本文主要是介绍第二十三章 MySQL是怎么保证数据不丢的?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第二十三章 MySQL是怎么保证数据不丢的?
MySQL 能够保证数据不丢失的根据是什么 ?
根据 WAL 机制,只要 redo log 和 binlog 能保证持久化到磁盘,就能保证数据不丢失
binlog 的写入机制
binlog是怎么写入磁盘的 ?
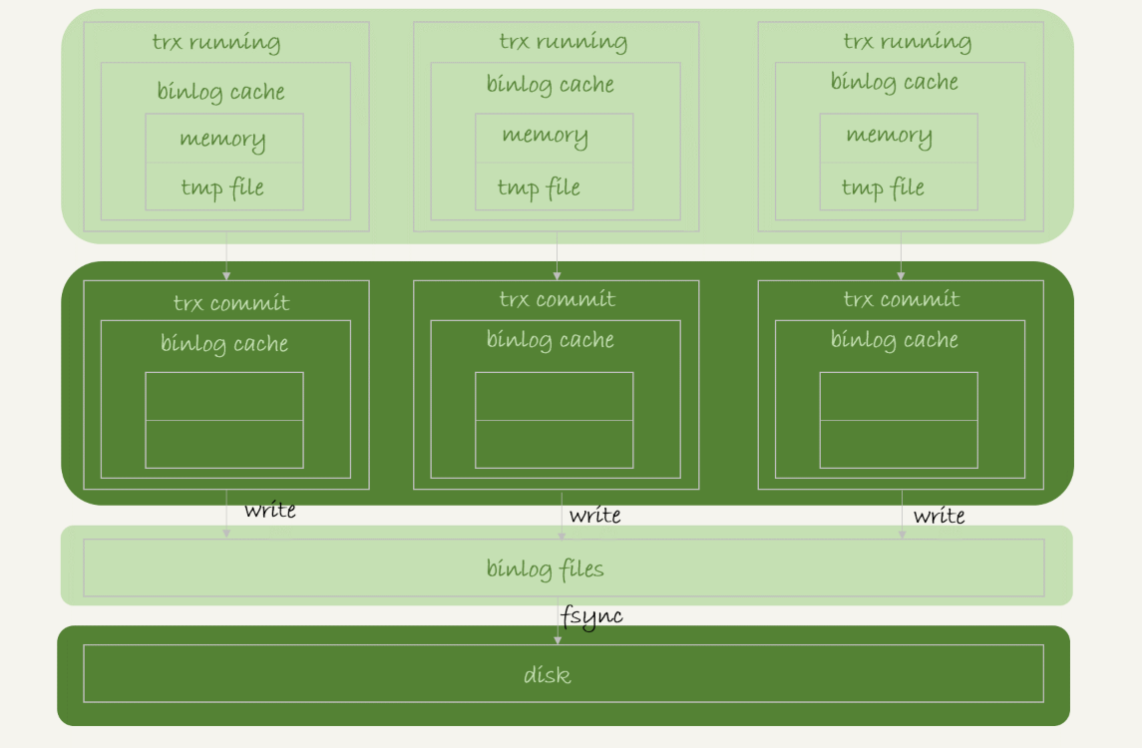
- 事务执行过程中,先把日志写到
binlog cache,事务提交的时候,再把binlog cache写到binlog文件中 - 事务执行过程中,每个线程会分配得到一片 binlog cache,由参数
binlog_cache_size控制binlog cache 大小(如果超过,则会暂存到磁盘) - 并将记录写到
binlog cahce中,由于一个事务中的 binlog 是不可拆分的,必须一次性全部写入 - 所以
binlog cache在 write 到 page cache 前,必定是全部收集事务记录完毕,并以事务为单位进行 write 工作 - 下图
write,是把日志写入到文件系统的 page cache (写入文件内存页缓存),没有持久化到磁盘,所以速度比较快 - 图中的
fsync,是将数据持久化到磁盘 (调用OS同步文件内存脏页到磁盘),占用磁盘的IOPS
binlog 的同步日志到磁盘,有哪些设置参数,介绍一下 ?
- 系统变量
sync_binlog sync_binlog=0的时候,表示每次提交事务都执行到 write(由OS决定 fsync 的时机)sync_binlog=1的时候,表示每次提交事务都会执行到 fsyncsync_binlog=N(N>1)的时候,表示每次提交事务都执行到 write,然后 page cahce 中的binlog 记录凑齐 N 个事务后才执行 fsync- 注意:将 sync_binlog 设置为 N,如果主机发生异常重启,会丢失最近 N 个事务的 binlog 日志
为什么
binlog写入数据是一次性全部写入,不能被打断 ?
