本文主要是介绍第二十章 幻读是什么,幻读有什么问题?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第二十章 幻读是什么,幻读有什么问题?
CREATE TABLE `t` (`id` int(11) NOT NULL,`c` int(11) DEFAULT NULL,`d` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `c` (`c`)
) ENGINE=InnoDB;insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
- 下面的语句序列,是怎么加锁的,加的锁又是什么时候释放的呢 ?
begin;
select * from t where d=5 for update;
commit;
select ... for update:- 对于
非索引字段进行update或select .. for update操作,代价极高。所有记录上锁,以及所有间隔的锁 - 对于
索引字段进行上述操作,代价一般。只有 索引字段 本身和 附近的间隔 会被加锁 select ... for update是为了在查询时,对这条数据进行加锁,避免其他用户以该表进行插入、修改或删除等操作,造成表的不一致性
- 对于
关于 “这个语句会命中
d=5的这一行,对应的主键id=5,因此在 select 语句执行完成后,id=5 这一行会加一个写锁,而且由于两阶段锁协议,这个写锁会在执行 commit 语句的时候释放” 这句话的理解由于字段 d 上没有索引,因此这条查询语句会做全表扫描。那么,其他被扫描到的,但是
不满足条件的 5 行记录上,会不会被加锁呢?
RR (可重复读)级别:扫描到的数据都会加 行锁 和 间隙锁RC (读提交)级别:扫描到的数据都会加行锁,但是不满足条件的数据,没有到 commit 阶段,就会被释放,违反了两阶段加锁原则- 全表扫描一直指的是扫描主键索引
什么是幻读 ?
InnoDB 的默认隔离级别是 可重复读
share in mode:当前读,给数据加读锁
for update:当前读,给数据加写锁
什么是幻读 ?
- 在同一个事务中,两次读取到的数据不一致的情况,称为
幻读和不可重复读 幻读是针对insert导致的数据不一致不可重复读是针对delete、update导致的数据不一致可重复读隔离级别下,事务内查询用 “当前读”,读到本事务外新增的数据,称为 幻读- 幻读 是用户在使用 可重复读 隔离级别下,在进行 select 查询时加
IX锁、IS锁才可能出现的,是用户主动打破业务层面上的查询时的一致性视图隔离性 - 其不属于事务隔离的
可见性规则问题(可见性规则是来解决各种事务问题的),而是用户在使用上出现的问题,属于业务问题
什么是
快照读? 什么是当前读?
当前读指的是select for update或者select in share mode,指的是在更新之前必须先查询当前的值,因此叫当前读快照读指的是在语句执行之前或者在事务开始的时候会创建一个视图,后面的读都是基于这个视图的,不会再去查询最新的值
当前读 具体包括哪些操作 ?
for update、lock in share mode、update、delete、insert都是当前读的规则,就是读取最新的已经提交的数据update先查询再修改,这里的查询就是使用的当前读delete要先查询再删除,这里的查询也是要当前读insert的时候,要判断主键是否已经存在、是否违反唯一约束,此时查看主键是否存在的查询也是当前读
幻读 和 脏读 的区别 ?
- 幻读是读到了提交了的数据,而脏读是读到了没提交的脏数据
- 在
读提交的隔离级别下,没有讨论幻读的实际意义 - 而在
可重复读隔离级别下,当前读打破了视图的隔离限制,实现了读到不应该读的数据的作用
在
可重复读的隔离级别下,幻读只会在查询为哪种性质时才会出现 ?
- 由于
一致性视图的作用,因此幻读只会在 “当前读” 情况下发生
幻读 跟 事务的可见性规则 冲突吗 ?
