本文主要是介绍第十九章 为什么我只查一行的语句,也执行这么慢?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第十九章 为什么我只查一行的语句,也执行这么慢?
查询长时间不返回
一条查询语句始终无返回,可能是因为什么原因导致的 ?
- 可能在等待
MDL 锁释放- 查询语句执行时申请的是
MDL 读锁,若之前有MDL 写锁处于申请中或正持有中,则MDL 读锁等待
- 查询语句执行时申请的是
- 可能在等待
flush 锁(在第六章讲过flush tables with read lock会加全局读锁)- 执行
flush statement类语句可能发生锁等待,其中:flush tables with read lock:会关闭所有打开的表并给所有的表在库层级添加一个全局的读锁flush tables with read lock:不会被其他会话的事务阻塞。例如开启一个会话事务,更新,然后直接执行本会话 flush,此时再执行上一个会话事务的提交,提交由于 flush 进入了阻塞,在等待 flush 被unlock 之后,该事务的提交继续执行。(想要复现flush tables with read lock被阻塞的场景,可以让select sleep(60) from t来进行 —— 原理是持续不断地打开表对象)flush table t with read lock:会首先获取 t 表的MDL写锁,因此它要首先等待所有打开 t 表的事务完成,然后才从表缓存中对表进行刷新,重新打开表,并获取表锁,随后将 MDL 写锁降级为 MDL 读锁。在获得表锁并进行 MDL 写锁降级后,其他连接可以读取该表,但不能更新表(DML、DDL)flush table t with read lock:反而会被对应表的其他事务给阻塞到
- 执行
- 可能在等待行锁
- 如果查询的语句加了读锁 ——
lock in share mode,那当 读取的数据有写锁占用时,查询线程将被阻塞lock in share mode:是要求当前读,也就是要读取最新的数据- 不加锁就是 一致性读,最开始读到什么,即使中间有人更新了,也读的是旧值
- 如果查询的语句加了读锁 ——
怎么排查查询语句很久没有反馈的情况 ? 讲一下你的步骤流程 ?
-- 查看当前库的所有线程
show processlist;
- 此外,还可以通过 performance_schema 库 和 sys 库 来排查
show variables like '%performance_schema%';
set performance_schema = 'ON';
-- 开启此功能,会有10%的性能开销
- 随后,执行
select * from performance_schema.setup_instruments where name='wait/lock/metadata/sql/mdl';
-- 若结果两者非YES,需设置YES,才可继续UPDATE performance_schema.setup_instruments SET ENABLED = 'YES', TIMED = 'YES' where name='wait/lock/metadata/sql/mdl';
- 那么,当出现查询线程被阻塞时,可以在其他会话执行
SELECT * from sys.schema_table_lock_waits;
SELECT blocking_pid from sys.schema_table_lock_waits;
- 即可查出当前持有锁的线程

- 建议销毁线程时,执行
kill X而非kill query X - 因为当线程正在执行的语句非查询语句时,后者是无效的方法
数据量极少但查询很慢
什么情况下,数据量极少,但查询却很慢呢 ?
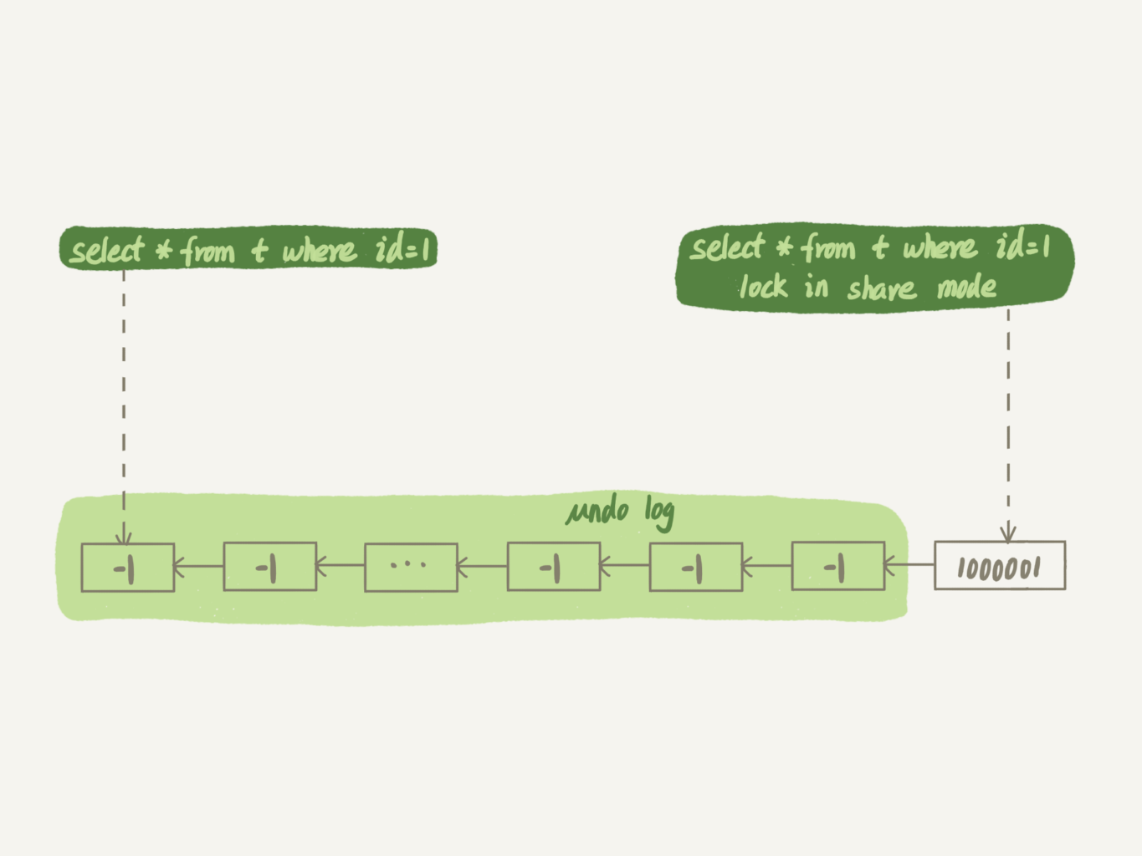
- 热点更新语句,其在 MVCC 控制下,当前事务与最新数据版本间的回滚段过长时,查询会很慢
- 一般直接加读锁(会进行当前读)进行验证当前数据与事务一致性视图下的数据差异
- 例如下面这个语句:
select * from t where id=1;
select * from t where id=1 lock in share mode;

这篇关于第十九章 为什么我只查一行的语句,也执行这么慢?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