- binlog 写入的前提条件是事务被提交,事务至少进入了 prepare 状态
- 如果一个事务的 binlog 能拆分写,则意味着在备库执行时,就相当于拆分成了多个事务段执行
- 此时就破坏了事务的原子性,可能会导致一些不可预知的问题
redo log 的写入机制
redo log buffer里面的内容,是不是每次生成后都要直接持久化到磁盘呢 ?
- 不需要
- 只有事务提交了才会从 redo log buffer 同步到 redo log 中
- 事务执行过程中写入 redo log buffer,还没有提交,如果数据库崩溃,由于事务没有提交,因此会回滚,所以 redo log buffer 中数据丢失也没有关系
redo log 可能存在的三种状态 ?
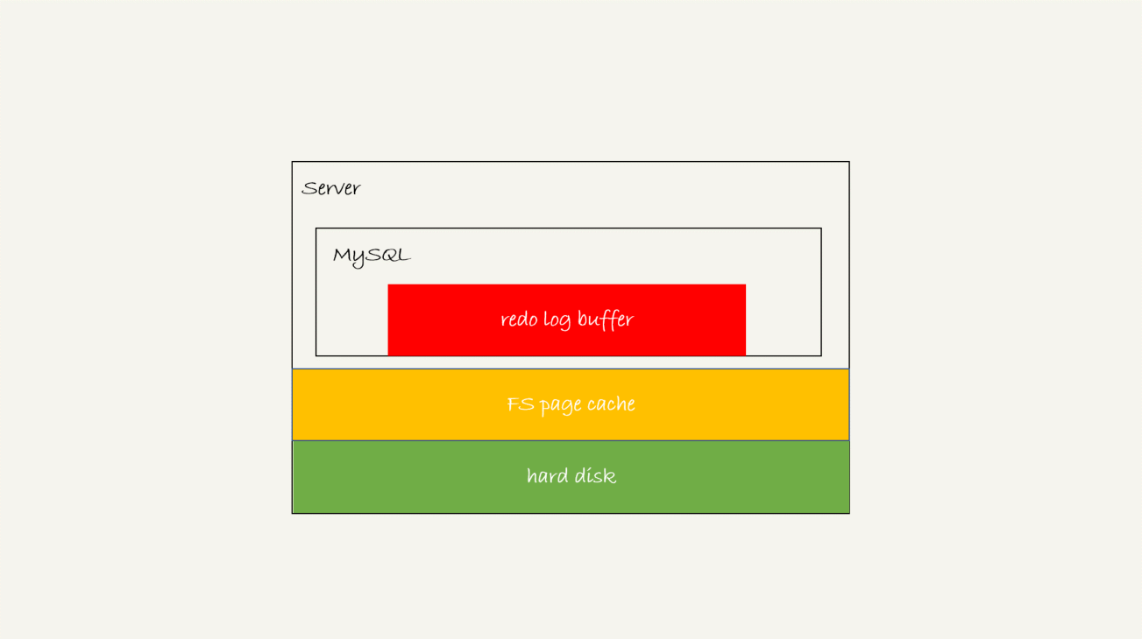
- 存在
redo log buffer中,物理上是在 MySQL 进程内存中,就是图中的红色部分 - 写到
磁盘 (write),但是没有持久化(fsync),物理上是在文件系统的page cache里面,也就是图中的黄色部分 持久化到磁盘,对应的是 hard disk,也就是图中的绿色部分
redo log 的同步日志到磁盘,有哪些设置参数,介绍一下 ?
- 系统变量
innodb_flush_log_at_trx_commit - 设置为
0的时候,表示每次事务提交时都只是把redo log留在redo log buffer中 - 设置为
1的时候,表示每次事务提交时都将redo log直接持久化到磁盘 - 设置为
2的时候,表示每次事务提交时都只是把redo log写到page cache
事务还没提交的时候,
redo log buffer中的部分日志有没有可能被持久化到磁盘呢 ?
