本文主要是介绍PowerBI:如何在以SharePoint文件做为数据源?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题描述:
有朋友最近询问,在PowerBI中如何以SharePoint中的文件做为数据源,进行报告的设计开发?
今天抽一些时间,为大家做一个样例,供大家参考。
解决方案:
- 找到将要使用的SharePoint中文件的Web link地址,此步最为关键;
- 打开Power BI,通过Web link文件地址,成功文件作为Power BI数据源;
操作步骤:
1,在一个测试使用的SharePoint站点,上传我们的测试Excel文件;
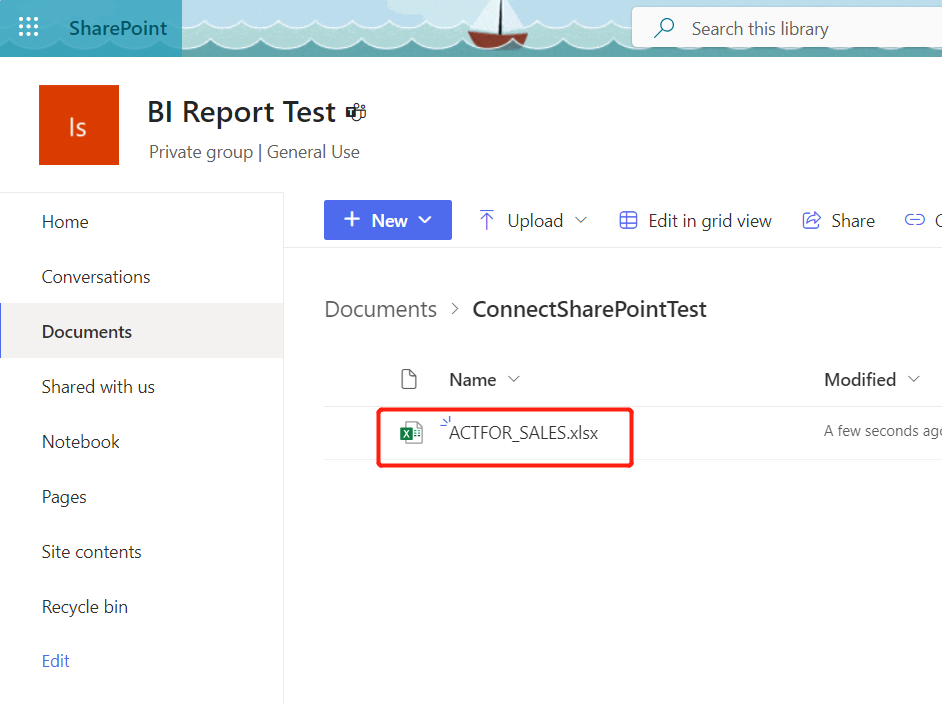
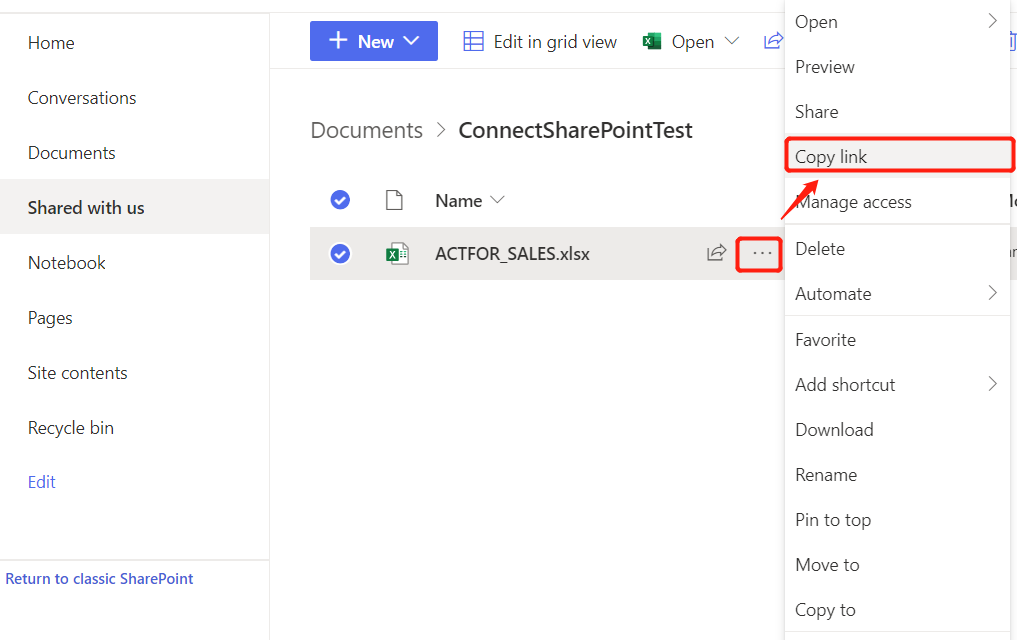
2,获取上传Excel文件的Web link 地址: 点击【---】 -> 【Copy link】;
获取到Link地址后还不能使用,这是一个假地址,需要进一步处理:
需要检查获取的SharePoint Web link地址,如果地址中存在/x,/r,/:x:请删除,同时地址信息仅保留到以teams为关键字的下一级目录即可。