- 在
可重复读隔离级别下,幻读是用户选择使用当前读而产生的,符合 当前读 的规则,也不跟事务的可见性规则相矛盾
幻读有什么问题 ?
select .. lock in share mode和select ... for update的区别 ?
select .. lock in share mode走的是IS锁(意向锁)- 即在符合条件的 rows 上都加了
共享锁,这样的话,其他session可以读取这些记录,也可以继续添加IS 锁,但是无法修改这些记录直到你这个加锁的session执行完成 (否则直接锁等待超时)
- 即在符合条件的 rows 上都加了
select ... for update走的是IX锁 (意向排它锁)- 即在符合条件的 rows 上都加了排它锁,其他 session 也就无法在这些记录上添加任何的
IS锁或IX锁
- 即在符合条件的 rows 上都加了排它锁,其他 session 也就无法在这些记录上添加任何的
- 如果
不存在 一致性非锁定读的话,那么其他 session 是无法读取和修改这些记录的 - 但是
innoDB 存在 非锁定读(快照读并不需要加锁),for update之后并不会阻塞其他 session 的快照读取操作 - 除了
select ...lock in share mode和select ... for update这种显示加锁的查询操作 - 通过对比,发现
for update的加锁方式无非是比lock in share mode的方式多阻塞了select...lock in share mode的查询方式,并不会阻塞快照读
幻读 产生的原因 ?
- 注意:
binlog日志是在commit提交时才进行记录的 - 即使给所有行加上了锁,也避免不了
幻读 - 这是因为给行加锁的时候,这条记录还不存在,没法加锁
- 例如下面这种情况:假设扫描到的行都被加上了
行锁
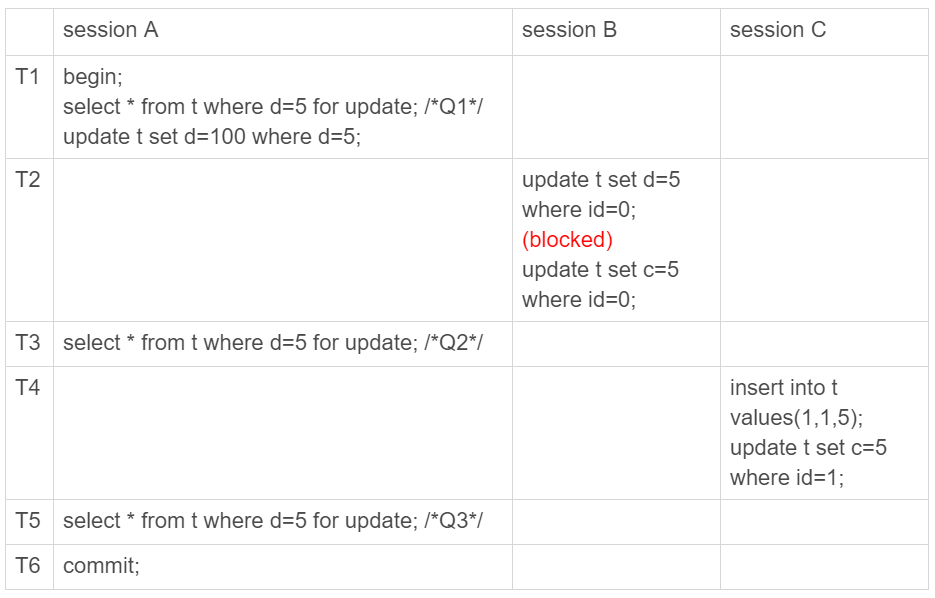
- 由于 session A 把所有的行都加了写锁,所以 session B 在执行第一个 update 语句的时候就被锁住了,需要等到 T6 时刻 session A 提交以后,session B 才能继续执行
- 在
binlog里面,执行序列是这样的:
insert into t values(1,1,5); /*(1,1,5)*/
update t set c=5 where id=1; /*(1,5,5)*/update t set d=100 where d=5;/*所有d=5的行,d改成100*/update t set d=5 where id=0; /*(0,0,5)*/
update t set c=5 where id=0; /*(0,5,5)*/
- 按照日志顺序执行,id=0 这一行的最终结果也是
(0,5,5)。所以,id=0 这一行的问题解决了 - 但是你可以看到,
id=1这一行,在数据库里面的结果是(1,5,5),而根据binlog的执行结果是(1,5,100),也就是说 幻读 的问题还是没有得到解决- 原因是:在
T3时刻,我们给所有行加锁的时候,id=1这一行还不存在,不存在也就加不上锁
- 原因是:在
如何解决幻读 ?