- 有可能
- InnoDB 有一个
后台线程,每隔 1 秒,就会把redo log buffer中的日志,调用write写到文件系统的page cache,然后调用fsync持久化到磁盘- 事务执行中间过程的 redo log 也是直接写在 redo log buffer 中的,这些 redo log 也会被后台线程一起持久化到磁盘
- 也就是说,一个没有提交的事务的 redo log,也是可能已经持久化到磁盘的
- 如果
redo log buffer大小达到innodb_redo_log_buffer_size的大小(16MB)的一半,则后台线程会主动写盘- 注意:由于事务还没有提交,因此不会持久化到磁盘,仅写到文件系统缓存页 (page cache)
- 如果
innodb_flush_log_at_trx_commit设置为1,则事务提交时,会将其他事务尚未提交的redo log buffer中的记录全部持久化到磁盘中
当
innodb_flush_log_at_trx_commit设置为1时,为什么redo log在prepare阶段就要持久化一次到磁盘 ?
- 为1时,是保证所有 redo log 记录不丢失
- MySQL 可以根据 redo log 的 prepare 和 对 binlog 的判定来判断事务是否生效
binlog写完,redo log 还没 commit 前发生crash:- 如果
redo log里面的事务是完整的,也就是已经有了commit标识,则直接提交 - 如果
redo log里面的事务只有完整的prepare,则判断对应的事务 binlog 是否存在并完整:a. 如果是,则提交事务;b. 否则,回滚事务
- 如果
- 因此
prepare阶段的 redo log 也是可以起到数据恢复作用的
当
innodb_flush_log_at_trx_commit设置为1时,为什么说事务commit阶段不用再fsync到磁盘了 ?
- 事务的
commit阶段指的是事务提交过程中,最后 redo log 被标记为 commit 的阶段 - 后台线程每隔1秒会将
redo log buffer中的数据刷到page cahce,再fsync到磁盘 - 此时这些记录包含了 prepare 标识的数据,但 MySQL 在重放日志时候,可以根据 redo log的 prepare 标识再判断 binlog 的完整性等等从而进行恢复
