValue).average();java 中的流是什么
问题:
大家都把流比作水流,从一端流向一端,当向输出流写去数据,这些数据是立即到达目的地还是在始端还是在流里面?如果在流里面,我就想不通流里面还可以放数据?放数据的不是只有这两端吗?例如:网络上主机A建立目的地为主机B的输出流,A向输出流写数据,那么数据不是放到A也不是B,难道是放到网线上?这也太离谱了吧?
回答:
流比喻数据的均匀连续性。
计算机最小单位是字节,所以流数据最小单位也是字节(byte)
流这个比喻的本质就是为了让某个对象可以均匀持续地吐出无间隔的数据,或者你可以向这个对象毫无压力地持续不断塞进数据。。。。至于那些管子。。。恰恰是因为现实世界不够符合这个要求,所以必须有。
管子什么的,那不是流,那是不得不要靠它们来装(装逼的装 不是装放的装)流的枝节。
看片子很卡,你会有“流”的任何联想和感受吗。。怎么办?你先等等,操作系统已经准备了个长管子,帮你缓存一大段你再看,这回就很流很流的感觉了。
参考:https://www.zhihu.com/question/28457447/answer/44911601
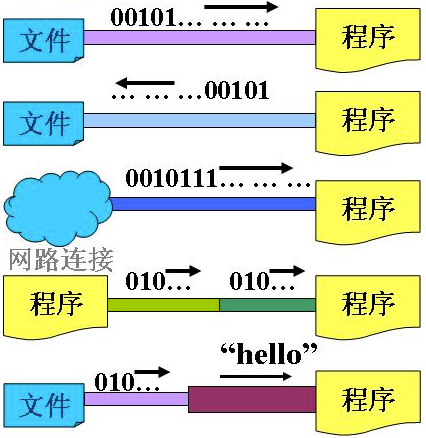
流是个抽象的概念,是对输入输出设备的抽象,Java程序中,对于数据的输入/输出操作都是以“流”的方式进行。设备可以是文件,网络,内存等。
![]()
kafka
1. kafka 维护消费状态跟踪的方法有什么?
Kafka的 Topic 被分成了若干分区,每个分区在同一时间只被一个 consumer 消费。这意味着每个分区被消费的消息在日志中的位置仅仅是一个简单的整数:offset。这样就很容易标记每个分区消费状态就很容易了,仅仅需要一个整数而已。这样消费状态的跟踪就很简单了。
每个消费者(Consumer)对每个Topic都有一个offset用来表示 读取到了第几条数据
2. 主从同步
Kafka允许topic的分区拥有若干副本,这个数量是可以配置的,你可以为每个topic配置副本的数量。Kafka会自动在每个个副本上备份数据,所以当一个节点down掉时数据依然是可用的。
Kafka的副本功能不是必须的,你可以配置只有一个副本,这样其实就相当于只有一份数据。
3. zk 之于kafka 的作用
Zookeeper 主要用于在集群中不同节点之间进行通信
在 Kafka 中,它被用于提交偏移量,因此如果节点在任何情况下都失败了,它都可以从之前提交的偏移量中获取除此之外,它还执行其他活动,如: leader 检测、分布式同步、配置管理、识别新节点何时离开或连接、集群、节点实时状态等等。
4. kafka 的exactly once 如何去实现
provider 发出消息后,收到两个相同的确认信息(provider id 一样,offset 一样,这个什么情况)
partition 的确认信息里面内容是什么
![]()
@Transactional 失效的场景
spring 提供的事务管理机制,主要有编程式和声明式两种。
编程式是在代码中手动管理事务的提交、回滚等操作,代码侵入性比较强。

声明式事务:使用注解,基于aop 切面完成。
声明式事务也有两种实现方式,是基于TX和AOP的xml配置文件方式,二种就是基于@Transactional注解了。
@Transactional 的属性
propagation,事务的传播属性,那六种。(required 为默认)
required、(没有则创建一个,仅对b 生效)
support、
mandatory、
requires_new、(重新创建一个,如果A 存在事务,则暂停当前的事务。A 抛异常,不影响B。各回滚各的)
not_supported、(非事务方式运行,如果当前存在事务,则暂停)
never、(非事务方式运行,如果当前存在事务,则抛异常)
nested(嵌套的,如果a 存在,则b 嵌套其中执行,否则同required。父回子必回,子回父不一定回)
isolation 属性,事务的隔离级别
默认为:Isolation.DEFAULT
solation.DEFAULT:使用底层数据库默认的隔离级别。
Isolation.READ_UNCOMMITTED
Isolation.READ_COMMITTED
Isolation.REPEATABLE_READ
Isolation.SERIALIZABLE
timeout 属性
timeout :事务的超时时间,默认值为 -1。如果超过该时间限制但事务还没有完成,则自动回滚事务。
readOnly 属性
readOnly :指定事务是否为只读事务,默认值为 false;为了忽略那些不需要事务的方法,比如读取数据,可以设置 read-only 为 true。
rollbackFor 属性
rollbackFor :用于指定能够触发事务回滚的异常类型,可以指定多个异常类型。
noRollbackFor属性
noRollbackFor:抛出指定的异常类型,不回滚事务,也可以指定多个异常类型。
@Transactional 失效场景
1. 应用在非public 修饰的方法上
2. propogation 设置错误
3. 属性rollbackFor 设置错误(spring 默认是runtimeException 或者Error)

4. 同一个类中方法调用,导致失效
5. 异常被catch
6. 数据库引擎不支持事务
参考:https://baijiahao.baidu.com/s?id=1661565712893820457
![]()
java main函数的args[]参数
args[]这个参数主要是为程序使用者在命令行状态下与程序交互提供的一种手段。
在命令行中执行java程序的时候使用的是“java 文件名 args参数”。所以args[]是在命令行运行时输入的参数,由于可以有多个参数,所以定义成数组。之所以要把args[]数组定义为String类型是因为java缺省就认为输入的参数都为字符串,之后自己可以进行类型转换。
![]()
分布式id:分布式自增序列id的实现(三) ---分布式序号生成器---基于Zookeeper客户端Curator提供的DistributedAtomicLong自增功能_russle的专栏-CSDN博客
![]()
接口限流的几种办法(4 种)
- 固定窗口计数器
缺点:双倍突发请求,比如说限制一秒5 个请求,在第一秒后半秒来了5个,第二秒前半秒来了5个,那么就会发生一秒中10个请求的情况。
- 滑动窗口计数器
避免了双倍突发的情况,但是时间精度越细,那么算法所需的空间容量就越大。
- 漏桶算法(使用队列)
漏桶算法漏出的是请求,漏桶限制的是常量流出速率,即流出速率是一个固定常量值。
缺点是,如果遇到了突发流量,即使服务器没有什么负载,但是还是要按照限制的速率去消费。
- 令牌桶算法(RateLimiter)
令牌桶漏出的是令牌,水滴代表令牌,按照固定速率生成。
令牌桶限制的是平均流入速率
令牌桶算法既能够将所有的请求平均分布到时间区间内,又能接受服务器能够承受范围内的突发请求,因此是目前使用较为广泛的一种限流算法。
分布式限流中间件,sentinel
单机流控,集群流控。
集群流控角色分为token server / token client,token client 向server 请求token
集群流控支持两种阈值计算方式:集群总体模式、单机均摊模式(按照链接的单机均摊的推算总体的 )
集群流控两种部署方式:独立部署(单独启动一个token server 来处理token client 的请求)、嵌入部署(在多个 sentinel-core 中选择一个实例设置为 token server)
redis 令牌桶的实现注释:
需要保存什么数据在redis中?
- 当前桶的容量,最新的请求时间
保存“最新请求的时间”的原因:如果再来一个请求,那么使用当前来到的请求时间,减去已存的“最新请求时间”,得到一个时间差,除以令牌产生速率,就可以得到这段时间的令牌数量。
参考:https://www.cnblogs.com/Chenjiabing/p/12534346.html
保护高并发服务:限流、缓存、降级
rateLimiter 的使用:https://zhuanlan.zhihu.com/p/60979444
![]()
多线程适用于什么场景
适用于io 密集型的任务
cpu 密集型任务的特点就是要进行大量的计算,消耗cpu 资源。如果用多任务完成,但是任务越多,花在任务切换的时间就越多。所以这种应该让进程数量等于cpu 核心数
io 密集型任务特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成,对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。常见的大部分任务都是IO密集型任务。这种适合使用高效的脚本语言进行开发
线程中断:并发编程学习总结(三) : 线程的中断详解
![]()
https://segmentfault.com/a/1190000039947938敖丙 java famaily:https://github.com/AobingJava/JavaFamily/
敖丙csdn 整理的内容
![]()
fail-fast 机制
快速失败机制,是一种“错误检测”机制,不是Collection 特有的。
(参考:https://www.cnblogs.com/54chensongxia/p/12470446.html )
比如说如下代码:
public String queryUserById(Integer id) {if (id == null || id <= 0) {throw new RuntimeException("error parameters ...");}......
}fail-fast的字面意思是“快速失败”。一旦检测到错误,则立刻抛出异常,不向下执行。这样能及早发现问题,避免程序错误地向下执行。同时,自定义抛出的异常更容易处理与定位。
当我们在遍历集合元素的时候,经常会使用迭代器,但在迭代器遍历元素的过程中,如果集合的结构被改变的话,就会抛出异常,防止继续遍历。这就是所谓的快速失败机制。
意思就是说,当Iterator这个迭代器被创建后,除了迭代器本身的方法(remove)可以改变集合的结构外,其他的因素如若改变了集合的结构,都被抛出ConcurrentModificationException异常。
hashmap 中的modcount 的作用,是在进行迭代的过程中,会把modcount 赋值给迭代器expectedModCount,迭代器在做操作的时候,如果检查和hashmap 中的modcount 不一致,则代表有其他线程修改了。这就是fail-fast 机制
![]()
对于ArrayList 来说,其中有一个成员变量modCount。它表示该集合实际被修改的次数。modCount 初始默认是0,当ArrayList 初始化完成,这个值就有了。
expectedModCount 是 ArrayList中的一个内部类——Itr中的成员变量。
Itr类,实现了Iterator接口。
expectedModCount表示这个迭代器预期该集合被修改的次数。其值随着Itr被创建而初始化。只有通过迭代器对集合进行操作,该值才会改变。
所以导致产生异常的原因是:remove和add操作会导致modCount 改变,这样和迭代器中的expectedModCount不一致。
在单线程情况下也可能发生,就是在有使用有fail-fast机制的迭代器遍历集合时,有修改集合的操作也会抛出此异常;
参考:https://zhuanlan.zhihu.com/p/37476508
避免fail-fast抛异常?
1.如果非要在遍历的时候修改集合,那么建议用迭代器的remove等方法,而不是用集合的remove等方法。(老实遵守阿里巴巴java开发规范……)
2.如果是并发的环境,那还要对Iterator对象加锁;也可以直接使用Collections.synchronizedList。
3.CopyOnWriteArrayList(采用fail-safe)
copyOnWrite,写时复制,简单理解就是,当我们往一个容器添加元素的时候,先将当前容器复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器。
参考:一文彻底弄懂fail-fast、fail-safe机制(带你撸源码) - 知乎
![]()
Map 中使用数组作为key
使用数组作为map 中的key,使用的是数组的 地址引用的 hashcode。
如果非要使用,那么就得取值,遍历,得到结果。
hashmap 插入流程
(java 7)
- 容器是否初始化,没有,则初始化
- 判断是否直接插入下标为0 的桶中,如果是则执行插入元素
表操作记录+1,先判断是否需要扩容,再创建新节点,使用头插法插入 - 如果不是[直接插入下标为0 的桶]中,则计算下标
- 遍历表,如果存在相同的key 值,那么覆盖旧值,返回旧值结束
- 如果不存在相同的key 值,表操作记录+1,判断是否需要扩容,不需要,则直接创建节点,进行插入
- 如果需要扩容,进行resize 操作,迁移数据,然后创建新节点,进行插入
- 结束
初始化;null key 判断;计算下标;key 是否相等;是否扩容;插入
先扩容,再插入;头插法
(java 8)
- 判断当前容量大小是否为空,如果空,扩容为16
- key 是否为空判断,如果为空,则直接插入下标为0 的桶中
- 不为空,根据key 的hashcode,对其进行扰动处理,降低冲突的概率,获取元素下标
- 是否有hash 碰撞,没有则直接放入桶中
- 如果有碰撞,比较两个key 是否相同,相同则覆盖,不同则插入链表尾部
- 如果超过阈值8,同时大于64 个节点,链表转为红黑树;如果超过 8,不大于64,那么扩容
- 如果插入后元素到达了阈值,执行扩容判断
- 扩容成功后,对元素下标重新计算
初始化;获取下标;key 是否相等;插入;树阈值判断;是否扩容
先插入,再扩容
头插法:
void transfer(Entry[] newTable, boolean rehash) {int newCapacity = newTable.length;//遍历表for (Entry<K,V> e : table) {//循环遍历表中的每个indexwhile(null != e) {//开始循环Entry<K,V> next = e.next;//保存该节点的next节点,作为下一次循环使用if (rehash) {//是否重新计算hash值e.hash = null == e.key ? 0 : hash(e.key);}int i = indexFor(e.hash, newCapacity);//重新计算下标e.next = newTable[i];//把next引用指向新下表的头节点newTable[i] = e;//放入新下标链表的头节点e = next;//取出保存的next节点,准备开始下一次循环}}}总结就是,对table 中的每个桶做遍历,同时对桶上的节点(如果有链表)进行遍历
对节点内的链表遍历的时候,使用头插法
while (null != e)
弄个next = e.next
对e 进行重新计算下标
获得此下标的节点
设置e.next = newTable[i]
然后把e 放到这个节点中newTable[i] = e
然后e = next,进行下一次遍历
尾插法:就是遍历,找到最后,插入
看起来尾插法效率不高,这么做的原因是
简化头插法transferEntry<K,V> next = e.next;//保存正在迁移节点的next节点int i = indexFor(e.hash, newCapacity);//计算迁移节点的新下标e.next = newTable[i];//把新下表桶中的头节点设为迁移节点的next节点newTable[i] = e;//e = next;
比如线程a 执行扩容,然后就被挂起
线程b 完成扩容
此时线程a 继续进行直到新节点的复制操作
b 完成扩容之后,比如说原来是 3 -> 7,扩容完成之后变成 7 -> 3
线程a 如果继续执行,那么就会变成 3 -> 7,形成死循环
hashmap 中红黑树演变的介绍:
链表转为红黑树:节点个数大于8 且数组个数大于64
红黑树转为链表,涉及到两个操作
1. remove 元素的时候,不是小于6 一定变为链表,而是通过根节点和节点的子节点判断的,最大可能是10 个
(在红黑树的root节点为空 或者root的右节点、root的左节点、root左节点的左节点为空时 说明树都比较小了)
2. resize 的时候才会根据6 这个因子做判断,小于等于6 的时候
参考:掘金
另外参考:HashMap真的是大于8就转换成红黑树,小于6就变成链表吗???_日常发呆-CSDN博客_hashmap超过多少转红黑树
这个可以看看:为什么Map桶中个数超过8才转为红黑树_sinat-CSDN博客_为什么超过8转为红黑树
map 相关的问题:21个关于HashMap刁钻的面试题,第四个我就跪了-华为云
对于队列的几个方法,
添加元素
add() 如果队列已满,则抛异常
offer() 如果队列已满,则返回false
移除元素
remove() 如果队列为空,抛异常
poll() 如果队列为空,返回null
![]()