如何解决
幻读?
- InnoDB 在
行锁的基础上,引入了间隙锁 (Gap Lock) - 间隙锁,锁的就是两个值之间的空隙
- 比如文章开头的表 t,初始化插入了 6 个记录,这就产生了 7 个间隙
insert into t values(0,0,0),(5,5,5),
(10,10,10),(15,15,15),(20,20,20),(25,25,25);
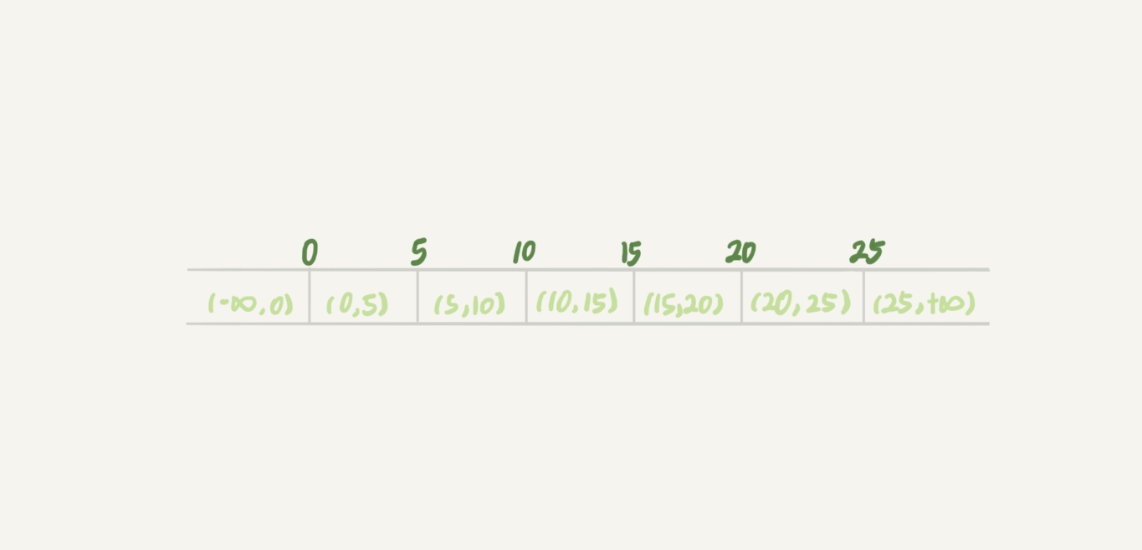
- MySQL 会对扫描经过的索引对象,加上间隙锁
行锁 和 行锁 之间会产生冲突,那 间隙锁 和 间隙锁 之间,也会产生冲突吗 ?
- 行锁分为:读锁、写锁
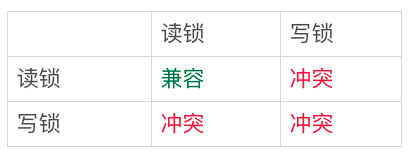
- 行锁:
读锁之间不冲突,写锁与读锁冲突,写锁与写锁冲突 - 但是,跟
间隙锁存在冲突关系的,是 “往这个间隙中插入一个记录” 这个操作 - 间隙锁 与 间隙锁 之间,都不存在冲突关系
什么是
next-key lock?
间隙锁和行锁合称next-key lock,每个next-key lock是前开后闭区间- 如果用
select * from t for update要把整个表所有记录锁起来,就形成了 7 个next-key lock,分别是(-∞,0]、(0,5]、(5,10]、(10,15]、(15,20]、(20, 25]、(25, +supremum] - 间隙锁只是锁间隙,没有锁住记录行,而 next-key lock 就是间隙锁基础上锁住右边界行
- 间隙锁:( )
开区间 - next-key lock:( ]
前开后闭区间 - 如果是表的最后一行数据,则下一个区间是这行数据到表索引的
不存在的最大值,也就是+supremum
引入 间隙锁 后,可能会导致什么问题 ?