- 所以这时候,这些 prepare 表示的 redo log 提交时,就不会再
fsync到磁盘一次 - 这样做的目的是减少磁盘IO开销
什么是 MySQL 的
双1设置 ?
sync_binlog和innodb_flush_log_at_trx_commit都设置成 1- 一个事务完整提交前,需要等待两次刷盘:
redo log(prepare 阶段)持久化到磁盘binlog持久化到磁盘
组提交(group commit)
介绍一下日志逻辑序列号 ?
- log sequence number,简称 LSN
- LSN 是单调递增的,对应每个 redo log 的写入点,值为
上一个写入点+本次写入的 redo log 长度 - LSN 也会写到 InnoDB 的数据页中,来确保数据页不会被多次执行重复的 redo log
两阶段提交
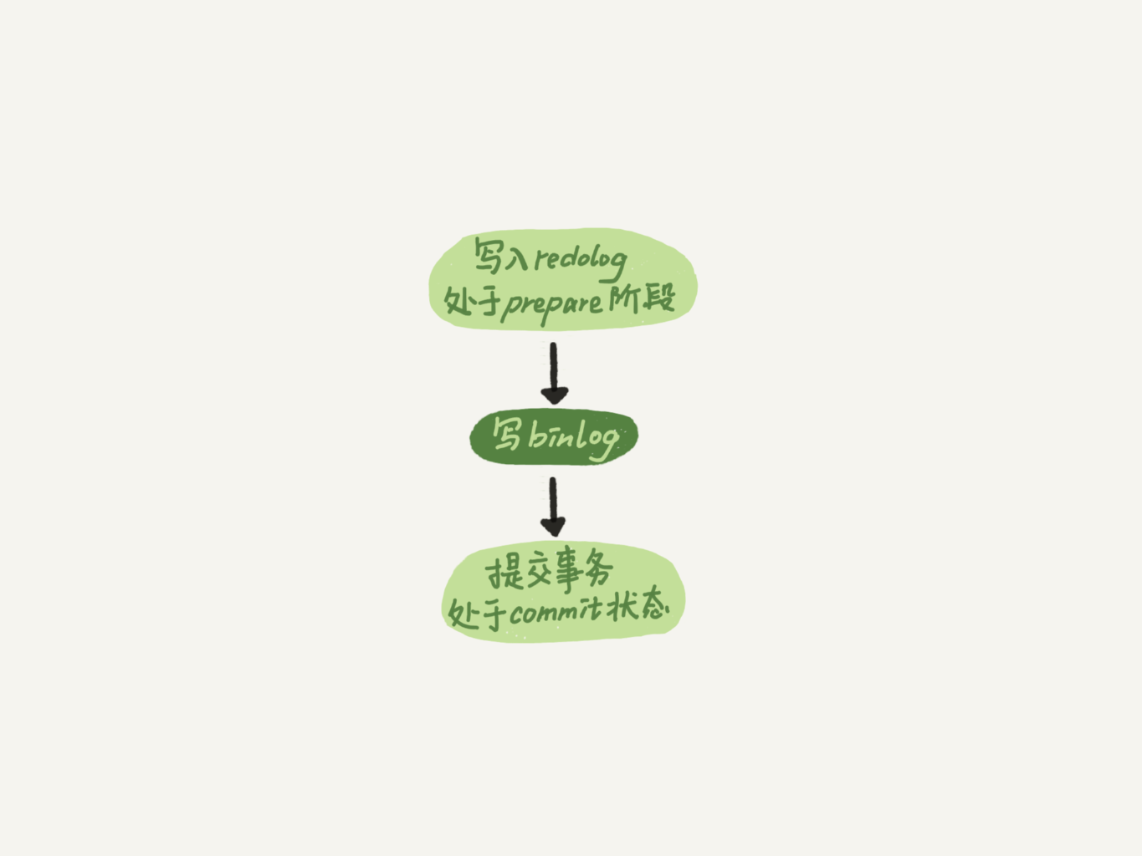
写 binlog 其实是分成两步的:
- 先把 binlog 从 binlog cache 写到内存中的 page cache
- 调用 fsync 持久化到磁盘上的 binlog 文件
对于组提交中,组员越多,节约IOPS效果越好这一点,你知道MySQL还做了什么优化吗 ?
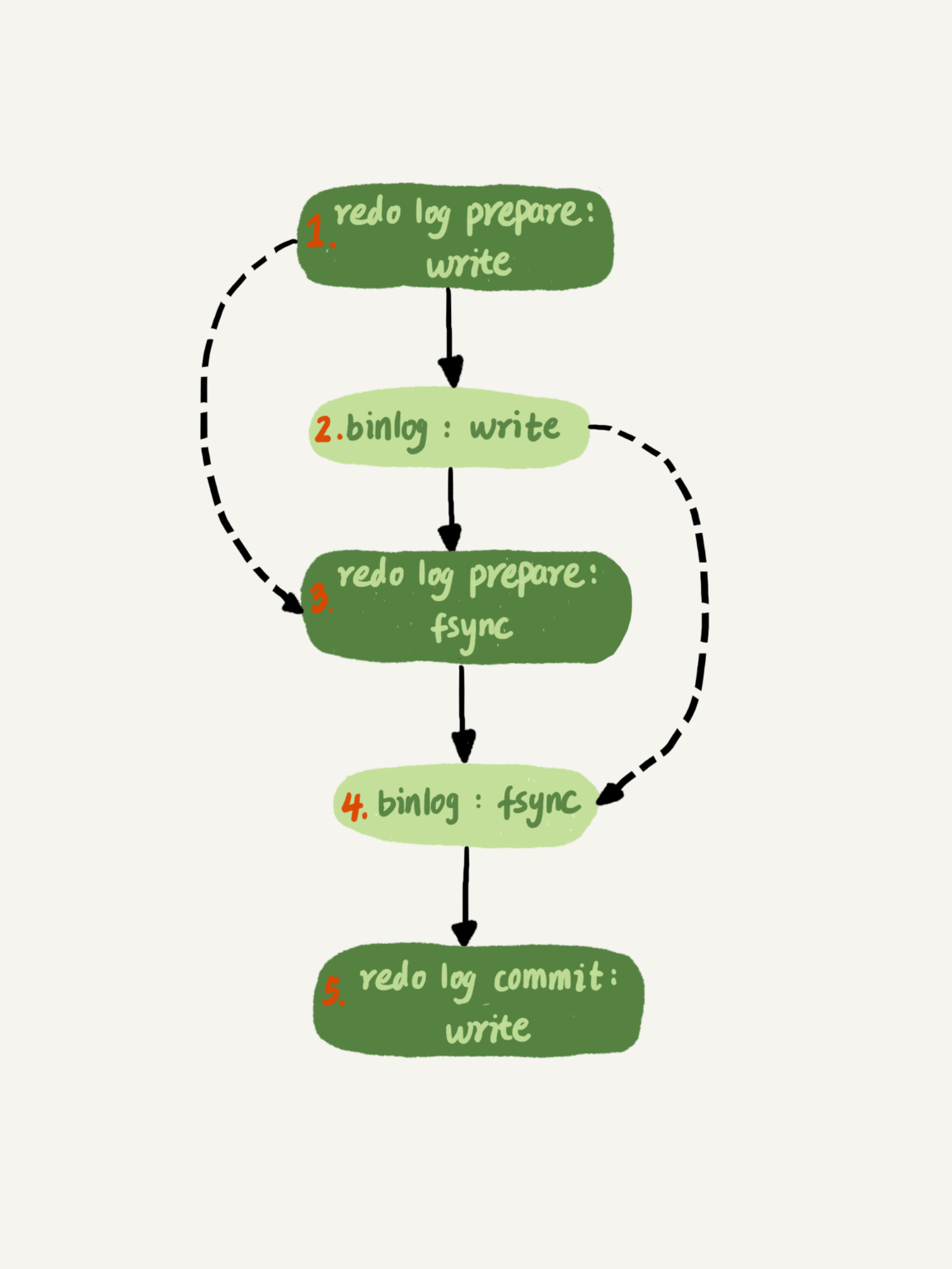
binlog执行fsync时,也会将其他的位于 page cache 的binlog一并进行fsync,但由于binlog的write和fsync间隔很短,所以往往效果不明显- MySQL 提供了两个参数:
binlog_group_commit_sync_delay参数,表示延迟多少微秒后才调用 fsyncbinlog_group_commit_sync_no_delay_count参数,表示累积多少次以后才调用 fsync
WAL机制是减少磁盘写,但是每次提交事务都要写 redo log 和 binlog,这样读写次数不是很多吗 ?
WAL 机制主要得益于两个方面:
- redo log 和 binlog 都是顺序写,磁盘的顺序写比随机写速度要快
- 组提交机制,可以大幅度降低磁盘的 IOPS 消耗
如果你的 MySQL 现在出现了性能瓶颈,而且瓶颈在 IO 上,可以通过哪些方法来提升性能呢 ?
- 将 binlog 的提交延迟设置大一点,增加
组提交的组员,减少写盘次数 - 将
sync_binlog设置为大于1的值,但这可能导致出现数据丢失的风险(主机宕机时) - 将