![]()
其他场景面试题目
https://segmentfault.com/a/1190000039947938
https://segmentfault.com/a/1190000039947938
![]()
集合类 单值类型、双值类型、实现。
map 的插入流程(已看完)
jdk1.7 和1.8 多线程下的区别:JDK1.7和JDK1.8中HashMap为什么是线程不安全的?_张先森的博客-CSDN博客_hashmap为什么是线程不安全的
一些基本点
数组内存空间是连续的,链表内存空间是离散的。
hashmap 底层是由数组 + 链表构成的,寻址容易,插入删除也容易。(存储单元数组Entry[],数组里面包含链表)
(transient 的介绍:Java中transient关键字的详细总结 )
jdk 1.7 的hashmap 的基础是一个线型数组Entry[ ],transient 修饰。冲突的时候,使用头插法
数组下标这么算:index=hash%Entry[].length; hash 是通过key 的hashcode() 取得的。
concurrentHashMap get、put、remove 的时候通过锁“段”(默认分为16 个段)来达到并发,只有在计算resize 的时候才锁整个map
jdk 1.8 的hashmap 的基础是一个线型数组Node[ ],transient 修饰。
hashmap 中各个成员变量为什么用transient
Object 的hashCode() 方法是个native,
不同的jvm 可能有不同的实现,对同一个字符串产生的hashcode 可能不一致。
对于hashmap 重写了序列化方法
对于ArrayList,序列化的时候去掉了扩容里面的null 元素
参考:https://blog.csdn.net/u010454030/article/details/79416996
hashmap 和concurrentHashMap 的区别:
40 个 Java 集合面试官常问问题和答案:
40 个 Java 集合面试官常问问题和答案_诗琪芮的博客-CSDN博客
Java集合必会14问(精选面试题整理):
Java集合必会14问(精选面试题整理) - 知乎
40 个 Java 集合面试官常问问题和答案_诗琪芮的博客-CSDN博客
Map 接口及Collection 接口是所有集合框架的父接口。
- Collection接口的子接口包括:Set接口和List接口
- Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等
- List接口的实现类主要有:ArrayList、LinkedList、Stack以及Vector等
- Map接口的实现类主要有:HashMap、TreeMap、ConcurrentHashMap以及Properties等
- arrayList 底层使用Object 数组。线程不安全。容量不够, 乘以1.5 + 1,getter、setter 效率高。
- linkedList 底层使用双向循环链表数据结构,查询慢,增删快。线程不安全。
- 在频繁读取的时候,用ArrayList;在频繁增删的时候,用LinkedList
- hashSet 底层使用哈希表实现,内部是hashMap
hashcode 对不同长度的输入,总是得到一个定长的输出。hashcode 的空间肯定小于输入空间,所以有可能重复。同时hashcode 方法可以重载的。
“==” 是比较地址是否相同;equals 是比较值是否相同。
HashSet 判断元素是否相同时,对于包装类型直接按值⽐较。对于引⽤类型先⽐较 hashCode 是否相同,不同则代表不是同⼀个对象,相同则继续⽐较 equals,都相同才是同⼀个对象。
hashcode 对不同长度的输入,总是得到一个定长的输出。hashcode 的空间肯定小于输入空间,所以有可能重复。同时hashcode 方法可以重载的。
“==” 是比较地址是否相同;equals 是比较值是否相同。
- treeSet 内部是treeMap 的sortedSet。底层使用二叉树实现,排序存储。
添加元素到集合时按照⽐较规则将其插⼊合适的位置,保证插⼊后的集合仍然有序。
- linkedHashSet,底层是LinkedHashMap,采用哈希表存储,并用双向链表记录插入顺序。
- HashMap 底层是哈希表,允许key 为null,value 为null,线程不安全
默认大小16,扩容时2 的幂次方,默认加载因子为0.75
- HashTable 底层是哈希表,key、value 都不允许为null。线程安全。内部使用了synchronized 关键字。
- TreeMap 键不可以重复,不可以为null;值可以重复,底层是二叉树。基于红黑树实现。
增删改查的平均和最差时间复杂度均为 O(logn) ,最⼤特点是 Key 有序。
key 不允许为null
- TreeMap 键不可以重复,不可以为null;值可以重复,底层是二叉树。基于红黑树实现。
线程安全:HashTable/StringBuffer
线程不安全:HashMap/TreeMap/HashSet/ArrayList/LinkedList
arrayList 的空间浪费主要体现在list 列表结尾会预留出一定的空间容量。linkedList 的空间花费提现在它的每一个元素都要存放前驱结点、后继节点、和数据。
hashTable 方法是synchronized 的。HashMap 的初始容量为16,HashTable 的初始容量为11。填充因子默认都是0.75。Map 扩容:x2,table 扩容:x 2 + 1
HashTable 和HashSet 的区别,HashSet 就是基于hashMap 实现的,只不过hashset 里面的hashmap 的所有value 都是同一个object 而已。线程不安全。
重点:hashMap 在java 1.7 和1.8 的区别;
首先hashmap 是线程不安全的,体现在三个方面
- 数据丢失
- 数据重复
- 死循环
对于死循环,在1.8 中不存在了。死循环是因为在resize 过程中对链表进行了倒排序处理;在1.8 中不会再有倒排序处理,所以不会死循环。put 操作,是先把数据放入map 中去,再根据元素的个数决定是否做resize。如果线程操作完了A -> B,此时线程B 又来了,就会造成A -> B -> A 的情况。
数据丢失,如果有两个线程同时判断table[i] == null,这时两个线程都会创建Entry,就出出现数据丢失的情况。
数据重复,如果两个线程同时发现自己的key 不存在,而这两个线程的key 实际是相同的。在像链表中写入的时候,第一个线程将e 设置为自己的entry,而第二个线程执行到了e.next,此时拿到的是最后一个节点,已然会把已持有的数据插入到链表中,这样就会出现了数据重复。
HashMap的线程不安全主要体现在下面两个方面:
1.在JDK1.7中,当并发执行扩容操作时会造成环形链和数据丢失的情况。
2.在JDK1.8中,在并发执行put操作时会发生数据覆盖的情况。
1.7 先扩容再插入,有可能避免哈希冲突。使用头插法
1.8 先插入再扩容,(而jdk8如果要先扩容,由于是尾插法,扩容之后还要再遍历一遍,找到尾部的位置,然后插入到尾部。(也没怎么节约性能))
concurrentHashMap 在1.8 对于1.7 的区别。
去除 Segment + HashEntry + Unsafe 的实现,
改为 Synchronized + CAS + Node + Unsafe 的实现
ConcurrentHashMap 和HashTable 的区别。
hashtable 的方法都加了synchronized
jdk1.7 concurrentHashMap 底层采用分段数组+链表实现。jdk1.8 采用数组+链表/红黑二叉树实现。
1.8 采用了 synchronized + CAS 算法来保证线程安全。
1.7 中,ConcurrentHashMap 使用“分段锁”机制实现线程安全,数据结构可以看成是"Segment数组+HashEntry数组+链表",一个 ConcurrentHashMap 实例中包含若干个 Segment 实例组成的数组,每个 Segment 实例又包含由若干个桶,每个桶中都是由若干个 HashEntry 对象链接起来的链表。因为Segment 继承ReentrantLock,所以能充当锁的角色,通过 segment 段将 ConcurrentHashMap 划分为不同的部分,就可以使用不同的锁来控制对哈希表不同部分的修改,从而允许多个写操作并发进行,默认支持 16 个线程执行并发写操作,及任意数量线程的读操作。
15道常见的 Java集合类 面试题:
15道常见的 Java集合类 面试题 - 知乎
hashmap 的实现、扩容机制、java8 的改变 hashmap 1.7 使用的是“头插法”,hashmap 1.8 使用的是“尾插法” 多线程机制下,hashmap1.7 会导致死循环的问题,扩容的时候导致。在get 的时候就会进入死循环。 java1.8 在put的时候,判断没有冲突,然后赋值,会导致数据丢失
concurent hash map 设计思路,单独锁、分段锁、无锁。 concurrent 1.7 的实现,是segment + hashEntry + ReentrantLock 组成,结构仍然是数组加链表, concurrent 1.8 采用Node + CAS + Synchronized 来保证并发安全 对于concurrent 1.8,Java 提供了volatile 来保证可见性、有序性,但是不保证原子性 get操作全程不需要加锁是因为Node的成员val是用volatile修饰的和数组用volatile修饰没有关系。 数组用volatile修饰主要是保证在数组扩容的时候保证可见性。
没空看:
❤️集合很简单?开什么玩笑?肝了一周,全是精华,万字讲解!面试再不怕集合问题了!!!❤️:
❤️集合很简单?开什么玩笑?肝了一周,全是精华,万字讲解!面试再不怕集合问题了!!!❤️_程序员springmeng-CSDN博客
arrayList 扩容,默认1.5 倍,没有缩容机制
![]()
(后加的)
paxos 和raft 的区别:
Paxos和Raft共识算法(一) - 知乎
![]()
![]()
cas 原理
并发编程几个特性:
- 原子性(atomicity)
- 可见性(visibility)
- 有序性
数据库事务正确执行四个要素:
- 原子性(atomicity)
- 一致性(consistency)
- 隔离性(isolation,又称独立性)
- 持久性(durability)
分布式系统中CAP 理论:以下三个只能同时满足两个。
- C(Consistency):一致性,同一时间点,所以节点的数据都是完全一致的。
- A(Availability):可用性,应该能在正常时间内,对请求进行响应。
- P(Partition-tolerance):分区容错性,分布式环境中,多个节点组成的网络应该是互相连通的,当由于网络故障等原因造成网络分区,要求仍然能够对外提供服务。
线程不安全的时候,可以使用synchronized 关键字或者Lock 锁。
https://xiaomi-info.github.io/2020/03/24/synchronized/
- synchronized 关键字由jvm 自身的机制来保障线程的安全性。
- 高并发场景下,使用lock 锁要比使用synchronized 关键字在性能上得到极大的提高。因为Lock 底层是使用AQS + CAS 机制实现的。lock 的实现是底层硬件cpu 指令。
- 使用Atomic 原子类。
AtomicInteger.incrementAndGet();
AtomicInteger.get();
底层基于CAS 乐观锁实现。
使用 volatile int value - 使用LongAdder 原子类。适用于高并发场景,特别是写大于读的场景。代价是消耗更多的空间,以空间换时间。
LongAdder 底层也是基于CAS 机制实现,LongAdder 内部维护了base 变量和Cell[] 数组,当多线程并发写的情况下,各个线程都在写入自己的Cell 中,LongAdder 操作后返回的是个近似准确的值,最终也会返回一个准确的值
(Volatile 关键字只能保证可见性 & 有序性,不能保证原子性。简单来说,线程A 读取变量a 之后被阻塞,线程B 操作完之后并刷回内存,这时候根据可见性原则,其他线程对a 就可见了。参考:volatile为什么不能保证原子性 - 简书 最后一段
另外的解释:volatile方式的i++,总共是四个步骤:i++实际为load、Increment、store、Memory Barriers 四个操作。内存屏障是线程安全的,但是内存屏障之前的指令并不是.在某一时刻线程1将i的值load取出来,放置到cpu缓存中,然后再将此值放置到寄存器A中,然后A中的值自增1(寄存器A中保存的是中间值,没有直接修改i,因此其他线程并不会获取到这个自增1的值)。如果在此时线程2也执行同样的操作,获取值i==10,自增1变为11,然后马上刷入主内存。此时由于线程2修改了i的值,实时的线程1中的i==10的值缓存失效,重新从主内存中读取,变为11。接下来线程1恢复。将自增过后的A寄存器值11赋值给cpu缓存i。这样就出现了线程安全问题。
重点:如果一个变量被volatile修饰了,那么肯定可以保证每次读取这个变量值的时候得到的值是最新的
)
原子操作:不会被线程调度机制打断的操作,这种操作一旦开始,就一直运行到结束,中间不会有线程切换的操作。(整个操作被视为一个整体)
以上参考:
一文彻底搞懂CAS实现原理 - 知乎
可以不用看链接里关于cas 原理的一部分,太底层了。
cas 原理:
一个变量简单的读取和赋值操作是原子性的,将一个变量赋值给另外一个变量不是原子性的。
一个变量赋值给另一个变量,比如说int a = b; 先把b 的值读取到寄存器内存中,然后再把该值从寄存器搬运到内存a 的地址中。
cas 被认为是一种乐观锁,乐观锁其实就是一种思想
compare and swap,其中有几个值:
valueOffset,value 变量的内存偏移地址,也就是那个要操作的变量的实际地址,举例来说,要对int a = 10;做操作,就是a 的地址。
expect,期望更新的值,也就是如果要执行a++,就是在a = 10 的基础上加1,也就是说期望更新到值是10。
update,要更新的最新值,也就是说,更新完成之后,a 的值应该是11,那么update 就应该是11。
其中value 是使用volatile 修饰保证可见性
假设内存中数据的值为V,旧的预期值为A,新的修改值为B。那么CAS操作可以分为三个步骤:
1)将旧的预期值A与内存中的值V比较;
2)如果A与V的值相等,那么就将V的值设置为B;
3)返回操作是否成功。
对于底层,使用的是总线加锁(加锁总线,效率低)或者缓存加锁(加锁某一个共享内存变量的地址)来实现原子操作。
cas 产生的问题:
- ABA 问题
原来的值为A,后来修改成了B,然后又更新成了A
解决:AtomicStampedReference,添加版本号1A -> 1B -> 2A。检查期望引用是否等于当前引用,期望的标识是否等于当前标识。 - 性能问题
采用循环的方式实现原子操作,如果长时间不成功,一直占用cpu - 只能保证对一个共享变量的原子操作
如果要保证多个变量的原子性,可以将多个共享变量封装到一个对象中,然后使用AtomicReference 类来实现原子操作。或者使用锁。
![]()
AQS (AbstractQueuesSynchronizer), 队列同步器
几个角色:很多用户(用户线程),共享资源(取药窗口)。在用户线程和共享资源之间,是通过中间系统来协调控制的,这里面就会涉及锁的概念。
锁是用来控制多个线程访问共享资源的方式。一个锁能防止多个线程对共享资源的同时访问,有些锁也允许多个线程并发访问共享资源,比如读写锁。
在 Java 中经常使用的锁是 synchronized,synchronized 会隐式的获得锁,但它必须是先获得锁再释放锁。这种方式简化了同步的管理,但扩展性不如 Lock 显示的获得锁和释放锁更加灵活。

从性能上来讲,当并发量高、竞争激烈的场景下,Lock 锁会较 synchronized 性能上表现的
更稳定些。反之,当并发量不高的情况下,synchronized 有分级锁的优势,因此两者性能差不多,synchronized 相对来说使用上更加简单,不用考虑手工释放锁。
Lock 显示的锁使用,因为使用上更加灵活,这得益于其底层基础同步框架的实现机制,它就是 AQS。

