本文主要是介绍Facebook 惊魂 6小时,影响 27 亿用户,市值蒸发百亿...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
上面这个公号,是我的一个备用号,平时我也会发一些很短、很生活的图片、文字,也会推荐看到的好书、节目、电影等。
1
惊魂 6小时
国庆当大家都开启逛玩逛吃的时候,大洋彼岸的互联网巨头 Facebook 却宕机了。
这次宕机规模之大、持续时间之久可以说是近年来罕见。
当地时间10月4日上午11点45分,美国社交巨头 Facebook 及其旗下应用 WhatsApp、Ins 突然陷入大规模瘫痪。
全球的用户突然发现,没法打开 Facebook、Instagram 和 WhatsApp,甚至连虚拟现实平台 Oculus、内部工作系统都受到了影响。
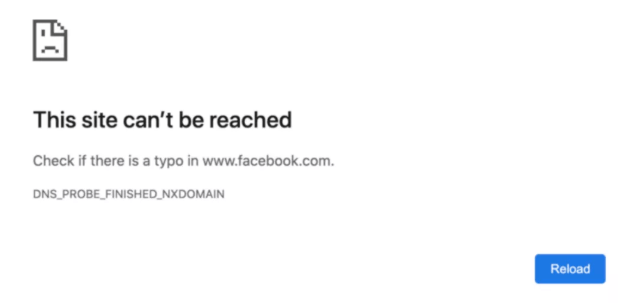
当然了,网站短暂的连接不上也不是什么大问题,大家平时也都遇到过,想想过一会就恢复了。
没想到了过了好几个小时了,仍然没有恢复。
当天受此消息影响,Facebook 的股价暴跌了近5%,创下全年最大单日跌幅,百亿市值瞬间蒸发。
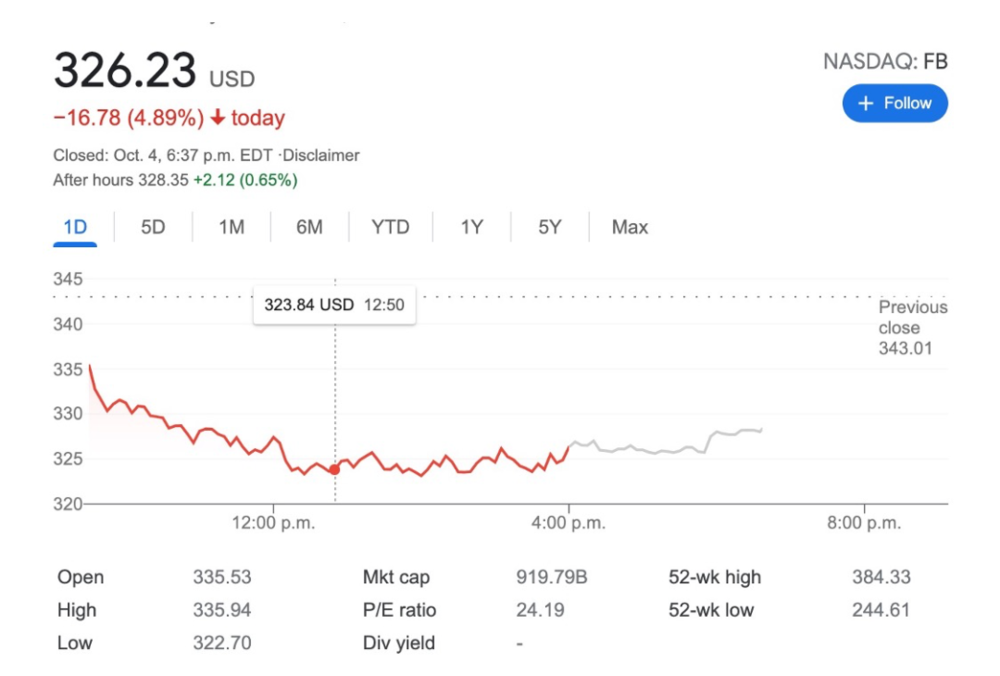
2
网友疯狂吐槽
大家还记得,7 月 13 日 B 站服务器挂掉,发生了什么事情吗?
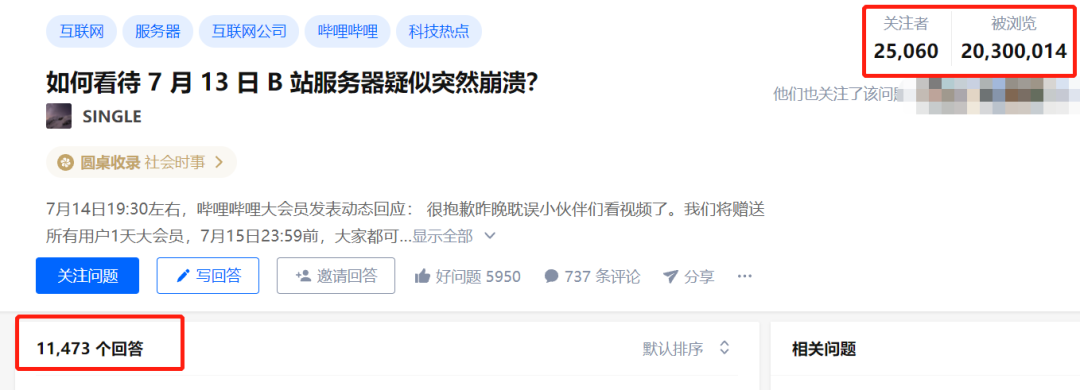
B站崩了之后,B站的用户迅速的冲向了知乎,把这个问题顶到了知乎热榜第一名。
当时每刷新一下这个问题,就会多几十条回答,到目前为止,这个问题下有 11473 个回答,2000 多万的浏览量。
天底下的网友都一样...
