本文主要是介绍结构体和类的内存字节对齐详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文转载自:http://www.jizhuomi.com/software/567.html
先说个题外话:早些年我学C程序设计时,写过一段解释硬盘MBR分区表的代码,对着磁盘编辑器怎么看,怎么对,可一执行,结果就错了。当时调试也不太会,又根本没听过结构体对齐这一说,所以,问题解决不了,好几天都十分纠结。后来万般无奈请教一个朋友,才获悉可能是结构体对齐的事,一查、一改,果真如此。
问题是解决了,可网上的资料多数只提到内存对齐是如何做的,却鲜有提及为什么这样做(即使提,也相当简单)。笔者是个超级健忘者,很难机械式的记住这些破规则,于是仔细想了想,总算明白了原因,这样,这些对齐的规则也就不会再轻易忘记了。
不光结构体存在内存对齐一说,类(对象)也如此,甚至于所有变量在内存中的存储也有对齐一说(只是这些对程序员是透明的,不需要关心)。实际上,这种对齐是为了在空间与复杂度上达到平衡的一种技术手段,简单的讲,是为了在可接受的空间浪费的前提下,尽可能的提高对相同运算过程的最少(快)处理。先举个例子:
假设机器字长是32位的(即4字节,下面示例均按此字长),也就是说处理任何内存中的数据,其实都是按32位的单位进行的。现在有2个变量:
- char A;
- int B;
假设这2个变量是从内存地址0开始分配的,如果不考虑对齐,应该是这样存储的(见下图,以intel上的little endian为例,为了形象,每16个字节分做一行,后同):

因为计算机的字长是4字节的,所以在处理变量A与B时的过程可能大致为:
A:将0x00-0x03共32位读入寄存器,再通过左移24位再右移24位运算得到a的值(或与0x000000FF做与运算)
B:将0x00-0x03这32位读入寄存器,通过位运算得到低24位的值;再将0x04-0x07这32位读入寄存器,通过位运算得到高8位的值;再与最先得到的24位做位运算,才可得到整个32位的值。
上面叙述可知,对a的处理是最简处理,可对b的处理,本身是个32位数,处理的时候却得折成2部分,之后再合并,效率上就有些低了。
想解决这个问题,就需要付出几个字节浪费的代价,改为下图的分配方式:

按上面的分配方式,A的处理过程不变;B却简单得多了:只需将0x04-0x07这32位读入寄存器就OK了。
我们可以具体谈结构体或类成员的对齐了:
结构体在编译成机器代码后,其实就没有本身的集合概念了,而类,实际上是个加强版的结构体,类的对象在实例化时,内存中申请的就是一些变量的空间集合(类似于结构体,同时也不包含函数指针)。这些集合中的每个变量,在使用中,都需要涉及上述的加工原则,自然也就需要在效率与空间之间做出权衡。
为了便捷加工连续多个相同类型原始变量,同时简化原始变量寻址,再汇总上述最少处理原则,通常可以将原始变量的长度做为针对此变量的分配单位,比如内存可用64个单元,如果某原始变量长度为8字节,即使机器字长为4字节,分配的时候也以8字节对齐(看似IO次数是相同的),这样,寻址、分配时,均可以按每8字节为单位进行,简化了操作,也可以更高效。
系统默认的对齐规则,追求的至少两点:1、变量的最高效加工 2、达到目的1的最少空间
举个例子,一个结构体如下:
- typedef struct T
- {
- char c; //本身长度1字节
- __int64 d; //本身长度8字节
- int e; //本身长度4字节
- short f; //本身长度2字节
- char g; //本身长度1字节
- short h; //本身长度2字节
- };
假设定义了一个结构体变量C,在内存中分配到了0x00的位置,显然:
对于成员C.c 无论如何,也是一次寄存器读入,所以先占一个字节。
对于成员C.d 是个64位的变量,如果紧跟着C.c存储,则读入寄存器至少需要3次,为了实现最少的2次读入,至少需要以4字节对齐;同时对于8字节的原始变量,为了在寻址单位上统一,则需要按8字节对齐,所以,应该分配到0x08-0xF的位置。
对于成员C.e 是个32位的变量,自然只需满足分配起始为整数个32位即可,所以分配至0x10-0x13。
对于成员C.f 是个16位的变量,直接分配在0x14-0x16上,这样,反正只需一次读入寄存器后加工,边界也与16位对齐。
对于成员C.g 是个8位的变量,本身也得一次读入寄存器后加工,同时对于1个字节的变量,存储在任何字节开始都是对齐,所以,分配到0x17的位置。
对于成员C.h 是个16位的变量,为了保证与16位边界对齐,所以,分配到0x18-0x1A的位置。
分配图如下(还不正确,耐心读下去):