底层使用AQS 设计,抽象出来统一的同步协调处理器,作为并发包构建的基本骨架。
ReentrantLock 基于AQS 的实现(参考:https://zhuanlan.zhihu.com/p/141715040)
- aqs 是一个抽象类,以继承的方式使用,一般是其他组件实现
- 它维护了一个volatile int state(代表共享资源)和一个FIFO(双向队列)线程等待队列(多线程争用资源被阻塞时会进入此队列)
- 结合ReentrantLock 的使用,说明一下
- 在ReentrantLock类中,有一个Sync成员变量,即是继承了AQS的子类
- 这里的Sync也是一个抽象类,其实现类为FairSync和NonfairSync,分别对应公平锁和非公平锁。
- 以非公平锁为例,其lock() 方法的实现
final void lock() {if (compareAndSetState(0, 1)) // compareAndSetState底层其实是调用的unsafe的CAS系列方法setExclusiveOwnerThread(Thread.currentThread());elseacquire(1);} -
lock方法先通过CAS尝试将同步状态(AQS的state属性)从0修改为1。若直接修改成功了,则将占用锁的线程设置为当前线程
-
CAS操作未能成功,说明state已经不为0,此时继续acquire(1)操作,这个acquire()由AQS实现提供
public final void acquire(int arg) {if (!tryAcquire(arg) &&acquireQueued(addWaiter(Node.EXCLUSIVE), arg))selfInterrupt();}简单解释下: tryAcquire方法尝试获取锁,如果成功就返回,如果不成功,则把当前线程和等待状态信息构适成一个Node 节点,并将结点放入同步队列的尾部。然后为同步队列中的当前节点循环等待获取锁,直到成功。 -
通过state 累加实现“重入”的功能
多线程独占式并发工具:
1)ReentrantLock
可重入锁,同一时刻仅允许一个线程访问,所以可以称作 独占锁,线程可以重复获取同一把锁。
多线程共享式并发工具:
1)ReentrantReadWriteLock
可重入的读写锁,允许多个读线程同时进行读,但不允许写-读、写-写线程同时访问。
适用于读多写少的场景下。
底层使用AQS 实现,也是使用state 来表示锁
如何用一个共享变量来区分锁是写锁还是读锁呢?答案就是按位拆分(前16 位表示读锁,后16 位表示写锁)
由于state是int类型的变量,在内存中占用4个字节,也就是32位。将其拆分为两部分:高16位和低16位,其中高16位用来表示读锁状态,低16位用来表示写锁状态。当设置读锁成功时,就将高16位加1,释放读锁时,将高16位减1;当设置写锁成功时,就将低16位加1,释放写锁时,将第16位减1
假设锁当前的状态值为S,将S和16进制数0x0000FFFF进行与运算,即S&0x0000FFFF,运算时会将高16位全置为0,将运算结果记为c,那么c表示的就是写锁的数量
将S无符号右移16位(S>>>16),得到的结果就是读锁的数量
参考:https://zhuanlan.zhihu.com/p/91408261
2)CountDownLatch(发令枪)
主要用来解决一个线程等待 N 个线程的场景。
就像短跑运动员比赛,等到所有运动员全部都跑完才算竞赛结束。
CountDownLatch countDownLatch = new CountDownLatch(3);countDownLatch.await();countDownLatch.countDown();countDownLatch.countDown();countDownLatch.countDown();底层使用AQS,使用state 来表示计数值的大小
比如说主线程,等待所有子线程执行完成,然后继续执行
3)CyclicBarrier(同步屏障)
主要用于 N 个线程之间互相等待。
就像几个驴友约好爬山,要等待所有驴友都到齐后才能统一出发。
参考:深入浅出java CyclicBarrier - 简书
CyclicBarrier cyclicBarrier = new CyclicBarrier(3);cyclicBarrier.await();cyclicBarrier.await();cyclicBarrier.await();CountDownLatch和CyclicBarrier的区别
(01) CountDownLatch的作用是允许1或N个线程等待其他线程完成执行;而CyclicBarrier则是允许N个线程相互等待。
(02) CountDownLatch的计数器无法被重置;CyclicBarrier的计数器可以被重置后使用,因此它被称为是循环的barrier。
原文链接:https://blog.csdn.net/BThinker/article/details/104417813
4)Semaphore
限流场景使用,限定最多允许N个线程可以访问某些资源。
就像车辆行驶到路口,必须要看红绿灯指示,要等到绿灯才能通行。
Semaphore semaphore = new Semaphore(2);
semaphore.aquire();
semaphore.release();
基于上述这些并发包工具,我们可以根据多线程的不同使用场景去选择。JDK 提供的这些并发包基本能够满足了大部分的开发者的使用需求。
以上参考:通过一个生活中的案例场景,揭开并发包底层AQS的神秘面纱 - Java爱好者社区 - 博客园
linux 操作系统基础知识:
只要你认真看完一万字☀️Linux操作系统基础知识☀️分分钟钟都吊打面试官《❤️记得收藏❤️》_苏州程序大白的博客-CSDN博客
AQS 简介:通俗理解AQS原理及与Reentrantlock的关系_Lynn_coder的博客-CSDN博客_lock和reentrantlock关系
aqs 的简简单单过一遍,看里面的“过程”:AQS简简单单过一遍 - 知乎
上面两个链接配合着看
![]()
锁,可重入锁,非、共享、读写、
重入锁:到底什么是重入锁,拜托,一次搞清楚! - 知乎,可重入锁(good)-阿里云开发者社区
java可重入锁与不可重入锁_慎独-CSDN博客_重入锁
- 自旋锁
看完你就明白的锁系列之自旋锁 - 程序员cxuan - 博客园
JMM
并发编程-(4)-JMM基础(总线锁、缓存锁、MESI缓存一致性协议、CPU 层面的内存屏障) - 简书
锁类型的总结
阿里面试失败后,一气之下我图解了Java中18把锁_爱笑的架构师-CSDN博客
- 悲观锁、乐观锁(每次想操作这个数据前都会假设其他线程也可能会操作这个数据)
- 独占锁、共享锁
ReentrantReadWriteLock - 互斥锁(
互斥锁是独占锁的一种常规实现)、读写锁(读写锁是共享锁的一种具体实现)ReadWriteLock - 公平锁、非公平锁。ReentrantLock 默认非公平锁,可以设置为公平锁。Synchronized 是非公平锁。
- 可重入锁。
可重入锁又称之为递归锁,是指同一个线程在外层方法获取了锁,在进入内层方法会自动获取锁。(Syn & Reentrant 都是可重入,一定程度避免死锁) - 自旋锁。
自旋锁是指线程在没有获得锁时不是被直接挂起,而是执行一个忙循环,这个忙循环就是所谓的自旋。为了减少线程被挂起的几率。
自适应自旋锁:自适应意味着自旋的时间(次数)不再固定,而是由前一次在同一个锁上的自旋时间及锁的拥有者的状态来决定。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
在自旋锁中 另有三种常见的锁形式:TicketLock、CLHlock和MCSlock
参考:自旋锁VS适应性自旋锁 - 简书 -
分段锁。
分段锁是一种锁的设计,并不是具体的一种锁。目的是将锁的粒度进一步细化,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。 -
锁升级。(无锁 | 偏向锁 | 轻量级锁 | 重量级锁)