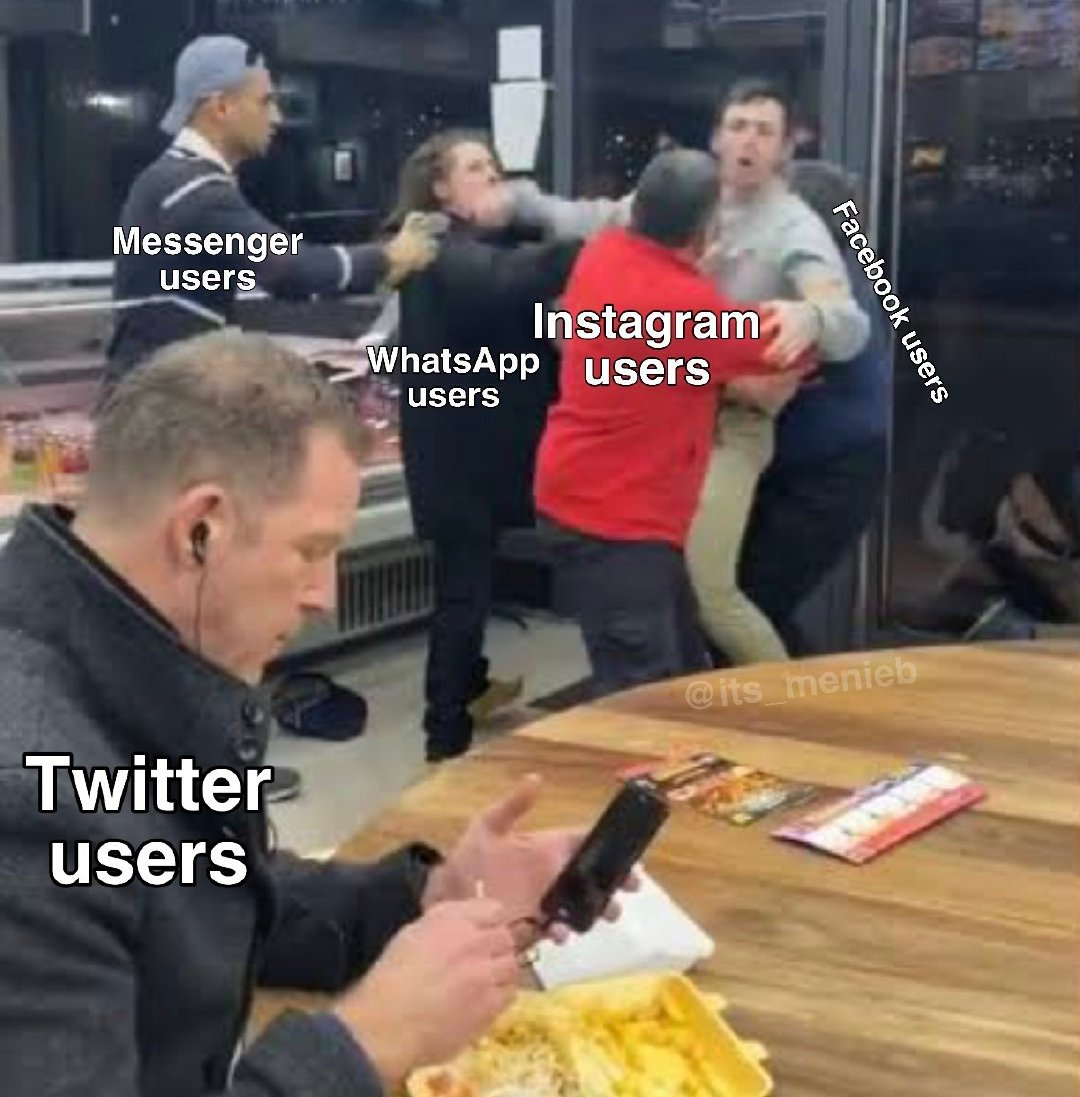
FaceBook 旗下几乎所有产品出现问题,大家发现 Twitter 还是可以用的,于是大量用户涌到 Twitter 去吐槽。

有的网友还用了最新的热门电视剧《鱿鱼游戏》来创作。
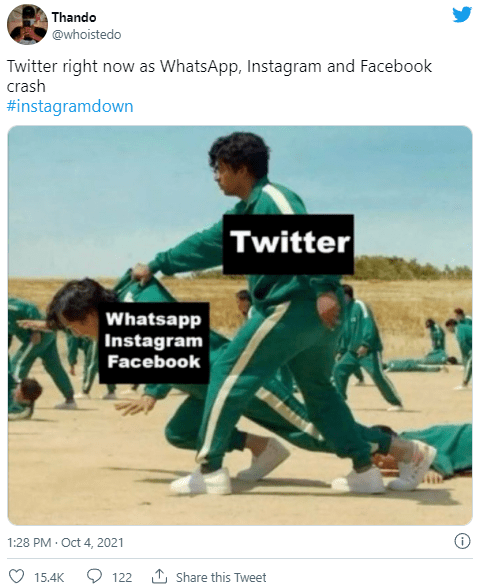
推特上像这样的创作有很多,都是推特嘲讽 Facebook、Instagram 和 WhatsApp 的表情包...