结构体C的占用空间到h结束就可以了吗?我们找个示例:如果定义一个结构体数组 CA[2],按变量分配的原则,这2个结构体应该是在内存中连续存储的,分配应该如下图:

分析一下上图,明显可知,CA[1]的很多成员都不再对齐了,究其原因,是结构体的开始边界不对齐。
那结构体的开始偏移满足什么条件才可以使其成员全部对齐呢。想一想就明白了:很简单,保证结构体长度是原始成员最长分配的整数倍即可。
上述结构体应该按最长的.d成员对齐,即与8字节对齐,这样正确的分配图如下:

当然结构体T的长度:sizeof(T)==0x20;
再举个例子,看看在默认对齐规则下,各结构体成员的对齐规则:
- typedef struct A
- {
- char c; //1个字节
- int d; //4个字节,要与4字节对齐,所以分配至第4个字节处
- short e; //2个字节, 上述两个成员过后,本身就是与2对齐的,所以之前无填充
- }; //整个结构体,最长的成员为4个字节,需要总长度与4字节对齐,所以, sizeof(A)==12
- typedef struct B
- {
- char c; //1个字节
- __int64 d; //8个字节,位置要与8字节对齐,所以分配到第8个字节处
- int e; //4个字节,成员d结束于15字节,紧跟的16字节对齐于4字节,所以分配到16-19
- short f; //2个字节,成员e结束于19字节,紧跟的20字节对齐于2字节,所以分配到20-21
- A g; //结构体长为12字节,最长成员为4字节,需按4字节对齐,所以前面跳过2个字节,
- //到24-35字节处
- char h; //1个字节,分配到36字节处
- int i; //4个字节,要对齐4字节,跳过3字节,分配到40-43 字节
- }; //整个结构体的最大分配成员为8字节,所以结构体后面加5字节填充,被到48字节。故:
- //sizeof(B)==48;
具体的分配图如下:

上述全部测试代码如下:
- #include "stdio.h"
- typedef struct A
- {
- char c;
- int d;
- short e;
- };
- typedef struct B
- {
- char c;
- __int64 d;
- int e;
- short f;
- A g;
- char h;
- int i;
- };
- typedef struct C
- {
- char c;
- __int64 d;
- int e;
- short f;
- char g;
- short h;
- };
- typedef struct D
- {
- char a;
- short b;
- char c;
- };
- int main()
- {
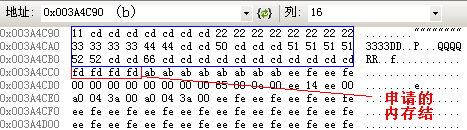
- B *b=new B;
- void *s[32];
- s[0]=b;
- s[1]=&b->c;
- s[2]=&b->d;
- s[3]=&b->e;
- s[4]=&b->f;
- s[5]=&b->g;
- s[6]=&b->h;
- s[7]=&b->g.c;
- s[8]=&b->g.d;
- s[9]=&b->g.e;
- s[10]=&b->i;
- b->c= 0x11;
- b->d= 0x2222222222222222;
- b->e= 0x33333333;
- b->f=0x4444;
- b->g.c=0x50;
- b->g.d=0x51515151;
- b->g.e=0x5252;
- b->h=0x66;
- int i1=sizeof(A);
- int i2=sizeof(B);
- int i3=sizeof(C);
- int i4=sizeof(D);
- printf("i1:%d\ni2:%d\ni3:%d\ni4:%d\n",i1,i2,i3,i4);//12 48 32 6
- }
运行时的内存情况如下图:
最后,简单加工一下转载过来的内存对齐正式原则:
先介绍四个概念:
1)数据类型自身的对齐值:基本数据类型的自身对齐值,等于sizeof(基本数据类型)。
2)指定对齐值:#pragma pack (value)时的指定对齐值value。
3)结构体或者类的自身对齐值:其成员中自身对齐值最大的那个值。
4)数据成员、结构体和类的有效对齐值:自身对齐值和指定对齐值中较小的那个值。
有效对齐值N是最终用来决定数据存放地址方式的值,最重要。有效对齐N,就是表示“对齐在N上”,也就是说该数据的"存放起始地址%N=0".而数据结构中的数据变量都是按定义的先后顺序来排放的。第一个数据变量的起始地址就是 数据结构的起始地址。结构体的成员变量要对齐排放,结构体本身也要根据自身的有效对齐值圆整(就是结构体成员变量占用总长度需要是对结构体有效对齐值的整 数倍)
#pragma pack (value)来告诉编译器,使用我们指定的对齐值来取代缺省的。
如#pragma pack (1) /*指定按2字节对齐*/
#pragma pack () /*取消指定对齐,恢复缺省对齐*/
这篇关于结构体和类的内存字节对齐详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