JDK1.6 为了提升性能减少获得锁和释放锁所带来的消耗,引入了4种锁的状态:无锁、偏向锁、轻量级锁和重量级锁,它会随着多线程的竞争情况逐渐升级,但不能降级。
java 中synchronized 内部实现原理就是锁升级的过程。-
无锁,如CAS 的形式。乐观锁形式
-
偏向锁,是指它会偏向于第一个访问锁的线程。通过控制对象的标志位来实现,如果是可偏向的,判断对象头存储的现成id 是否和本线程一致。
-
轻量级锁,竞争程度变得比较激烈的时候,偏向锁就会升级为
轻量级锁,轻量级锁认为虽然竞争是存在的,但是理想情况下竞争的程度很低,通过自旋方式等待上一个线程释放锁。 -
重量级锁,如果线程并发进一步加剧,线程的自旋超过了一定次数,或者一个线程持有锁,一个线程在自旋,又来了第三个线程访问时(反正就是竞争继续加大了),轻量级锁就会膨胀为
重量级锁,重量级锁会使除了此时拥有锁的线程以外的线程都阻塞。
-
-
锁优化技术
-
锁粗化(将多个同步块数量减少,将单个同步块的作用范围加大)
-
锁消除(
锁消除是指虚拟机编译器在运行时检测到了共享数据没有竞争的锁,从而将这些锁进行消除。)
-
偏向锁:无竞争场景
轻量级锁:轻微竞争场景。自旋,稍加等待即可,无需切换线程上下文。
重量级锁:竞争大的场景。
由低到高依次升级。开销也依次增加。
无锁、偏向、轻量、重量,一个比较好的解释:无锁 VS 偏向锁 VS 轻量级锁 VS 重量级锁 - 简书
cas 和自旋的关系:https://segmentfault.com/q/1010000021946513
![]()
synchronized 和lock 选型,区别是什么
Lock比synchronized多了以下功能(Lock的优势):
- 可中断获取锁:使用synchronized关键字获取锁的时候,如果线程没有获取到被阻塞了,那么这个时候该线程是不响应中断(interrupt)的,而使用Lock.lockInterruptibly()获取锁时被中断,线程将抛出中断异常。
- 可非阻塞获取锁:使用sync关键字获取锁时,如果没有成功获取,只有被阻塞,而使用Lock.tryLock()获取锁时,如果没有获取成功也不会阻塞而是直接返回false。
- 可限定获取锁的超时时间:使用Lock.tryLock(long time, TimeUnit unit)。
- 同一个锁对象上可以有多个等待队列(Conditin,类似于Object.wait())。
当然,Lock也不是完美的,否则java就不会保留着synchronized关键字了,显示锁的缺点主要有两个:
- 使用比较复杂,这点之前提到了,需要手动加锁,解锁,而且还必须保证在异常状态下也要能够解锁。而synchronized的使用就简单多了。
- 效率较低,synchronized关键字毕竟是jvm底层实现的,因此用了很多优化措施来优化速度(偏向锁、轻量锁等),而显示锁的效率相对低一些。
由于synchronized是JVM实现的,因此JVM可以对其一些优化,比如Java 1.6为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁”,在Java SE 1.6中,锁一共有4种状态,级别从低到高依次是:无锁状态、偏向锁状态、轻量级锁状态和重量级锁状态,这几个状态会随着竞争情况逐渐升级。锁可以升级但不能降级,意味着偏向锁升级成轻量级锁后不能降级成偏向锁。这种锁升级却不能降级的策略,目的是为了提高获得锁和释放锁的效率。
参考:https://www.zhihu.com/question/429967101/answer/1575770226
![]()
布隆过滤器:5 分钟搞懂布隆过滤器,亿级数据过滤算法你值得拥有! - 掘金
![]()
mesi 一致性协议,缓存一致性协议,总线加锁机制
- 缓存一致性协议
每个cpu 是独立工作的,那么就会存在一个问题,每个cpu 对应的cache 与内存之间的数据同步该怎么做。缓存一致性协议就是为了解决这个问题。
协议分为两类:“窥探”协议和“基于目录”的协议。
缓存一致性协议就是一个状态机。
缓存一致性机制就整体来说,是当某块CPU对缓存中的数据进行操作了之后,就通知其他CPU放弃储存在它们内部的缓存,或者从主内存中重新读取 - mesi 一致性协议是缓存一致性协议的一种实现。属于窥探型协议。
窥探协议的思想是,cache 不但在与内存通信时和总线打交道,而且它会不停地窥探总线上发生的数据交换,跟踪其他cache 在做什么。所以当一个cpu 去读写内存时,其他cpu 都会得到通知,以此来使自己的cache 保持同步。
mesi 来自四个状态的首字母缩写。
(1) invalid(失效),表明该cache line 已失效,要么不在cache 中,要么就已经过时
(2) shared(共有),表明该cache line 是内存中某一段数据的拷贝,处于该状态的只能被cpu 读取,不能写入,因为此时还没有独占。不同的cpu 的cache line 都可以拥有这段内存数据的拷贝。
(3) exclusive(独有),表明该cache line 是某内存中某一段数据的拷贝。该cache line 独占该内存地址,其他处理器的cache line 不能同时拥有它,如果其他处理器原本持有同一cache line,那么它马上会变成invalid 状态
(4) modified(修改),表明该cache 已经被修改,该缓存与主存的值不同。如果别的cpu 内核要读主存这块数据,该缓存必须写回到主存,状态变为共享。
mesi 一致性协议就是缓存一致性协议的一种,以上参考:缓存一致性协议的工作方式 - 知乎
M:被修改的。处于这一状态的数据,只在本CPU中有缓存数据,而其他CPU中没有。同时其状态相对于内存中的值来说,是已经被修改的,且没有更新到内存中。
E:独占的。处于这一状态的数据,只有在本CPU中有缓存,且其数据没有修改,即与内存中一致。
S:共享的。处于这一状态的数据在多个CPU中都有缓存,且与内存一致。
I:无效的。本CPU中的这份缓存已经无效。
以上参考:总线锁、缓存锁、MESI_张花生的博客-CSDN博客_缓存锁
另外一个mesi 几种状态介绍及状态切换的文章:带你了解缓存一致性协议 MESI
《带你了解缓存一致性协议 MESI》
这个写的也很清楚,先看这个,再看上面的那个:【并发编程】MESI--CPU缓存一致性协议 - 风动静泉 - 博客园
- 总线加锁机制:当某个cpu 要对主内存中的数据做操作时,在总线上加锁,发出lock 信号,其他处理器就不能操作缓存了该共享变量内存地址的缓存,阻塞了其他cpu,使得该处理器可以独享此共享内存。
关于mesi 还可以参考:缓存一致性协议(MESI) - 一念永恒乐 - 博客园
内存屏障(自己找的)
(这个写的太多了,有时间再看吧:内存屏障(Memory Barrier)究竟是个什么鬼? - 知乎)
volatile 保证可见性:缓存一致性协议。
- 将当前处理器缓存的数据刷新到主内存。
- 刷新到主内存时会使得其他处理器缓存的该内存地址的数据无效。
volatile 保证有序性:通过插入内存屏障来禁止指令重排序。
内存屏障:内存屏障是一种CPU指令,它的作用是对该指令前和指令后的一些操作产生一定的约束,保证一些操作按顺序执行。
参考:面试官:请说下volatile的实现原理 - 知乎,写的清晰。
什么是状态机:什么是状态机? - 知乎
状态机就是一个数学模型,通常体现为状态转换图。四个状态:State, Event, Action, Transition.
![]()
线程通信
线程同步机制
- 互斥
- 临界值
- 信号量
- 事件通知
几个场景
- 两个线程依次执行:
使用join 方法。join 中文:连接,结合,加入。
在ThreadB 的run() 方法中,ThreadA.join()。这样A 线程就会先于B 中的执行逻辑去先执行。 - 让两个线程按照指定方式交叉有序运行:
使用一个共享锁对象,Object lock = new Object();
开始每个线程都需要抢得这个对象锁:synchronized(lock),然后
线程A 执行lock.wait(); 此时释放lock 锁,然后线程B 获得此锁。
线程B 执行完成之后,执行lock.notify(); 释放锁,唤醒正在等待的线程A,然后继续执行。 - 四个线程A,B,C,D,需要D 等待A,B,C 都执行完成之后再执行:
使用CountDownLatch
在主线程中创建此对象
在等待线程D 中调用countDownLatch.await() 方法,进入等待状态,直到计数值变为0
在其他线程里调用countDownLatch.countDown() 方法,该方法会将计数值减少1
当计数值变为0 时,等待线程中的await() 方法立即退出 - 三个线程各自准备,等到都准备好后,一起执行:
使用CyclicBarrier 数据结构(cyclic 循环的;barrier 障碍物)
首先创建一个对象:CyclicBarrier cb = new CyclicBarrier(3); 参数为n(3)个线程的个数
然后这些线程同时开始自身做准备,自身准备完毕后,需要等待别人准备完毕,每个线程中调用cb.await(); 即可开始等待别人
当所有线程都调用了await() 方法之后,意味着所有线程都准备完成,然后这些线程就都可以同时执行了。 - 子线程完成某件任务之后,把得到的结果返回给主线程:
正常线程创建的时候,我们会把Runnable 对象传给Thread 去执行,但是不会返回任何结果。
如果希望返回结果,使用Callable 接口。配合FutureTask 使用。
new FutureTask(callable);
new Thread(futureTask).start();
获取结果使用futureTask.get(); 但是get() 方法会阻塞主线程。
参考:Java 如何线程间通信,面试被问哭。。。 - 知乎
Thread 的start 和run 方法的区别:
start()方法来启动线程,真正实现了多线程运行,这时无需等待。
run()只是一个普通方法,程序还是要顺序执行,还是要等待run方法体执行完毕后才可继续执行下面的代码。还是只有主线程这一个。
调用start方法方可启动线程,而run方法只是thread的一个普通方法调用,还是在主线程里执行。
Java Thread 的 run() 与 start() 的区别 - 灰色飘零 - 博客园
Thread.sleep(0) 的作用:触发一次操作系统的重新竞争
参考:Sleep(0)的妙用_HawkJony的博客-CSDN博客_sleep
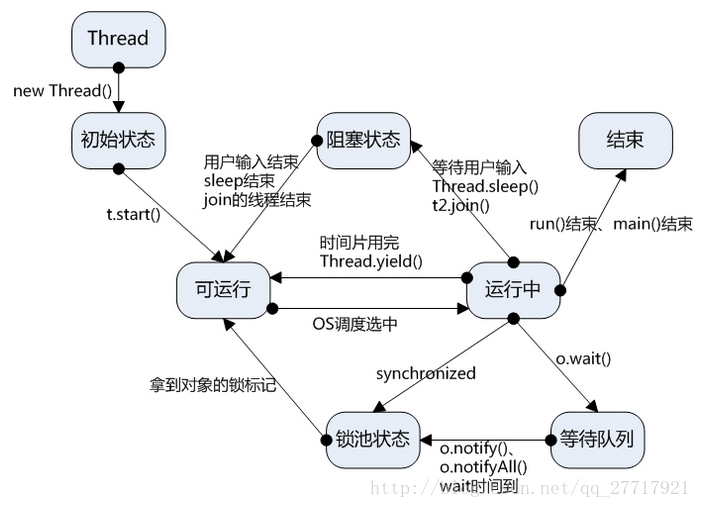
线程切换状态,参考:Java多线程--线程各状态如何进行切换_哆啦咪~fo-CSDN博客_线程切换过程
Thread.sleep() 和Objects.wait() 的区别
- Thread 和Object
- 锁的释放。thread 不挂起,只是阻塞中,过了这段时间继续处于“可运行”;wait 直接进入等待队列,必须notify
- 打断,Thread使用interrupt,wait 使用notify
- 必须捕获异常、必须同步块中使用(因为lost wake up 问题,参考:Java中wait()方法为什么要放在同步块中? - 知乎,写的不错)
参考:Java中sleep()和wait()的区别 - 簡書
![]()
线程池
ExecutorService 可以执行Runnable 和Callable 任务。
任务创建完成,可以使用多种方法提交任务到ExecutorSerivice 中去。
- Future<String> future = executorService.submit(callableTask);
使用submit() 方法,返回Future 类型的结果 - 使用execute() 方法,不会返回任何值。
- invokeAny(),是分配一组任务到executorService,每个任务都执行,并返回任意一个执行成功的任务结果(如果成功执行)
String result = executorService.invokeAny(callableTasks); - invokeAll() 方法,任务列表,每个任务都会执行,并以Future 类型对象列表的 形势返回所有执行任务的结果。
List<Future<String>> futures = executorService.invokeAll(callableTasks);
ExecutorService 的停止:
- shutdown() 方法,停止接受任何新任务,等待目前所有任务执行完成之后关闭。
executorService.shutdown();
- shutdownNow() 方法,立刻停止,销毁ExecutorService 实例,返回待处理的任务列表,由开发人员自行决定怎么处置。
List<Runnable> notExecutedTasks = executorService.shutDownNow();
因为提供了两个方法,所以最佳实战就是同时使用这两种方法,并结合awaitTermination() 方法。
executorService.shutdown();
try {if (!executorService.awaitTermination(800, TimeUnit.MILLISECONDS)) {executorService.shutdownNow();}
} catch (InterruptedException e) {executorService.shutdownNow();
}Future 接口
Future 接口的对象允许我们获取任务执行的结果或检查任务的状态(正在运行还是执行完毕)
Future 接口的get() 方法,是阻塞的。如果是Callable 任务,则返回结果;如果是Runnable 任务,则返回null。
因为get() 方法是阻塞的,如果调用get() 方法的时候任务还一直在运行,那么调用将会一直被阻塞,直到任务执行完成并返回结果之后才返回。
get 方法可能会导致程序可用性降低,所以可以设置超时时间,避免长时间阻塞。如果超过,那么抛出TimeoutException 异常。
除了get 方法,还有isDone(),cancel(),isCanceled()
ScheduledExecutorService 接口
用于在预定义的延迟之后运行任务或者定期执行任务
- 固定延迟后安排单个任务执行,用schedule 方法。
- 固定延迟后,定期执行任务,用scheduleAtFixedRate() 方法。
- 任务迭代之间,必须有固定长度的延迟,用scheduleWithFixedDelay() 方法。
以上关于ExecutorSerivce 来自:
一文秒懂 Java ExecutorService - Java 一文秒懂 - 简单教程,简单编程
ThreadPoolExecutor
是一个可被继承的线程池实现。
对于ThreadPoolExecutor 的实例化,其中有几个主要的参数:
public ThreadPoolExecutor(int corePoolSize, int maximumPoolSize, long keepAliveTime, TimeUnit unit, BlockingQueue<Runnable> workQueue, ThreadFactory threadFactory, RejectedExecutionHandler handler);- corePoolSize: 线程池核心线程的数量;
- maximumPoolSize: 线程池可创建的最大线程数量;
- keepAliveTime: 当线程数量超过了corePoolSize指定的线程数,并且空闲线程空闲的时间达到keepAliveTime 该线程就会被销毁,如果调用过allowCoreThreadTimeOut(boolean value)方法允许核心线程过期,那么该策略针对核心线程也是生效的;
- unit: 指定了keepAliveTime的单位,可以为毫秒,秒,分,小时等;
- workQueue: 存储未执行的任务的队列;
- threadFactory: 创建线程的工厂,如果未指定则使用默认的线程工厂;
- handler: 指定了当任务队列已满,并且没有可用线程执行任务时对新添加的任务的处理策略;
调度策略:
- 如果当前池中线程数小于核心线程数,每来一个任务,都会创建一个线程,无论当前是否有空闲线程。
- 如当前执行任务线程数量达到了corePoolSize 指定线程数时,就是没有空闲的核心线程时,新来的任务会置入worekQueue 中。
- 如果workQueue 任务已满,若此时来了新任务,那么线程池会创建新线程执行任务。
- 如果所有线程(maximum 数量对应的都在执行任务),队列也满了,对于新添加的任务,就使用handler 所指定的方式对其进行处理。
需要了解内容:
- 四种工具类。
FixedThredPool: new ThreadExcutor(n, n, 0L, ms, new LinkedBlockingQueue<Runable>() SingleThreadExecutor: new ThreadExcutor(1, 1, 0L, ms, new LinkedBlockingQueue<Runable>()) CachedTheadPool: new ThreadExcutor(0, max_valuem, 60L, s, new SynchronousQueue<Runnable>()); ScheduledThreadPoolExcutor: ScheduledThreadPool, SingleThreadScheduledExecutor. - 区别。
- 创建线程池的参数
如上,其中如果maximumPoolSize 设置大于corePoolSize 会报错,illegalArguementException - 线程池队列的实现,工作队列,工作队列类型,分围阻塞、非阻塞的
workQueue 有三种类型:
(1)ArrayBlockingQueue,有界阻塞队列
(2)LinkedBlockingQueue,无界阻塞队列(可以指定界限),理论上是无界的,实际上是Integer.MAX_VALUE 个任务
由于此队列是无法存满的,所以maxPoolSize 的设定没有意义,一般会设定和core 的一样。
(3)SynchronousQueue,同步队列,其内部没有任何存储结构用来存储任务。当一个任务被添加到该队列时,当前线程和后续线程都会被阻塞,直到有一个线程从该队列中取出任务,该线程才会被释放。所以一般corePoolSize 比较小,maximumPoolSize 比较大,因为该队列适合大量且执行时间比较短的任务的执行。 - 拒绝策略
当线程中任务队列已满,并且线程池中线程数目达到了maximumPoolSize 时,如果还有任务到来,就会采取任务拒绝策略。
(1)DiscardPolicy,丢弃任务,不抛异常。
(2)DiscardOldestPolicy,丢弃最前面的任务,然后重新提交被拒绝的任务。
(3)AbortPolicy,拒绝且抛异常RejectExecutionException 异常。(默认的)
(4)CallerRunsPolicy,由调用的线程(提交任务的线程)处理该任务。
第一种和第二种一般不会配合synchronousQueue 使用,因为当同步队列阻塞了任务时,任务都会被抛弃。
对于第三种,如果队列已满,那么就会抛出异常,使用时要小心
对于第四种,要注意对服务器的影响。
以上参考:ThreadPoolExecutor详解 - 知乎
一文秒懂 Java 线程池之 ThreadPoolExecutor - Java 一文秒懂 - 简单教程,简单编程
介绍的比较好的文章:
Java线程池面试必备:核心参数、工作流、监控、调优手段
![]()
redis 实现分布式锁。
参考:再有人问你分布式锁是什么,就把这个丢给他! - 知乎
使用分布式锁,是分布式系统中互斥访问共享资源的一种方式
分布式锁的问题
非集群的时候:
- SETNX 和 EXPIRE 非原子性。使用setnx 命令,expire 命令,非原子性,可能超时时间没有设置成功,造成死锁问题
(如:使用lua 脚本完成。redis 使用同一个lua 解释器来完成) - 锁误解除。线程A 获取了锁,设置30s 过期时间,没执行完,释放;随后线程B 获取了锁;A 之后执行完成,A 使用del 命令释放了锁。
(通过在value 中设置当前线程的加锁标识,删除之前验证key 对应的value 是否是当前线程持有的,可以使用UUID 标识当前线程,使用lua 脚本保证做验证标识和解锁操作) - 超时解锁导致并发。线程A 获取锁,执行超时;之后B 获取锁;线程A 和线程B 并发执行。
(过期时间足够长;为获取锁的线程增加守护线程,为将要过期但未释放的锁增加有效时间) - 不可重入
(Redis Map 数据结构来实现分布式锁,既存锁的标识也对重入次数进行计数) - 无法等待锁释放。上述命令执行都是立即返回的,如果客户端可以等待锁释放就无法使用。
(客户端轮询;使用 Redis 的发布订阅功能,当获取锁失败时,订阅锁释放消息,获取锁成功后释放时,发送锁释放消息。
集群:
- 主备切换。A 线程于主节点加锁成功,还没同步到从节点,主节点挂掉;从节点被提升为主节点,没有锁的数据,B 线程加锁成功。
- 集群脑列。因为网络问题,master 节点、slave 节点、sentinel 集群处于不同的网络分区;sentinel 无法感知到master 的存在,所以将slave 节点提升为master 节点。当客户端连接了不同的master,两个线程拥有同一把锁。
实现可以使用jedis 的一个函数:jedis.set(String key, String value, String nxxx, String expx, int time)
第三个参数nxxx:把key、value set到redis中
nx : not exists, 只有key 不存在时才把key value set 到redis
xx : is exists ,只有 key 存在是,才把key value set 到redis
第四个参数expx:参数有两个值可选 :
ex : seconds 秒
px : milliseconds 毫秒
参考:jedis set 的四个重载方法(byte[]的四个自动忽略)
以上参考:分布式锁的实现之 redis 篇 | 小米信息部技术团队
Redisson 的原理
reids 发布订阅模式:订阅与发布 — Redis 设计与实现
加锁:
- 加锁使用的lua 脚本。
- 其他线程尝试获取锁的方式不是while 循环,利用发布订阅机制解决无效的锁申请浪费资源的问题。
- 提供了锁的续期机制,只要客户端1 一旦加锁成功,就会启动一个Watch Dog。而如果想开启,必须使用默认的加锁时间30s,否则锁一过期就会释放。
watchDog 机制就是后台定时任务线程,如果获取锁成功之后,会将持有锁的线程放入到一个map 里面,每隔10s 检查一下,遍历map里面线程 id 然后根据线程 id 去 Redis 中查,如果存在就会延长 key 的时间。
如果服务器宕机,watchDog 机制失效。 - 可重入机制,使用的是key-> map 结构。这个hash 锁结构的key 是锁的名称,field 是客户端id,value 是加锁的次数。
删除锁步骤:
- 删除锁(注意可重入锁的逻辑,上面的那个value 一次次减一)
- 广播释放锁的消息(向某个通道发送unlock_message 消息)
- 取消watchDog 机制(删除map 里面的线程id,并且cancel 掉netty 的定时任务线程)
缺点:master 宕机问题;脑裂问题。
以上参考:Redisson 实现分布式锁原理分析 - 知乎
redis 发布订阅机制:

发布者和订阅者都是Redis客户端,Channel则为Redis服务器端,发布者将消息发送到某个的频道,订阅了这个频道的订阅者就能接收到这条消息。
没有持久化,没有消息保障机制
参考:Redis学习汇总:Redis发布订阅机制,面试必知必会! - 知乎
网上比较流行的做法是,setnx + lua 脚本,而在分布式系统中,使用主从结构,就有可能造成脑裂,对于cap 满足了ap 不能满足c。
RedLock
redlock 需要多个实例,但都是独自部署,没有主从结构。避免redis 异步复制造成的锁丢失问题。
红锁加锁:
- 只要N/2 + 1 个节点加锁成功,那么就认为获取锁成功
- 获取当前时间,毫秒为单位。
- 顺序向五个节点请求加锁。获取锁时,客户端设置一个网络连接时间和响应超时时间,这个响应超时时间应该小于锁的失效时间。例如你的锁自动失效时间为10秒,则超时时间应该在5-50毫秒之间。这样可以避免服务器端Redis已经挂掉的情况下,客户端还在死死地等待响应结果。如果服务器端没有在规定时间内响应,客户端应该尽快尝试另外一个Redis实例。
- 根据一定的超时时间来推断是不是跳过该节点
- 三个节点加锁成功并且花费时间小于锁的有效期,认定加锁成功
- 取到了锁之后,key的真正有效时间(锁的超时过期时间)等于有效时间(如30s)减去获取锁所使用的时间(如2s)
- 如果获取失败,客户端应该在所有redis 实例上进行解锁(即使有些redis 实例没有加锁成功)
红锁释放锁:
- 客户端向所有Redis节点发起 释放锁 的操作,不管这些节点当时在获取锁的时候成功与否
红锁的问题:
假设有A B C D E 五个节点:
- 客户端1成功锁住了A, B, C, 获取锁 成功(但D和E没有锁住)。
- 节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
- 节点C重启后,客户端2锁住了C, D, E, 获取锁 成功。
这样客户端1 和2 针对统一资源都获取了锁。
针对上述问题,AOF 1s 同步一次,最坏情况下丢失1s 的数据;可以设置fsync 同步数据,性能会下降,但是由于系统问题,仍然可能丢失数据。
提出延迟重启功能,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
==============================================
大神的争论:关于Redis RedLock算法的争论 | 码农网
还可能存在的问题:client1 获取锁之后,发生了full GC,超过expire time,然后client2 获取了锁,进行写数据。然后client1 苏醒过来,也进行了写数据,导致问题。(不仅FGC,其他导致系统停顿,比如说IO或者网络的堵塞或波动等)
解决:设置一个token,获取锁的时候给到,在提交改数据的时候,判断token 是否小于上一次提交修改的token,小于则拒绝。(这样就不需要分布式锁了)
==============================================
三种实现redis 锁的简介:细说Redis分布式锁:setnx/redisson/redlock?了解一波? - 知乎
红锁介绍:分布式锁之(RedLock)红锁_Forest24的博客-CSDN博客_redlock分布式锁
![]()
redis 基础知识
redis 命令不区分大小写,key 严格区分大小写
最大运输key 大小512M
redis 的五种基本类型
string、hash、list、set、zset
string 的基本命令:
redis 127.0.0.1:6379> SET runoob "菜鸟教程" OK redis 127.0.0.1:6379> GET runoob "菜鸟教程"
hash 的基本命令:
redis 127.0.0.1:6379> HMSET runoob field1 "Hello" field2 "World" "OK" redis 127.0.0.1:6379> HGET runoob field1 "Hello" redis 127.0.0.1:6379> HGET runoob field2 "World"
list 的基本命令:

lpush 左边插
rpush 右边插
lset 是有index 的,做替换处理
lrem key "hello" 删除key 代表的list 中相同元素"hello"
set 的基本命令:
redis 的set 是无需的string 类型的集合
底层是通过哈希表实现的,添加、删除、查找时间复杂度都是O(1)
集合中最大的成员数为 232 - 1(4294967295, 每个集合可存储40多亿个成员)。

redis 127.0.0.1:6379> DEL runoob redis 127.0.0.1:6379> sadd runoob redis (integer) 1 redis 127.0.0.1:6379> sadd runoob mongodb (integer) 1 redis 127.0.0.1:6379> sadd runoob rabbitmq (integer) 1 redis 127.0.0.1:6379> sadd runoob rabbitmq (integer) 0 redis 127.0.0.1:6379> smembers runoob
zset 的基本命令
和 set 一样也是string类型元素的集合,且不允许重复的成员。
每个元素都会关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
zset的成员是唯一的,但分数(score)却可以重复。
zadd key num1 value1 num2 value2 添加元素,其中num数值用于排序,value才是真正的元素,num相同时以元素字典顺序排
zrange key start end [withscores] 返回索引范围内的元素,加上withscores后会连同分数一起返回
zrevrange key start end [withscores] 逆序返回元素,其它同zrange
zrem key member 删除元素
zcard key 返回元素个数
zcount key min max 分数在min和max之间的成员的个数
Redis系列 |(一)六种基本数据结构-腾讯云开发者社区-腾讯云
redis 过期机制
定期删除(随机取一些,判断是否过期。但是如果太多了,也删不过来)
惰性删除(client 在访问key 的时候,判断是否过期,如果过期了就删除,同时不会将结果返回客户端)
redis 内部删除过期key 的机制:「定期删除」+「惰性删除」两者配合的过期策略
问题:假如有些key 既过期也没有客户端访问,还是会导致内存耗尽,这时候就要使用内存淘汰机制了
内存淘汰机制:
内存耗尽,则自动触发该机制,选取key 删除
淘汰策略、阈值可配置
在持久化的过程中,过期的不会进入到持久化文件中;数据恢复过程中,AOF 会对过期的数据增加del 命令。
内存淘汰机制的几种(有六种,分类1 个,2 个,3 个):
- noeviction:如果已满则新写入的会报错。默认策略

- allkeys-lru:最近最少使用的key移除(Least Recently Used)(建议的)
- allkeys-random:随机移除key
-
volatile-lru:在设置了过期时间的key中,移除最近最少使用的key

-
volatile-random:在设置了过期时间的key中,随机移除key
-
volatile-ttl:在设置了过期时间的key中,将最早过期的key移除(ttl:time to live)
以上参考:掘金
题外话:
lru 最近最少未使用算法实现举例:
- 使用双向链表(doubly linked list),O(1) 时间增删改元素
- 使用hash 表,O(1) 时间查找元素。map 是<key, Node>
最近最久未使用算法(LRU)介绍与实现 - 知乎
redis 数据类型底层结构
reids 所有数据结构都是由redisObjects 包装的。
里面包含几个内容
- 对外的对象类型展示,如hash、list、set
- 内部编码类型,如int、raw、embstr
- LRU 计时时钟
- 引用计数器
- 指向数据的指针
- 具体数据。如果数据比较小,则空间连续;否则不连续