- 首先需要了解 间隙锁 的特性:锁的是间隙,是禁止其他操作往间隙中插入数据的。因此间隙锁与间隙锁之间不冲突
- 所以在 AB 两个事务当中
A事务随机查询某一条数据(+排它锁,也就是for update)的方式产生间隙锁B事务也执行同一条SQL,随后 A事务 判定数据不存在时,对其插入,B事务也同样如此操作,则最终导致 A事务 等待 B事务 的间隙锁,B事务 也在等待 A事务 的间隙锁,这将导致死锁- 当然,由于 InnoDB 有开启死锁检测,最后 A事务 报错返回
- 但是,间隙锁 会影响数据的并发度
除了引入
间隙锁, 还有什么方式可以解决幻读?
- 将
RR (可重复读)改为RC (读提交),则不存在幻读问题 - 但此时需要将
binlog格式改为row,否则可能出现 数据 和 日志 不一致的问题
为什么
RC (读提交)下,需要将binlog格式改为row呢 ?
- RC 没有幻读问题,也没有间隙锁,但在显示控制事务
更新时 - 若在 事务A 还未提交之前,有别的 事务B 后执行并且添加的数据是 事务A 的更新语句逻辑层面会命中的条件
- 那等 事务A 提交之后,statement 的 binlog 记录上,事务B的记录在前,而事务A的记录在后(这没毛病,谁先提交谁先记录,但恢复的时候会产生问题)
- 当执行日志恢复时,后提交的
事务A的记录会把事务B的记录也进行更新,这就导致了数据恢复错误 - 此时,如果改成
row格式,binlog会具体记录语句的各项条件,这样在恢复时便不会恢复错误了 - 注意:除了恢复,还有主从库的同步也会有这个问题
- 举个例子:
- 例子一:
- 删除
statement记录的是这个删除的语句
delete from t where age>10 and modified_time<='2020-03-04' limit 1;
- 而
row格式记录的是实际受影响的数据是真实删除行的主键id
delete from t where id=3 and age=12 and modified_time='2020-03-05';
- 例子二:
-- statemnt格式
begin;
update t set d=5 where id=0;
commit;-- row格式
begin;
update t where id=0 and c=0 and d=0
set id=0,c=0,d=5
commit;
关于row格式的参考资料
为什么要把MySQL的binlog格式修改为row
大家都用
读提交,可是逻辑备份的时候,mysqldump为什么要把备份线程设置成可重复读呢 ?
- 官方自带的逻辑备份工具是
mysqldump - 当
mysqldump使用参数–single-transaction的时候,导数据之前就会启动一个事务,来确保拿到一致性视图 - 因为
RR (可重复读)的一致性读视图可以保证 数据备份时,不阻塞其他数据写入
在备份期间,
备份线程用的是可重复读,而业务线程用的是读提交。同时存在两种事务隔离级别,会不会有问题 ?
- 没有问题,不管是
读提交还是可重复读,都是 MVCC 支持 - 备份是从某个快照时间之后开始的,数据是固定一致准确的
一条加了
排它锁的查询语句,如果查询是全表扫描,那么扫描过的语句会如何 ?
- 在
可重复读隔离级别下,MySQL 会对扫过的语句加next-key lock
总结
- 可
重复读更新时采用当前读,这是为了防止数据丢失 - 但使用
当前读,可能造成更新层面语义的破坏和日志数据 不一致的问题 - 为解决
更新层面的幻读问题,可重复读时,引入了next-key lock - 若是直接采取
读提交,则解决了语义层面的破坏,但需要通过将binlog改为max或row的形式,防止日志数据不一致
这篇关于第二十章 幻读是什么,幻读有什么问题?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