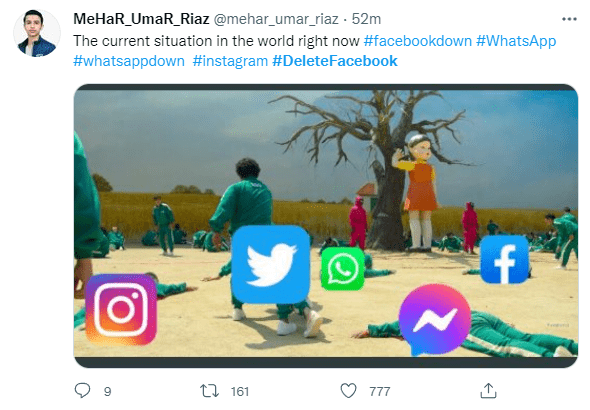
一时间,推特几乎躺着笑了...

3
到底发生了什么
作为一名技术人,在吃瓜的同时,也一定关注到底发生了什么?
这次 Facebook 宕机近6个小时,刷新了自 2008年最长宕机时长。
其中包括美国英国在内的数十个国家和地区发生了中断故障,直到4日下午开始恢复部分运营。
网站监测组织 Downdetector 称,这是其见过的最大规模此类故障,全球出现1060万份问题报告。
事故修复后,Facebook方面对此次宕机作出的解释是:
“脸书”的工程师错误地发出了一条指令,切断了“脸书”的数据中心“在全球范围内的所有网络连接”。
根据量子位的说明,Facebook 的网络工程师,日常需要维护部分主干网,比如增加更多容量,更新路由器软件等等。
那个工程师执行了一条,检测 Facebook 主干网络的命令,这个命令是有问题的,直接把 Facebook 主干网络的所有连接都给切断了。
比较巧合的是,在这个被切断的数据中心,还有一个工作,那就是响应 DNS 查询,作为程序员应该都知道 DNS 的作用。
就相当于告诉互联网,我家网站的地址在哪里,DNS 失效也就意味着短暂的将 Facebook 从互联网上抹掉了。
这就是本次 Facebook 惊魂 6 小时的原因。
后面 Facebook 安排工程师进入现场数据中心进行修复之后,网络服务也在10月4日下午4点左右逐渐恢复。
4
说2句
凡是有人参与的项目,都很难保证 100% 不出问题,哪怕是世界上最大的互联网公司..
就像这次,其实像这种大型互联网公司,网络工程师执行的每一个命令,都会有审计程序来负责二次校验。
而不巧的是,这次负责审计校验的程序,有一个 Bug ,漏掉了这个有问题的命令,就导致这次的校验没有拦截。
这种酸爽的感觉我太熟悉了。
我之前呆过的公司,遇到过很多生产问题,特别能体会到千万用户在等你恢复的那种心情。
曾经我们也遇到的 DNS 问题,导致网站和 APP一天都打不开,对 DNS 比较感兴趣的朋友可以看看:《一次dns缓存引发的惨案》
线上生产的救火故事,2017年的时候我写了很多,感兴趣可以点击链接看看:《百亿互金平台救火故事》
还有19年半夜 2 点的那个事故,差点让我惊出来一身冷汗,解决问题的方式也是出乎意料:
《凌晨1点突发致命生产事故,人工多线程来破局!》
这里再说一句不太正确的话:程序员的真正本领,好多都是在一次一次事故中锻炼出来的,大家一定要抓住这种机会!
遇到事故不要怕,沉住气,冷静下来往上上,等彻底解决问题之后,综合能力就会又刷新一遍!
想要赢,就得不怕输!
参考:
本文部分参考 公众号:量子位,以及部分网络内容
< END >
程序员摸鱼基地成立了!
纯洁的微笑读者交流群(摸鱼、白嫖技术课程为主),又不定时开放了,感兴趣的朋友,可以下方公号内回复:999
这篇关于Facebook 惊魂 6小时,影响 27 亿用户,市值蒸发百亿...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