可以参考这个看看看:redis的embstr为什么是39B | 笔记本
-
如果存储是long 类型的数字,使用int 类型编码
如果小于等于39 字节,使用embstr 类型编码
如果大于39 字节,使用sds 数据结构,使用raw 类型编码(后来版本改为了44 字节)
下面这个是3.2 之前的结构
len -> key 对应的value 的长度struct sdshdr {int len;int free;char buf[]; }
free -> free指存储字符串数组buf的剩余空间(未使用字节数)
buf的长度为len+free+1
使用sds 的好处:
1)使用len、free,相比于c 字符串,时间复杂度O(1)
2)对上层暴露的是buf 的指针,同时sds 也兼容对c 字符串的各种操作
3)解决二进制安全问题。用“\0”表示字 符串的结束,如果字符串中本身就有“\0”字符,字符串就会被截断。
对于实际存储数据的buf 空间管理:
空间预分配
扩大的时候,2倍;超过1M,则预分配1M,结果buf 当前长度 + 1M +1
惰性空间回收
当 SDS 的 API 需要缩短 SDS 保存的字符串时, 程序并不立即使用内存重分配来回收缩短后多出来的字节, 而是使用 free 属性将这些字节的数量记录起来, 并等待将来使用。
而这个sds 的结构,len & free 都是4 字节,浪费空间
所以用sdshdr5、sdshdr8/16/32/64 来存储
参考:掘金
这个参考也行:https://segmentfault.com/a/1190000014935345
其中,源码里面:
1字节 uint8_t
2字节 uint16_t
4字节 uint32_t
8字节 uint64_t
-
list
是有序可重复列表- 列表对象的编码可以是 ziplist 或者 linkedlist 。
- 列表对象保存的所有字符串元素的长度都小于 64 字节并且保存的元素数量小于 512 个,使用 ziplist 编码;否则使用 linkedlist;
-
hash
- 哈希对象的编码可以是 ziplist 或者 hashtable 。
- 哈希对象保存的所有键值对的键和值的字符串长度都小于 64 字节并且保存的键值对数量小于 512 个,使用ziplist 编码;否则使用hashtable
-
set
- 集合对象的编码可以是 intset 或者 hashtable 。
- 集合对象保存的所有元素都是整数值并且保存的元素数量不超过 512 个,使用intset 编码;否则使用hashtable;
-
zset
- 有序集合的编码可以是 ziplist 或者 skiplist
- 有序集合保存的所有元素成员的长度都小于 64 字节并且元素数量小于 128 个,使用 ziplist 编码;否则使用skiplist
以上参考:https://segmentfault.com/a/1190000040102333
介绍的是不同数据结构的基本介绍
几个重要的数据结构:
sds
ziplist。是个压缩列表,包含几个元素:压缩列表占用字节数;最后一个元素距离压缩列表起始位置偏移量,用于快速定位到最后一个节点;元素个数;元素内容列表;压缩列表结束标识
skiplist。跳表。关键词:多级索引,
比红黑树高效的地方:查找区间内所有元素
以上参考:Redis数据结构底层实现 - 米扑博客
有序集合的实现方式
元素数量小于128 个,同时每个元素长度小于64 字节,使用ziplist
不满足以上两个条件就会使用跳表,具体是组合了map 和skiplist
- map用来存储member到score的映射,这样就可以在O(1)时间内找到member对应的分数
- skiplist按从小到大的顺序存储分数
- skiplist每个元素的值都是[score,value]对
总结一下跳表原理:
- 每个跳表都必须设定一个最大的连接层数MaxLevel
- 第一层连接会连接到表中的每个元素
- 插入一个元素会随机生成一个连接层数值[1, MaxLevel]之间,根据这个值跳表会给这元素建立N个连接
- 插入某个元素的时候先从最高层开始,当跳到比目标值大的元素后,回退到上一个元素,用该元素的下一层连接进行遍历,周而复始直到第一层连接,最终在第一层连接中找到合适的位置
redis中skiplist的MaxLevel设定为32层
skiplist原理中提到skiplist一个元素插入后,会随机分配一个层数,而redis的实现,这个随机的规则是:
- 一个元素拥有第1层连接的概率为100%
- 一个元素拥有第2层连接的概率为50%
- 一个元素拥有第3层连接的概率为25%
- 以此类推...
为了提高搜索效率,redis会缓存MaxLevel的值,在每次插入/删除节点后都会去更新这个值,这样每次搜索的时候不需要从32层开始搜索,而是从MaxLevel指定的层数开始搜索
插入的过个:
(这个拿不准)
其中map 存的是value -> score score -> value的映射。在zset 做插入操作的时候
(应该是score -> value 的映射,socore 可重复,value 不可以重复。set 结构)
zadd [zset name] [score] [value]:
- 在map中查找value是否已存在,如果存在现需要在skiplist中找到对应的元素删除,再在skiplist做插入
- 插入过程也是用score来作为查询位置的依据,和skiplist插入元素方法一样。并需要更新value->score的map
如果score一样怎么办?根据value再排序,按照顺序插入
参考:掘金
持久化方式,区别
rdb 是快照,把当前数据持久化到硬盘
aof 是将每次执行的写命令保存到硬盘(类似于 MySQL 的 binlog)
Redis 高可用特性之 “持久化” 详解
aof 流程:Redis中的AOF工作流程_姜秀丽的博客-CSDN博客
这个链接里的内容比较好:Redis持久化机制详解 | JavaGuide(Java面试 + 学习指南)
redis 集群, 哈希槽是redis 集群的实现方式,官方集群,一个数据分片,
redis 剩下的几种类型,HyperLogLog、Geo、BloomFilter
HLL 提供不精确的去重计数
redis 为什么快
基于内存
单线程
io 多路复用
Redis 内置了多种优化过后的数据结构实现,性能非常高。
讲讲 reids 2.5 支持的事务,伪事务,原理
MULTI 执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当 EXEC 命令被调用时, 所有队列中的命令才会被执行。
通过调用 DISCARD , 客户端可以清空事务队列, 并放弃执行事务。
watch 命令,监视一个(或多个)key,如果在事务执行之前这个(或多个)key被其他命令所改动,那么事务将被打断
WATCH命令可以被调用多次。 对键的监视从 WATCH 执行之后开始生效, 直到调用 EXEC 为止。
当 EXEC 被调用时, 不管事务是否成功执行, 对所有键的监视都会被取消。另外, 当客户端断开连接时, 该客户端对键的监视也会被取消。
watch 机制的作用,如果没有watch 某个键,有可能造成“不可重复读”,同时最终的结果也不一致。
实现原理:存在一个watched_keys 字典,key 是监视的键,value 是监视这个键的客户端链表。WATCH 命令的作用, 就是将当前客户端和要监视的键在 watched_keys 中进行关联。
unwatch,取消 WATCH 命令对所有 keys 的监视
事务中的错误:
- 执行exec 命令之前,入队的命令可能会出错,如语法错误,内存不足等
对入队失败的情况做记录,执行exec 的时候拒绝执行并放弃这个事务
全体连坐(某一条操作记录报错的话,exec 后所有操作都不会成功)
- 执行exec 命令之后失败,比如处理了错误类型的键。比如将列表命令用在了字符串的key 上面。
即使事务中有某个/某些命令在执行时产生了错误, 事务中的其他命令仍然会继续执行。
冤头债主(示例中 k1 被设置为 String 类型,decr k1 可以放入操作队列中,因为只有在执行的时候才可以判断出语句错误,其他正确的会被正常执行)
redis 事务不支持回滚。可以保持简单而快速;同时redis 认为redis 命令错误应该开发时被发现。
参考:https://segmentfault.com/a/1190000023951592#item-4
sortset 实现原理 & 优劣势
实现朋友圈功能
redis & mysql 数据一致性问题
最经典的:旁路缓存模式。
或者把读写请求放到一个队列中,完全保证一致性。
redis 相关:大厂面试官喜欢这样问Redis,双写一致性、并发竞争、线程模型,我整理好了_敖丙-CSDN博客_双写一致性面了6家大厂,我把问烂了的Redis常见面试题总结了一下(带答案)_敖丙-CSDN博客
redis 总结
https://thinkwon.blog.csdn.net/article/details/103522351
![]()
redis 集群
持久化:数据持久化为了做数据备份
主从复制:则是部署多个副本节点,多个副本节点实时复制主节点的数据,当主节点宕机的时候,有完整的副节点可以使用。也可以实现读写分离,提高访问性能。
哨兵机制:如果主节点宕机,需要自动恢复机制。通过哨兵实现。
集群:如果读请求很大,那么主从节点可能cover 住;但是如果写请求也很大,如果只有一个主节点是无法承受的,这时候就需要集群化。就是多个主从节点构成一个集群,每个节点单存储一部分数据,这样写请求也可以分散到多个主节点上,解决写压力大的问题。同时可以动态新增节点进行扩容,提升性能。
要想实现集群化,就要部署多个主节点。同时每个主节点还会有多个从节点。(承担更大的流量、数据持久化、数据复制、故障自动恢复等功能,保证集群高性能和高可用)
集群方案:
主流reids 集群化方案,可以按照是否中心化来划分。客户端分片、redis cluster 是无中心化集群方案,codis、Twemproxy 是中心化集群方案
- Twemproxy(pronounced "two-em-proxy")
它解决的重点就是把客户端分片的逻辑统一放到了Proxy层而已,其他功能没有做任何处理 - codis。是服务端分片方案,客户端开发者不关心,就像操作一个redis 一样。在客户端和服务端中间增加一个代理层,客户端只操作这个代理层,代理层实现了具体的请求转发规则。也即是中心化方式的集群方案。
包含的功能很多:请求转发、在线数据迁移、节点缩容扩容、故障自动回复。
codis 把整个集群预先划分为1024 个槽位,根据key 的hash 值进行取模,找到redis 节点。路由信息保存在zk 中。
架构:Codis架构 - 简书 - redis cluster
使用中间一层proxy 的中心化解决方案时,对proxy 的要求很高,同时增加了性能损耗。
对于redis cluster,没采用中心化模式的proxy 方案,而是吧请求转发逻辑一部分放在客户端,一部分在服务端,它们之间互相配合完成请求处理。
redis 把请求转发逻辑放在smart client 中,所以业务开发人员也不需要自己编写转发规则。
客户端可以向任一实例发出请求,如果所需数据不在该实例中,则该实例引导客户端自动去对应实例读写数据。
Redis Cluster的成员管理(节点名称、IP、端口、状态、角色)等,都通过节点之间两两通讯,定期交换并更新。
实现方案比较重
redis 将键空间氛围2^14 个槽位,每个节点负责其中的一部分
(这个写的比较细,没看,有空可以看看:redis主从复制下哨兵模式---选举原理(转载)_zhaoquanwei2018的博客-CSDN博客_redis哨兵模式投票原理)
- 客户端分片。客户端制定路由规则,去对不同的节点进行读写。
事先预估数据量,部署方便,扩容迁移成本高。
是否中心化是指客户端访问多个Redis节点时,是直接访问(去中心化)还是通过一个中间层Proxy(中心化方案)来进行操作。
参考:Redis集群方案对比:Codis、Twemproxy、Redis Cluster - 云+社区 - 腾讯云
主从同步机制
Redis 的主从结构可以采用一主多从或者级联结构,Redis主从复制可以根据是否是全量分为全量同步和增量同步。
- 全量同步
Redis全量复制一般发生在Slave初始化阶段,这时Slave需要将Master上的所有数据都复制一份。
- 增量同步
Redis增量复制是指Slave初始化后开始正常工作时主服务器发生的写操作同步到从服务器的过程。增量复制的过程主要是主服务器每执行一个写命令就会向从服务器发送相同的写命令,从服务器接收并执行收到的写命令。
- Redis主从同步策略
主从刚刚连接的时候,进行全量同步;
全同步结束后,进行增量同步。
当然,如果有需要,slave 在任何时候都可以发起全量同步。
redis 策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步
参考:Redis 的主从同步,及两种高可用方式_cute-CSDN博客_redis主从
redis 热key 问题
监控热key
- 业务经验预估
- 客户端进行收集
- proxy 层做收集
- 抓包评估
解决
- 二级缓存,比如说把热点数据缓存到jvm 中,放到一个hashmap 中
- 备份热key 到不同的机器上。
自动处理的办法,两步:(1)自动监控(2)通知系统处理
有赞提过一个框架TMC,客户端监控热key,通知系统进行处理。
【原创】谈谈redis的热key问题如何解决 - 孤独烟 - 博客园
Redis中大key问题,热key问题的解决方案 - Code2020 - 博客园
redis 哨兵机制
哨兵的作用是监控Redis 服务器的状态,可以再master 节点下线之后,将其他slave 节点升级为master 节点。实现高可用。
多个哨兵可以监控同一个redis 节点,哨兵和哨兵之间可以相互监视。
提高redis 可用性的关键是:多副本部署 + 自动故障恢复。多副本部署依赖主从复制。
哨兵是redis 高可用的解决方案,它是一个管理多个redis 实例的服务工具,可以实现对redis 服务的监控、通知、自动故障转移。
哨兵是一个分布式系统,在一个架构中可以运行多个哨兵进程,这些进程使用流言协议(gossipprotocols)来接收关于Master是否下线的信息,并使用投票协议(agreement protocols)来决定是否执行自动故障迁移,以及选择哪个Slave作为新的Master.
以上来自:redis主从复制下哨兵模式---选举原理(转载)_zhaoquanwei2018的博客-CSDN博客_redis哨兵模式投票原理(这个应该看看,但是还没看完)
这个也应该看看:Redis 哨兵模式(Sentinel) 原理 - 知乎
哨兵三个任务:
监控:监控主从节点是否正常运行
选主:选出一个leader 进行主从切换
通知:选主完成后,需要把新主库的连接信息通知给从库和客户端
- 每10s 向主节点 & 从节点发送info 命令获取最新的拓扑结构图
- 每2s 通过发布/订阅模式:
- 向每个redis 节点制定频道,发送哨兵对主节点的判断 & 当前哨兵的信息
- 订阅该频道,了解其他哨兵节点的信息 & 对主节点的判断
- 每1s 哨兵向主节点、从节点及其余哨兵节点发送一次ping 命令做心跳检测
哨兵发现服务下线:
- 哨兵主观下线:ping 的时候,没回复(可能由于网络等,不可靠)
- 哨兵客观下线:当主观下线的节点是主节点时,则通过指令判断寻求其他节点的判断,当超过法定人数的时候,那么就认为的确有问题,大部分哨兵都同意下线,那么就客观下线了。
领导者哨兵选举流程:
- 每个在线的哨兵节点都可以成为领导者(如哨兵3),当确认主节点下线时,会向其他哨兵发命令,征求判断并要求自己成为领导者,由领导者处理故障转移
- 当其它哨兵收到此命令时,可以同意或者拒绝它成为领导者
- 如果哨兵3 发现自己在选举的票数大于等num(sentinels)/2+1 时,将成为领导者,如果没有超过,继续选举
服务故障处理:
- 由哨兵master 负责处理故障转移,过程等同于主从复制,但是自动执行。
- slave1 解除从节点身份,提升为主;slave2 变为new master 的从;master 恢复之后变为new master 的从
故障转移选举节点选择:
-
过滤掉不健康的(下线或断线),没有回复过哨兵 ping 响应的从节点
-
选择 slave-priority 从节点优先级最高(redis.conf)
-
选择复制偏移量最大,指复制最完整的从节点
以上参考:面试必问,redis高可用原理,哨兵机制详解 - 知乎
哨兵的工作流程主要分为以下几个阶段:
- 状态感知
- 心跳检测
- 选举哨兵领导者
- 选择新的master
- 故障恢复
- 客户端感知新master
哨兵机制概览:11.Redis哨兵面试题(高频面试题)_java程序鱼的博客-CSDN博客
(写的看来不错的文章,没时间看
Redis(五):集群:主从复制、CAP、PAXOS、cluster分片集群(一) - 知乎
Redis分布式锁是否是安全的? - 知乎
Redis主从复制、Redis哨兵模式、Redis集群 - 知乎
Redis(二)----哨兵、Twemproxy、集群 - 知乎
Redis学习总结(23)——Redis如何实现故障自动恢复?浅析哨兵的工作原理
深度剖析:Redis分布式锁到底安全吗?看完这篇文章彻底懂了! | Kaito's Blog
Redis如何实现故障自动恢复?浅析哨兵的工作原理 | Kaito's Blog
)
![]()
![]()
并发问题的起因:如何最大化利用cpu
根因:参考并发理论基础:并发问题产生的三大根源 - 知乎
-
cpu 切换导致的原子性问题
-
高速缓存的产生。高速缓存和cpu 每个核心绑定高速缓存,互相不可见
-
指令优化导致的重排序问题
![]()
列存储优势:自动索引;
![]()
四种幂等性解决方案:掘金
- 服务中获取一个分布式id,然后执行数据插入。适用于插入操作、删除操作
- 数据库乐观锁方案。表新增个字段,如version。在更新的时候,带上上次待更新的值,这样在执行更新操作的时候,就能确定更新的是某个版本下的信息。
- 防重token。调用方在调用接口的时候先向服务请求一个全局id(token),服务将此token 存入redis 中,key 为token ID,value 为用户信息。真正请求的时候携带这个token ID 一起请求,如果查询到则删除reids 中内容,然后进行后续逻辑(插入、更新、删除都可以)
- 下游传递唯一序列号,序列号短时间内唯一且不重复。下游请求传递之后,服务存这个序列号到redis 中比较,如果存在,说明已经请求过了;如果不存在,说明没有请求过。适用于插入、更新、删除。
![]()
reenterlock 和synchronize的区别
synchronized和lock的区别
(如果有时间看,讲讲实现原理)
![]()
synchronized
用来控制线程同步的,控制synchronized 代码段不被多个线程同时执行。
- synchronized(this) 以及非static 的syncoronized 方法和synchronized {...},只能防止多个线程同时执行同一个对象的同步代码段,即synchronized 锁住的是对象。
那么如果这个类中有很多个synchronized 方法,如果某个线程访问了其中一个sync 方法,那么其他线程就不能访问任何sync 方法。 - 而用在类上,或者用在static 方法上,那么锁住的就是这个类。
可以对类的所有对象实例起作用。 - 或者synchronized(Abc.class) {......}、,也是能实现全局锁的效果。
- 上面两点的意思就是:类锁指synchronize修饰的静态方法或指定锁为class对象。不同的线程,访问使用类锁的方法的时候,他们获取到的“锁”,其实是Class对象。因为同一个类中有且只有一个Class对象,但同一个类中可以有很多个其他对象。此时,就出现了同一个类中多个对象对Class对象使用的竞争,类锁则保证了在同一时间,只允许一个线程访问被类锁锁住的方法。
使用synchronized 的时候,能锁代码块就不要锁方法,尽量减少锁粒度。
synchronized 不能继承,也即父类的方法synchronized f() {} 在子类中会变成f() {}。
为什么只有static 方法加上synchronized 之后,才能实现类锁。
因为同步方法加上static关键字后,那此方法在class创建的时候,就已经初始化好了。类中所有的实例,同步使用这个方法,锁的作用范围是最大的。
对于synchronized 只有在执行完成、抛出异常或者调用wait 方法之后,才会释放锁,其他情况只能等待。
关于“类锁”参考:Java中synchronized实现类锁的两种方式及原理解析_五道口-CSDN博客,写的很清晰。
![]()
领域驱动设计:DDD
领域驱动设计(DDD):领域接口化设计
![]()
java 静态类、静态方法、静态变量
不能声明普通外层类,或者包为静态的。
static 可用于下面四种情况。
- 静态变量:可以将“类级别”的变量(类的成员变量)声明为静态的。方法中的变量不能为静态的。静态变量属于类,而不属于类创建的对象或实例。静态变量被类的所有实例公用,所以是非线程安全的。
- 静态方法:也是属于类,不属于对象实例的。静态方法只能访问类的静态变量,或调用类的静态方法。通常静态方法作为工具方法,被其他类使用,不需要创建实例。
- 静态块:是类加载器加载对象时,要执行的一组语句。
用于初始化静态变量。
静态块中不能访问非静态变量。
只会在类加载到内存中的时候执行一次。
- 静态类:只能在嵌套类使用static 关键字。static 不能用于最外层的类。
静态嵌套类和其他外层的类无区别,嵌套只是为了方便打包。
为什么外部类不能static,可以看这个:
为什么外部类不能为静态,而内部类就可以? - 知乎
内部类 & 静态类
- 只有内部类才能声明为static,也可以说是静态内部类。
- 只有静态内部类才可以定义静态变量;普通的内部类只能定义普通成员变量。
- 静态类和静态方法一样,只能访问其外部类的静态成员。
- 如果在外部类的静态方法中访问内部类,这时候只能访问静态内部类。
- 非静态内部类,可以访问外部类的静态变量。
内部类的实例化
- 内部类分为静态内部类、普通内部类
- (其他类)访问内部类,必须使用:外部类.内部类:OuterClass.InnerClass
- 普通内部类必须绑定在其外部类的实例上
- 静态内部类可以直接new
举例:
OuterClass.StaticInnerClass sic = new OuterClass.StaticInnerClass();
OuterClass oc = new OuterClass();
OuterClass.NormalInnerClass nic = oc.new NormalInnerClass();
静态对象 & 非静态对象 区别
1.拥有的区别:静态对象是不同类对象共同拥有的 ,而非静态对象是由类单独拥有;
2.内存空间区别:静态对象内存空间是固定,非静态类对象是附着相关类的分配;
3.分配顺序区别:先分配静态对象的空间,然后才会分配非静态对象也就是初始化。
一个问题:static 方法可以实例化外部类,但是不能实例化非静态内部类;同时实例化之后,可以调用非静态方法。
解:
- static 中可以创建实例,但不能访问本类的某个已有实例(除非传递进来的)
- 静态方法是不能调用非静态方法和属性,但是前提是不能调用没有实例化对象的非静态方法和属性,而new Example() 并不是一个单纯的非静态方法,它是在构建一个类对象及其初始化对象,返回的是一个对象实例,相当于对象都构建好了,非静态方法当然可以使用了。
第二个问题:在构造函数中使用this 关键字,但是往往可以看到在构造函数中使用this 的情况,而此时不是还没有实例化对象吗
- java 对象其实在构造函数开始执行之前,就已经存在了。而构造函数相当于一个赋值初始化的过程。
参考:java main方法调用类的实例化方法疑问_默默-CSDN博客
static 的“继承”问题
1)子类是不继承父类的static变量和方法的。因为这是属于类本身的。但是子类是可以访问的。
2)子类和父类中同名的static变量和方法都是相互独立的,并不存在任何的重写的关系。
参考:https://blog.csdn.net/weixin_33778778/article/details/94207336
this 和super 的区别:Java中this和super的用法总结 - codersai - 博客园
java中静态方法中为什么不能使用this、super和直接调用非静态方法
java中静态方法中为什么不能使用this、super和直接调用非静态方法 - 旧巷里的旧少年 - 博客园
![]()
分布式锁的了解:1.zk。2. redis。 3. mysql
zk 的常见使用场景:
-
服务的注册与订阅(共用节点)。
-
分布式通知(监听node)。
-
服务命名(zonde 特性)。
-
数据订阅、发布(watcher)。
-
分布式锁(临时节点)。
zk 是个数据库,存了节点。是文件存储系统,并且有监听通知机制(观察者模式)
zk 节点有四大类。持久化、持久化顺序节点(持久化顺序编号目录节点)、临时目录节点、临时编号目录节点。节点名称都是唯一的。
zk 实现分布式锁。
假设锁空间的根节点是/lock
- 客户端连接zk,并在/lock 下创建临时且有序子节点,第一个客户端创建的子节点为/lock/lock-0000000000,第二个为/lock/lock-0000000001,以此类推
2.客户端获取/lock下的子节点列表,判断自己创建的子节点是否为当前子节点列表中序号最小的子节点,如果是则认为获得锁,否则监听刚好在自己之前一位的子节点删除消息,获得子节点变更通知后重复此步骤直至获得锁
-
执行业务代码
-
完成业务流程后,删除对应的节点,释放锁
zk 提供的api 设置监听器的操作和读操作是原子执行的。这样保证在读子节点列表时同时设置监听器,保证不丢失时间。
另外的优化:假如当前有10000 个节点在等在锁,如果获得锁的客户端释放锁时,这10000 个客户端都会被唤醒,这种情况称作“羊群效应”,这种获得锁的客户端释放锁时,zk 需要通知10000 个客户端,这会阻塞其他操作,所以最好的情况应该只唤醒最小节点的客户端。所以在设置监听时,每个客户端应该对刚好在它之前的子节点设置事件监听,即需要1 的监听序号0 的
锁服务分围两类,一个是保持独占,一个是控制时序。
对于第一类,我们将zk 上的znode 看做是一个锁,所有客户端都去创建/distrbute_lock 节点,创建成功了则代表拥有了这把锁。
对于第二类,/distribute_lock 已经预先存在,所有客户端在它下面创建临时顺序编号目录节点,和选mater 一样,编号小的获得锁,用完删除。步骤:(1)在根目录下创建临时有序节点(2)获取根目录下的子目录列表,取得最小i 值(3)判断i 值是否和自己创建的一致,是则获得锁(4)如果不相等,则监听比自己小的一个节点j(4)j 节点是否存在,如果不存在,则重新获取根目录下子节点,取得最小的i 值,重复[2] 步骤。
zk 可以做到:(1)命名服务 (2)配置服务,统一配置到zk 上,然后从zk 上读配置(3)集群管理 是否有机器退出、加入,选举master(4)分布式锁(5)队列管理
并发竞争是怎么控制的。
![]()
可重入锁
在一个线程中可以多次获取同一把锁。比如,一个线程在执行一个带锁的方法,该方法又调用了另一个需要相同锁的方法,而该线程可以直接执行调用的方法(即可重入),而无需重新获得锁。
java 线程是基于“每线程”,而不是“每调用”的,也就是说,java 为每个线程分配一个锁,而不是每次调用分配一个锁。
可重入锁的原理:加锁时,需要判断锁是否已经被获取,如果已经被获取,则判断获取锁的线程是否是当前线程。如果是当前线程,则给获取次数加1,。如果不是当前线程,则需要等待。
ReentrantLock 和Synchronized 都是可重入锁。
![]()
![]()
mvcc 多版本控制。
布隆过滤器概念。
![]()
ThreadLocal
让线程自己独立保存一份自己的变量副本,每个线程都独立使用自己的线程副本。这样就不影响其他线程。
原理:每个Thread 中有个变量,threadLocalMap,其实是一个map 的结构。
key 是个Reference,是个弱引用,key 是ThreadLocal 类的实例对象,value 就是传进去的那个值。(防止gc 回收的时候无法回收)
ThreadLocal为啥要用弱引用?不知道 - 知乎
JAVA并发(3)—线程运行时发生GC,会回收ThreadLocal弱引用的key吗? - 简书
彻底搞清楚ThreadLocal与弱引用 - 知乎
有个疑问,使用弱引用,如果在线程运行的过程中,
有空可以看看这个视频:【真实工作场景】中怎么用ThreadLocal_哔哩哔哩_bilibili,没空这条不用看了。
![]()
ThreadLocal 应该实现“对于单个线程,本地化变量”,实现线程隔离。
Thread 对象中有个map,用来保存本地变量。