innodb_flush_log_at_trx_commit设置为2,但这可能导致出现数据丢失的风险(主机宕机时)
设置
innodb_flush_log_at_trx_commit为 0 会怎么样 ?
- 不建议把
innodb_flush_log_at_trx_commit设置成 0 - 设置成 0,表示 redo log 是保存在 MySQL 进程中的内存缓存的,如果 MySQL 异常重启数据直接就丢失了
- 设置成 2,表示 redo log 是写到了操作系统的
page cache了,会在合适时候 fsync 到磁盘,所以即使MySQL 进程重启了也不影响
为什么
binlog cache是每个线程自己维护的,而redo log buffer是全局共用的 ?
- binlog 是不能“被打断的”。一个事务的 binlog 必须连续写,因此要整个事务完成后,再一起写到文件里
- binlog 是一种
逻辑性的日志,记录的是一个事务完整的语句 - 当用来做主从同步时,如果分散写,可能造成事务不完整,分多次执行,从而导致不可预知的问题
- 而 redo log 属于
物理性的日志,记录的是物理地址的变动。因此,分散写也不会改变最终的结果
事务执行期间,还没到提交阶段,如果发生 crash 的话,redo log 肯定丢了,这会不会导致主备不一致呢 ?
- 不会
- 因为这时候 binlog 也还在 binlog cache 里,没发给备库
- crash 以后 redo log 和 binlog 都没有了,从业务角度看这个事务也没有提交,所以数据是一致的
一个极端的场景:若事务提交后,binlog 写完,主库同步 binlog 给备库执行,但主库尚未给客户端答复时,主库挂掉了,那么事务算失败了吗 ?
- 不算,此时客户端会收到网络连接失败的反馈
- 数据库的
crash-safe保证的是:- 如果客户端收到事务成功的消息,事务就一定持久化了
- 如果客户端收到事务失败(比如主键冲突、回滚等)的消息,事务就一定失败了
- 如果客户端收到 “执行异常” 的消息,应用需要重连后通过查询当前状态来继续后续的逻辑。此时数据库只需要保证内部(数据和日志之间,主库和备库之间)一致就可以了
这篇关于第二十三章 MySQL是怎么保证数据不丢的?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