- 样例地址:https://xxxx.sharepoint.com/:x:/r/teams/SharePointTest/Shared%20Documents/ACTFOR_SALES.xlsx?d=w812341&e=nz335bt
- 修改后地址: https://xxxx.sharepoint.com/teams/SharePointTest/
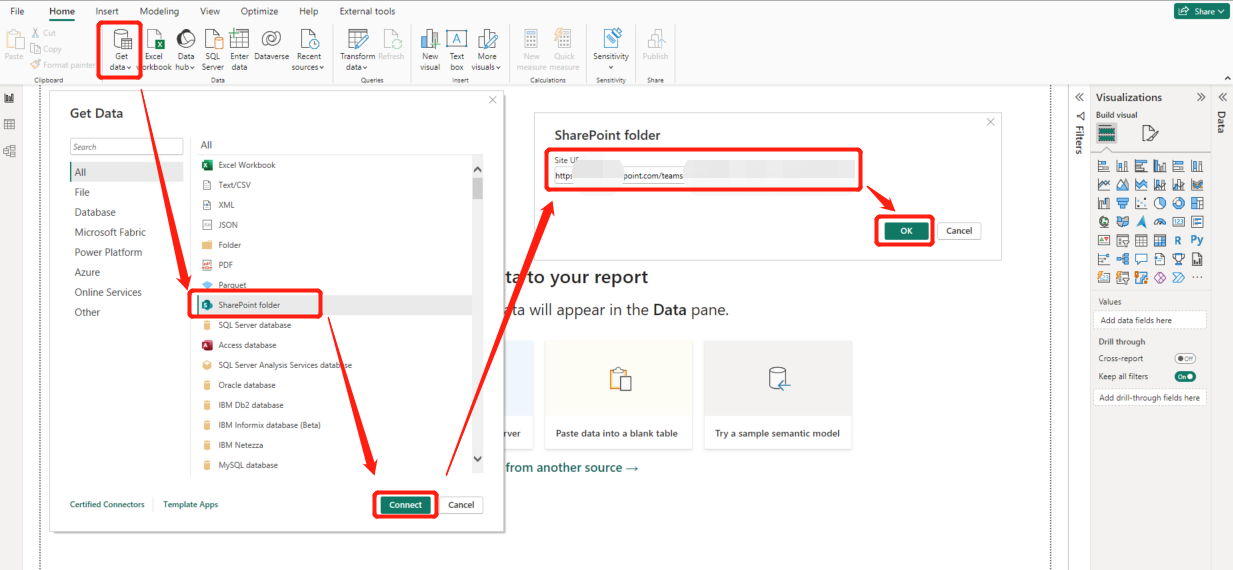
3,打开Power BI, 连接SharePoint作为数据源:
【Get data】 -> 【SharePoint folder】 -> 【Connect】 -> 在SharePoint folder弹出框中输入真实的Web link地址 -> 【Ok】;
4,界面显示获取了当前目录下的所有文件,我们仅保留我们需要连接的Excel文件即可。
点击【Transform Data】进行数据的处理和过滤操作。

5,通过【Name】列名称筛选,仅保留需要连接的Excel文件;
此时有同学要问:“为什么我看不到Excel文件的内容?”