Thread 对象里面会有个 map,用来保存本地变量。
这个map 是ThreadLocal.ThreadLocalMap,通过开放寻址法来解决冲突。
(找不到往后移动一个位置)
ThreadLocal 为什么要用弱引用
看这个,复习一遍
https://mp.weixin.qq.com/s/76lIW4ia8D90Htoyg2NJpw
threadLocal 导致内存泄漏的原因
因为内部threadLocalMap 的声明周期和thread 一致。如果是线程池,thread 一直没被销毁,则发生泄漏。
参考:https://segmentfault.com/a/1190000022704085
![]()
四种引用,强引用、软引用、弱引用、虚引用
java 中四种引用,强引用、软引用、弱引用、虚引用。 (不是重点)
参考视频:java四种类型引用,强引用,软引用,弱引用,虚引用_哔哩哔哩_bilibili
强引用,最常见的,比如说直接创建一个对象,Object obj = new Object();。obj 就是一个强引用,在当前栈帧有效的作用于中,永远不会被回收。
软引用,SoftReference 包装。在内存有足够的空间的时候,能存活。系统内存不足的时候,垃圾回收动作到来时,它会被回收释放内存。(比如说用来当做缓存)
SoftReference<String> sr = new SoftReference(new String("abc"));
弱引用,WeakReference 包装。能活到下一次gc 之前,如果进行gc,那么一定会被回收。
WeakReference<String> sr = new WeakReference(new String("abc"));
可以当做缓存使用。
ThreadLocal 中使用,减少内存泄漏的概率。
虚引用,被phantomReference 类包装。用来跟踪对象引用被加入到队列的时刻。无法通过虚引用获取到一个对象的实例。只能搭配队列使用。
使用场景用来释放资源。用来做消息通知,释放自己。
这个示例写得好:Java中的强引用、软引用、弱引用和虚引用及其实例_爵士陈的博客-CSDN博客_软引用举例
![]()
dubbo 内部 内部使用netty、zookeeper
![]()
aio、nio,bio 的联系和区别。java 中的实现
BIO
同步阻塞的通信模式,即典型的请求——应答通信模型。 其服务端,通常由一个独立的Acceptor 线程负责监听客户端的链接,每个client 请求,创建一个线程处理请求,完成后,销毁。
NIO,non-blocking IO,也叫New IO
同步非阻塞的通信模式,客户端和服务器通过channel 通信,NIO 可以在channel 进行读写操作,这些channel 都会被注册到Selector 多路复用器上。Selector 通过一个线程不停地轮询这些Channel,找出已经准备就绪的Channel 进行操作。
即nio 通过轮询,对轮询到的事件进行处理,不需要为每个连接单独开线程处理。
nio 的三大核心为selector(选择器)、buffer(缓冲区)、channel(通道)
缓冲区buffer: 是nio 和bio 的一个重要区别。bio 是将数据直接写入或读取到Stream 对象中,而NIO 的数据操作都是在缓冲区中进行的。 通道channel: 和流不同,channel 是双向的。分为两类:一个是网络读写(SelectableChannel),一个是用于文件操作的(FileChannel)。 选择器Selector: 是NIO 编程的基础,非常重要,提供选择已经就绪的任务的能力。netty 是基于java NIO 的网络应用框架,使用netty 可以快速开发网络应用,例如服务器和客户端的协议。
io 多路复用
![]()
NIO
NIO(Non-blocking I/O,在Java领域,也称为New I/O),是一种同步非阻塞的I/O模型,也是I/O多路复用的基础,已经被越来越多地应用到大型应用服务器,成为解决高并发与大量连接、I/O处理问题的有效方式。
BIO 编程模型
{ExecutorService executor = Excutors.newFixedThreadPollExecutor(100);//线程池ServerSocket serverSocket = new ServerSocket();serverSocket.bind(8088);// 如果当前主线程没有被打断while(!Thread.currentThread.isInturrupted()){//主线程死循环等待新连接到来// 主线程一直被阻塞到这里,等待socket 的accept 事件Socket socket = serverSocket.accept();// 如果获取到accept 事件之后,则创建新线程,去执行操作。socket 作为参数executor.submit(new ConnectIOnHandler(socket));//为新的连接创建新的线程
}class ConnectIOnHandler extends Thread{private Socket socket;public ConnectIOnHandler(Socket socket){this.socket = socket;}public void run(){// 线程一直在这里进行死循环,处理读写事件while(!Thread.currentThread.isInturrupted()&&!socket.isClosed()){死循环处理读写事件String someThing = socket.read()....//读取数据if(someThing!=null){......//处理数据socket.write()....//写数据}}}
}这是一个经典的每连接每线程的模型,之所以使用多线程,主要原因在于socket.accept()、socket.read()、socket.write()三个主要函数都是同步阻塞的,当一个连接在处理I/O的时候,系统是阻塞的,如果是单线程的话必然就挂死在那里;但CPU是被释放出来的,开启多线程,就可以让CPU去处理更多的事情。
其实这也是所有使用多线程的本质:
- 利用多核。
- 当I/O阻塞系统,但CPU空闲的时候,可以利用多线程使用CPU资源。
(即I/O 密集型任务,用多线程)
现在的多线程一般都使用线程池,可以让线程的创建和回收成本相对较低。在活动连接数不是特别高(小于单机1000)的情况下,这种模型是比较不错的,可以让每一个连接专注于自己的I/O并且编程模型简单,也不用过多考虑系统的过载、限流等问题。线程池本身就是一个天然的漏斗,可以缓冲一些系统处理不了的连接或请求。
不过,这个模型最本质的问题在于,严重依赖于线程。但线程是很"贵"的资源,主要表现在:
- 线程的创建和销毁成本很高,在Linux这样的操作系统中,线程本质上就是一个进程。创建和销毁都是重量级的系统函数。
- 线程本身占用较大内存,像Java的线程栈,一般至少分配512K~1M的空间,如果系统中的线程数过千,恐怕整个JVM的内存都会被吃掉一半。
- 线程的切换成本是很高的。操作系统发生线程切换的时候,需要保留线程的上下文,然后执行系统调用。如果线程数过高,可能执行线程切换的时间甚至会大于线程执行的时间,这时候带来的表现往往是系统load偏高、CPU sy使用率特别高(超过20%以上),导致系统几乎陷入不可用的状态。
- 容易造成锯齿状的系统负载。因为系统负载是用活动线程数或CPU核心数,一旦线程数量高但外部网络环境不是很稳定,就很容易造成大量请求的结果同时返回,激活大量阻塞线程从而使系统负载压力过大。
所以,当面对十万甚至百万级连接的时候,传统的BIO模型是无能为力的。随着移动端应用的兴起和各种网络游戏的盛行,百万级长连接日趋普遍,此时,必然需要一种更高效的I/O处理模型。
Java NIO浅析 - 知乎
Socket网络编程 - 知乎
从jvm的角度来看java的多线程 - 叫我家宝 - 博客园
![]()
volatile 的作用,底层实现 。
volatile 只能保证可见性、有序性。
保证可见性:jmm 内存模型,通过缓存一致性协议,总线嗅探机制。
volatile保证可见性的原理是在每次访问变量时都会进行一次刷新,因此每次访问都是主内存中最新的版本。所以volatile关键字的作用之一就是保证变量修改的实时可见性。
保证有序性:指令重排序是通过分析预习判断指令的依赖关系。而多线程的环境下,比如说方法1 操作两个变量,方法二根据这两个变量做操作,其中有个判断。然后两个方法在不同的线程中执行。对于方法1,指令进行了重排序,就会导致方法2 出问题。
以上参考:并发环境下指令重排带来的问题 - 简书
如何保证有序性。直接参考下面链接。
参考:知道这些,面试时volatile就稳了 - 知乎
使用volatile 的场景
应用于大量并发读,少量并发写的场景。
不应该使用的场景:
1. 对变量的写操作不依赖于当前值。理解就是,当你需要改变这个变量时,要保证你要改变的值跟这个变量原先的值没有任何关系,比如:count = 10; 而不是count++;
2. 该变量没有包含在具有其他变量的不变式中.
可以使用的场景:
参考:volatile适用场景 - 知乎
volatile 和synchronized 的区别:https://segmentfault.com/a/1190000023907308
Java并发编程:volatile关键字解析 - Matrix海子 - 博客园
掘金(这个链接可以的)
![]()
单例模式(饿汉式)如何避免反射破坏
单例模式,确保一个类在任何情况下,都绝对只有一个实例,并提供一个全局访问点。隐藏其构造方法,属于创建型模式。
使用场景:ServletContext、ServletConfig、ApplicationContext、DBPool
单例模式的实现:
- 饿汉模式
如何破坏:通过反射,拿到class 类对象,设置setAccessible(true),破坏单例。
解决方案:
- 私有构造方法中加个判断,如果已经单例对象已经不为空了,那么调用构造方法的时候抛异常。但是序列化、反序列化得到的对象是不一致的
- 枚举单例模式 - 得天独厚的防止反射破坏单例模式(jdk 1.8 中,判断如果是Modifier.ENUM枚举类型,直接抛出异常(源码强制性判断,为枚举式单例保驾护航))
答案:通过枚举类。(参考:Java单例模式的7种写法中,为何用Enum枚举实现被认为是最好的方式?【享学Java】 - 云+社区 - 腾讯云)
- 反射安全
- 序列化/反序列化安全
- 写法简单
- 没有一个更有信服力的原因不去使用枚举
参考:5分钟学会利用反射破坏单例模式解决方案_猿医ˉ生-CSDN博客
枚举介绍,原理,各种单例介绍,可以看这个:掘金
懒汉式和饿汉式哪个是线程安全?
DCL 设计模式 spring 中用到的,代理、单例、
![]()
final 的使用
- final 的使用范围
final 可以修饰类、类的成员变量、类的成员方法、成员方法的局部变量
不可以修饰构造方法,原因:修饰普通方法,将导致子类无法重写该方法,而构造方法本身就不能被子类重写,所以如果用final 修饰,如同多此一举。
- final 修饰类
final 修饰的类不能被其他类继承,但是该类仍然能够创建对象,并且可以可以利用该对象调用类的成员变量和成员方法。
- final 修饰成员方法
修饰成员方法,该成员方法不能被子类重写,但是仍可以被子类继承并可以通过子类对象调用该方法。
- 修饰成员变量
通常,由final 定义的变量为常量。
(1)修饰成员变量,该变量必须在创建对象前进行赋值,否则编译失败
(2)final 修饰成员变量,固定的不是成员变量拥有的默认值,如果固定的是默认值,那么将导致被final修饰的成员变量的值永远无法修改,只能是默认值,这也不符合语法规则
(3)成员变量的赋值只有三种方式:定义时手动赋值;构造器;set 方法。被final 修饰的只能用1 和2。
- final 修饰成员变量和局部变量的区别和联系
联系:一旦赋值,该值终身不变
区别:成员变量必须要在创建对象之前进行赋值,否则编译失败;局部变量可以不赋值,但是不能使用,一旦被使用就会编译失败
综上:一旦决定使用final 关键字来修饰成员变量或局部变量,一定要做到提前赋值。
以上:java——Final修饰成员变量的注意事项_西城风雨楼-CSDN博客_final修饰成员变量
使用例子查看:Java中的final变量、final方法和final类_pan_junbiao的博客-CSDN博客_final变量
![]()
java 如何实现序列化
字节和字符的区别:字节(byte)是计量单位,表示数据量的多少,是计算机用于计量存储容量的一种计量单位,通常情况一字节等于8 位(bit)。字符(character)是计算机中使用的字母、数字、汉字、符号等,如'A','B','#' 等。一般英文一个字母或字符占用一个字节,一个汉字用两个字节表示。
序列化的作用就是为了不同jvm 之间共享实例对象的一种解决方案。由java 提供此机制。
反序列化是利用反射实现的(jdk1.8源码,readObject-> readObject0 -> readOrdinaryObject -> invokeReadResolve ->readResolveMethod.invoke)
序列化基本概念介绍:掘金
序列化:将对象写入到IO 流中
序列化机制允许将实现了序列化接口的java 对象转换为字节序列,这些字节序列可以保存在磁盘上,或者通过网络传输。序列化机制使得对象可以脱离程序的运行而独立存在。
所有可在网络上传输的对象都必须是可序列化的,比如RMI(remote method interface,远程方法调用),传入的参数和返回的对象都是可序列化的,否则会出错。需要保存到磁盘的java 对象也是。
反序列化的顺序与序列化时的顺序一致。
反序列化不会调用构造方法,反序列化对象是由JVM 自己生成的对象,不通过构造方法。
Java序列化同一对象,并不会将此对象序列化多次得到多个对象。
意思是比如一个Teacher t1 = new Teacher("雷利"); oos.writeObject(t1); 一次,然后再oos.writeObject(t1); 那么序列化此对象只会序列化一次。反序列化得到的也是同一个对象。
原因:所有保存到磁盘的对象都有一个序列化编号,当程序试图序列化一个对象时,会先检查此对象是否已经序列化过,只有此对象从未(在此虚拟机)被序列化过,才会将此对象序列化为字节序列输出。
java 序列化算法:
- 所有保存到磁盘的对象都有一个序列化编码号
- 当程序视图序列化一个对象的时候,会检查此对象是否已经被序列化过,只有从未被(在此虚拟机)序列化过,才会将此对象序列化为字节序列输出
- 如果此对象已经序列化过,那么直接输出编号即可
- 如果序列化一个可变对象后,更改对象的内容,再次序列化,并不会将此对象转换为字节序列,而只是保存序列化编号。
- 使用transient 关键字选择不需要序列化的字段。
在序列化时,会忽略此字段,反序列化时,被transient 修饰的属性是默认值:对引用类型值是null;基本类型是0;boolean 类型是false。
此关键字将属性完全隔离在序列化之外,java 提供了可选的自定义序列化。
实现序列化有两个接口
- Serializable
- Externalizable 强制自定义序列化,需要用户自定义实现存储哪些内容
存在的问题:如果序列化一个可变对象,在第一次序列化结束之后,如果改变了对象的值,再次序列化此对象,并不会再将此对象转为字节序列,而只是保存序列化编号。
两种序列化对比
| 实现Serializable接口 | 实现Externalizable接口 |
|---|---|
| 系统自动存储必要的信息 | 程序员决定存储哪些信息 |
| Java内建支持,易于实现,只需要实现该接口即可,无需任何代码支持 | 必须实现接口内的两个方法 同时必须提供无参构造方法,因为在反序列化的时候需要反射创建对象。 |
| 性能略差 | 性能略好 |
序列化版本号
反序列化必须有class 文件,但是随着项目的升级,class 文件也会升级,序列化咱们保证升级前后的兼容性?
java 序列化提供了一个private static final long serialVersionUID 的序列化版本号,只有版本号相同,即使更改了序列化属性,对象也可以被反序列化回来。
如果版本号不一致,反序列化会报InvalidClassException 异常
是否需要修改serialVersionUID 的情况
- 如果只是修改了方法,反序列化不容影响,则无需修改版本号;
- 如果只是修改了静态变量,瞬态变量(transient修饰的变量),反序列化不受影响,无需修改版本号;
(静态变量是类级别的,不能序列化,序列化只是序列化对象。“不能序列化”的意思是序列化信息中不包含这个静态成员域。) - 如果修改了非瞬态变量,则可能导致反序列化失败。如果新类中实例变量的类型与序列化时类的类型不一致,则会反序列化失败,这时候需要更改serialVersionUID。如果只是新增了实例变量,则反序列化回来新增的是默认值;如果减少了实例变量,反序列化时会忽略掉减少的实例变量。
序列化对象时,如果不显示的设置serialVersionUID,Java在序列化时会根据对象属性自动的生成一个serialVersionUID,再进行存储或用作网络传输。
单例类序列化,需要重写readResolve()方法;否则会破坏单例原则。
写的时候,先调用writeResolve(),再调用writeObject() 方法
读的时候,先调用readObject() 方法,再调用readResolve() 方法
在readResolve() 中直接返回单例的对象就可以了
以上参考:掘金
几种常用的序列化 & 反序列化协议
- XML&SOAP
XML 是一种常用的序列化和反序列化协议,具有跨机器,跨语言等优点,SOAP(Simple Object Access protocol,简单对象 存取/访问 协议) 是一种被广泛应用的,基于 XML 为序列化和反序列化协议的结构化消息传递协议 - JSON
- protobuf
关于transient 的使用小结
1)一旦变量被transient修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
2)transient关键字只能修饰变量,而不能修饰方法和类。注意,本地变量(static)是不能被transient关键字修饰的。变量如果是用户自定义类变量,则该类需要实现Serializable接口。
3)被transient关键字修饰的变量不再能被序列化,一个静态变量不管是否被transient修饰,均不能被序列化
序列化原理:掘金
为什么重写writeObject() 方法可以重写,因为在源码里个检查的步骤
一些问题:2020 最新Java序列化面试题_duchaochen的博客-CSDN博客_java序列化面试题
- 序列化对象以字节数组保持,静态成员不保存。
对象序列化保存的是对象的“状态”,即它的成员变量。由此可知,对象序列化不会关注其静态变量。
只有堆内存会被序列化.所以静态变量 天生不会被序列化
序列化保存的是对象的状态而非类的状态
流的概念:https://segmentfault.com/a/1190000004103031(有时间了解即可)
![]()
![]()
socket 和websocket 的区别
参考:websocket和socket的区别是什么-常见问题-PHP中文网
socket 是TCP/IP 网络的API,是为了方便使用TCP 或UDP 而抽象出来的一层,位于应用层和传输控制层之间的一组接口;而webSocket 则是一个典型的应用层协议。
- WebSocket 协议是html5 的一种新协议。实现了浏览器与服务器之间的全双工通信。
一开始的握手需要借助HTTP 请求完成。
目的:即时通讯,代替轮询。
网站上即时通讯很常见,如网页QQ,聊天系统等。
http 是非持久化的,单向的网络协议,在建立连接后只允许浏览器向服务器发出请求后,服务器才能返回数据。而即时通信使用http 进行轮询时,是要不断发送请求。
webSocket 可以弥补上述问题,只需要c & s 通过http 践行一个握手的动作,然后单独建一条tcp 通信通道进行数据传送。
是应用层协议,是一种双向通信协议,建立在tcp 之上。
等有空看看这个,介绍socket 的:Socket通信协议解析(文章摘要) - 知乎
![]()
HTTP 的长连接、短连接
参考:HTTP长连接、短连接究竟是什么? - 华为云
http 协议的场长连接和短连接本质上是TCP 长连接和短连接
http 属于应用层协议,在传输层使用TCP 协议,网络层使用IP 协议。
IP 协议解决网络路由和寻址问题,TCP 解决IP 层之上可靠传输的问题。TCP 是可靠的,面向连接的。
HTTP 1.0 默认短连接,1.1 开始默认使用长连接。而http 的长连接。
使用长连接的http 协议,会在响应头加入“Connection:keep-alive”
TCP的保活功能主要为服务器应用提供。
长连接多用于操作频繁,点对点的通讯,且连接数不能太多的情况。例如:数据库的连接使用长连接。像web 网站的http 服务一般使用短连接,长连接对于服务端来说会耗费一定资源,而且用户成千上万,所以并发量大,但每个用户无需频繁操作情况下用短连接好。
get post 区别
[http 1.0] get post head
[http 1.1] options put delete trace connect
- 传参,get 在url 中传参,有长度限制,post 没有
- get 比post 不安全
- get 只接收ascII 类型参数,post 无限制
- get 请求参数完整保存在浏览历史中
- get 被浏览器主动缓存
- get 回退无害,post 重新提交请求
听我讲完 GET、POST 原理,面试官给我倒了杯卡布奇诺
![]()
七层网络模型
![]()
![]()
DDD 业务领域模型
“就诊”作为出发点,医生、药师作为过程中遇到的角色,“就诊”有明确的目标就是治病,整个过程需要一些动作才能达到这个目标。
总结:出发点(问题)、遇到的角色、目标(达到的结果)、中间的动作
DDD 有两类数据:基础数据(偏内向)、业务数据(偏外向)。业务数据让基础数据彼此关联起来。建模前,分清基础数据、业务数据
![]()
java 切换上下文
![]()
jvm 内存模型,垃圾回收机制,几种算法,几种回收机制
java创建对象的过程详解,从内存角度
java创建对象的过程详解(从内存角度分析) - 知乎
类加载的过程

