本文主要是介绍下面是一个简单的Python小虫的详细步骤,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分析目标网站
在之前,需要之前目标分析分析分析,了解目标进行进行进行结构,,页面的的组成组成,,页面的的链接链接等。可以使用浏览器的开发者开发者开发者工具网络请求等信息,也可以使用一些专业的爬虫工具,如Scrapy、PySpider等。
安装必须的库
Python 虫需要使用一些第三方库,如 requests、BeautifulSoup、lxml 等,可以使用 pip 工具安装这些库。

发送请求并获取网页内容
可以使用 requests 发送请求并获取网页内容。例如,发送一个 GET 请求获取网站首页的 HTML 内容:
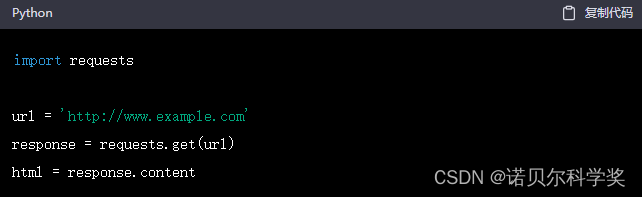
解析网页内容
可以使用 BeautifulSoup 库解析网页内容。例如,查找页面中的标题标签:
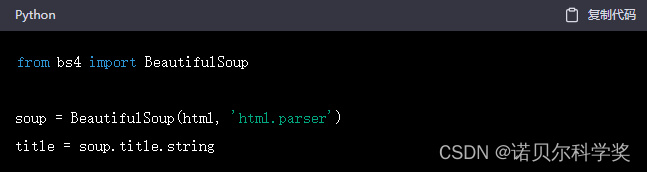
查找并提取数据
可以使用 BeautifulSoup 库查找页面中的标签并提取数据。例如,查询页面中的所有链接并提取链接的 href 和文本内容:
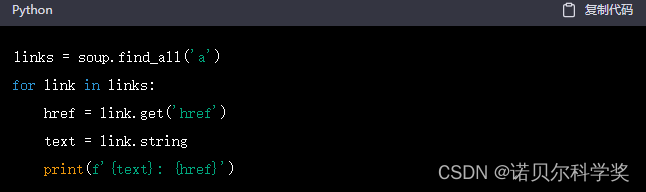
保存数据
可以将提取的数据保存到本地文件或数据库中。例如,将提取的链接保存到文件中:
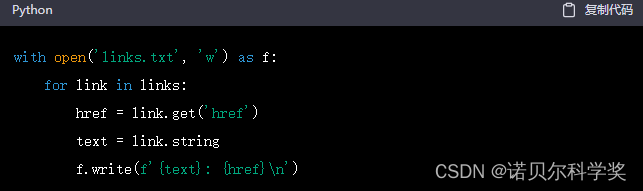
这篇关于下面是一个简单的Python小虫的详细步骤的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