这是个好问题,此时我们需要把Excel文件扩展出来:
点击【Content】列的双下箭头 -> 选择Excel中要使用的Sheet页(这里我们选择Sheet1)-> 【OK】
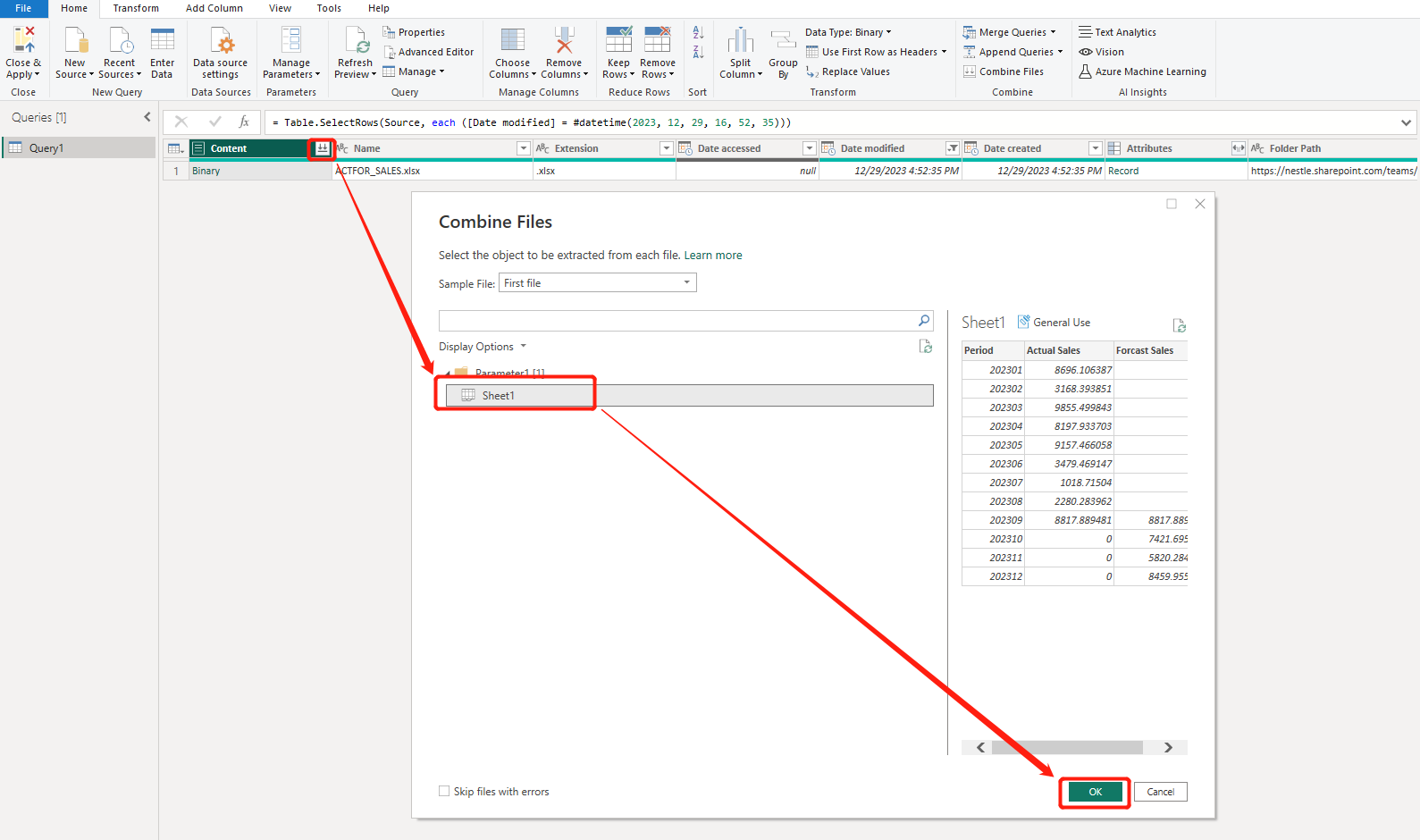
6,这时你就可以看到连接的Excel的所有列的信息,并用于报告的设计和开发。
本篇仅为读者拓宽使用思路和操作方法,在大家使用工作中会有类似场景会用到。
建议大家亲自做一下练习,便于消化吸收。
希望本文可以帮助到大家。
这篇关于PowerBI:如何在以SharePoint文件做为数据源?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