有时间可以看看这个:https://www.zhihu.com/question/296949412/answer/2020805404
这个写的不错:JAVA---枚举类、类的加载 - 简书
java 内存模型

![]()
垃圾回收
三色标记算法缺陷
在并发标记阶段的时候,因为用户线程与GC线程同时运行,有可能会产生多标或者漏标;
标记的作用是,把对象标记为“不是垃圾”
多标--多标记(浮动垃圾)(应该是垃圾的被标位不是垃圾)
漏标--漏标记(不应该是垃圾的,没有被标出来)
漏标问题大。
漏标发生的两个条件:
1.至少有一个黑色对象指向了白色对象
2.所有灰色对象扫描完整个链时,删除之前所有白色对象。
cms 解决漏标的问题:写屏障 + 增量更新
当黑色对象指向白色对象的时候,记下这个黑色对象。
重新标记阶段,将黑色对象改为灰色对象,重新扫描这条路
G1 解决漏标问题:原始快照的方式
在C断开E的时候,会记录原始快照,在重新标记阶段的时候以白色对象变为灰色为起始点扫描整个链,本次GC是不会被清理。
参考:CMS和G1的漏标问题解决及三色标记算法图解 - 简书
![]()
![]()
![]()
![]()
spring 中用到了那些设计模式
Spring 框架中使用到了大量的设计模式,下面列举了比较有代表性的:
-
代理模式—在 AOP 和 remoting 中被用的比较多。
-
单例模式—在 spring 配置文件中定义的 bean 默认为单例模式。
-
前端控制器—Spring 提供了 DispatcherServlet 来对请求进行分发。
Spring 的 ApplicationContext 创建的 Bean 实例都是单例对象,还有 ServletContext、数据库连接池等也都是单例模式。
Spring Framework 中,是使用@EnableAspectJAutoProxy注解来开启 Spring AOP 相关功能的。
![]()
aop 分两种类型
哪两种
![]()
kafka
幂等
kafka 幂等性原理:Kafka幂等性原理及实现剖析 - 哥不是小萝莉 - 博客园
解决:引入了ProducerID和SequenceNumber。
每个producer 都有个producerId,每个消息都有个sequenceNumber。
二者组合,实现幂等。
事务
比如:原子性的读取消息,立即处理和发送,如果中途出现错误,支持回滚操作。
选举机制
从三个方面说明
- 控制器(Broker)选主
- 分区多副本选主
- 消费组选主
Kafka学习之Kafka选举机制简述 - kosamino - 博客园
kafka 控制器介绍:
Kafka实战宝典:Kafka的控制器controller详解 - WindyQin - 博客园
![]()
session cookie socket 的这些东西
![]()
![]()
数据库隔离级别,mysql、orcale 默认隔离级别
幻读 不可重复度 脏读
读未提交 1 1 1
读已提交 1 1 0
可重复读 1 0 0
串行化 0 0 0
mysql 默认可重复读
orcale 默认可重复读
![]()
枚举
是指一组固定常量组成合法值的类型。
枚举类构造方法私有,不允许创建对象
类和枚举的关系:Java 枚举与类的区别_lishuangling21的博客-CSDN博客_java枚举与类的区别
![]()
四次挥手,最后为什么要等待2msl,这个要看一下
2MSL(最大报文段生存时间)。
- 为什么是四次挥手而不是三次挥手
三次挥手:主动方发送fin + ack,被动方发送fin,主动方发送ack
问题:tcp 是全双工通信(可以双向同时通信)。
(1)主动方发送fin 之后,仅仅代表主动方不会发送数据报文,但是主动方仍可以接受、被动方仍可以发送
(2)被动方可能还有报文要发送,所以先发送ack,代表我收到了,知道你要关了,这样主动方不会因为没有收到应答而继续发送断开的连接请求(即fin)
(3)被动方处理完数据之后,便发送给主动方fin 报文,这样保证数据通信正常可靠地完成。发送完fin 报文之后,被动房进入last_ack 阶段
(4)如果主动方即使发送ack 报文进行连接中断确认,这时被动方就直接释放连接,进入可用状态。
而正常主动方发送完最后的ack 消息之后,就可以进入close 状态了。但是主动方会等待2msl 之后才会进入colse 状态。因为要假设网络是不稳定的,如果主动方发送了ack 消息,被动方没有收到,那么服务器就会一直发送fin 报文。
所以客户端不能立刻关闭,它必须确认服务端收到了ack。
客户端会在发送出ACK之后进入到TIME_WAIT状态,同时设置一个计时器,等待2MSL的时间。如果在该时间内再次收到FIN,那么客户端会重发ACK并再次等待2MSL。
所谓的2MSL是两倍的MSL(Maximum Segment Lifetime)。MSL指一个片段在网络中最大的存活时间,2MSL就是一个发送和一个回复所需的最大时间。如果直到2MSL,客户端都没有再次收到FIN,那么客户端推断ACK已经被成功接收,则结束TCP连接。
- 三次握手
发送端首先发送一个带SYN 标志的数据包给接收方
接收端收到后,回传一个带有SYN/ACK 标志的数据包给接收方。SYN 是为了告诉发送端,发送方到接收方的通道没问题。ack 是为了验证接收方到发送方的通道。
最后,发送端再传回一个带ack 标志的数据包,代表握手结束
- 两次握手是否可以,为什么tcp 客户端最后还要发送一次确认
主要防止已经失效的连接请求报文突然又传送到了服务器,从而产生错误。
经典场景:客户端发送了第一个请求连接并且没有丢失,只是因为在网络结点中滞留的时间太长了
由于TCP的客户端迟迟没有收到确认报文,以为服务器没有收到,此时重新向服务器发送这条报文,此后客户端和服务器经过两次握手完成连接,传输数据,然后关闭连接。
此时此前滞留的那一次请求连接,网络通畅了到达服务器,这个报文本该是失效的,但是,两次握手的机制将会让客户端和服务器再次建立连接,这将导致不必要的错误和资源的浪费。
如果采用的是三次握手,就算是那一次失效的报文传送过来了,服务端接受到了那条失效报文并且回复了确认报文,但是客户端不会再次发出确认。由于服务器收不到确认,就知道客户端并没有请求连接
- tcp 三次握手中,最后一次回复丢失,会发生什么
服务端关闭了连接,客户端确认为链接已建立。发送数据的时候,服务端收到,会发送RST 包,代表异常关闭链接,此时客户端知道链接建立失败。
java spi 机制
当接口属于调用方时,我们就将其称为spi,全称为:service provider interface,spi的规则如下:
- 概念上更依赖调用方
- 组织上位于调用方所在的包中
- 实现位于独立的包中(也可认为在提供方中)
Java SPI思想梳理 - 知乎

spi 对双亲委派模型的破坏介绍:聊聊SPI机制以及为什么说SPI破坏了双亲委派模型_womeiyouzaihuashui的博客-CSDN博客
![]()
树的数据结构(参考:[Data Structure] 数据结构中各种树 - Poll的笔记 - 博客园)
- 二叉查找树(二叉排序树、二叉搜索树)
左 < 根 < 右,同时向下递归
插入 & 查找时间复杂度O(logn),最坏情况O(n)。因为没有保持平衡。
- 平衡二叉树(AVL 树)
左右两个子树高度差的绝对值不超过1,同时向下递归
红黑树、AVL 树,是平衡二叉树,高度一般良好地维持在O(log2n),大大降低了操作的时间复杂度
- 红黑树
也是二叉查找树,在二叉查找树的基础上,增加一些属性和性质。(根节点黑色;两个红色节点不能相连;从一个节点到该节点的子孙节点的所有路径上包含相同数目的黑色节点)
这些性质避免退化成单链表的情况。
红黑树保证了在最坏情况下在O(logn) 时间复杂度内完成查找、插入及删除操作。
avl 适用于插入及删除操作少,查询多的情况。因为其旋转是非常耗时的。
红黑树追求局部平衡而不是整体平衡。
每个叶子节点都是黑色的,且不存储数据。
平衡二叉树和红黑树,在插入操作,最多只需要旋转两次。但是删除操作的时候,AVL 最多需要旋转的量级为O(longN),而红黑树最多只需要3 次。
- B- 树(或者B 树)
每个节点都存储元素,孩子数量 = 关键字数 + 1
M 路B 树,每个节点最多有M - 1 个关键字;根节点至少可以只有一个关键字;非根节点至少有M/2 个关键字;每个节点都存有节点和数据,也就是key 和value。
- B+ 树
孩子数量 = 关键字数(两种实现,另一个实现等同于B 树。mysql 中用的是这种)
- B+ 树和B 树的区别
对于B+ 树,有K 个子节点的节点必然有K 个关键码
非叶节点仅具有索引作用,跟记录有关的全部存在于叶子节点中
B+ 树在内部节点中不包含数据信息,所以在内存页中可以存放更多的数据。
而对于B 树,其优点是每一个节点都包含key 和value,因此数据方法可能更加迅速。
B/B+ 树是为了存储设备设计的一种平衡多路查找树(相对于二叉树,B 树的每个内节点有多个分支)。
讲B 树和B+ 树和B* 数的区别,其中有概念、定义、增删操作:平衡二叉树、B树、B+树、B*树 理解其中一种你就都明白了 - 知乎
参考:数据结构里各种难啃的“树”,一文搞懂它 - 知乎
红黑树和B+ 树的区别和应用场景:红黑树 与 B+树区别和应用场景 - 知乎
![]()
算法,全排列, 一个字符串集合,能不能通过单词集合拼成字符串 排序算法
找两个比较好的项目。亮点,用了什么技术。 业务背景,怎么设计的,这种。
![]()
分布式id 生成方案:
分布式全局ID生成方案 - JaJian - 博客园
分布式事务:
分布式事务,这一篇就够了 | 小米信息部技术团队
两阶段提交 三阶段提交
![]()
为什么需要 Zookeeper - 知乎 为什么需要zookeeper
cap 理论:谈谈分布式系统的CAP理论 - 知乎
![]()
其他:
介绍经验:如何在面试中介绍自己的项目经验 - hsm_computer - 博客园
mysql 索引:like百分号加前面一定不走索引吗?一不小心就翻车,关于mysql索引那些容易错的点 - 知乎
面题汇总:腾讯、阿里、滴滴后台面试题汇总总结 — (含答案)_温不了情的博客-CSDN博客_腾讯笔试题库及答案
hbase :HBase经典面试常问问题汇总_石榴姐yyds-CSDN博客_hbase的面试题
新问题:
跳表为什么使用了两种数据结构
java8 的metaspace 零拷贝 伪共享 mesi 哈希一致性
分布式事务算法 有点绕
这篇关于experience的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


![建立用户体验(User Experience,UX)过程的实用指南[转]](/front/images/it_default.gif)