本文主要是介绍【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Flink 系列文章
一、Flink 专栏
Flink 专栏系统介绍某一知识点,并辅以具体的示例进行说明。
-
1、Flink 部署系列
本部分介绍Flink的部署、配置相关基础内容。 -
2、Flink基础系列
本部分介绍Flink 的基础部分,比如术语、架构、编程模型、编程指南、基本的datastream api用法、四大基石等内容。 -
3、Flik Table API和SQL基础系列
本部分介绍Flink Table Api和SQL的基本用法,比如Table API和SQL创建库、表用法、查询、窗口函数、catalog等等内容。 -
4、Flik Table API和SQL提高与应用系列
本部分是table api 和sql的应用部分,和实际的生产应用联系更为密切,以及有一定开发难度的内容。 -
5、Flink 监控系列
本部分和实际的运维、监控工作相关。
二、Flink 示例专栏
Flink 示例专栏是 Flink 专栏的辅助说明,一般不会介绍知识点的信息,更多的是提供一个一个可以具体使用的示例。本专栏不再分目录,通过链接即可看出介绍的内容。
两专栏的所有文章入口点击:Flink 系列文章汇总索引
文章目录
- Flink 系列文章
- 一、maven依赖
- 二、示例:时态表的join(scala版本)
- 1)、统计需求对应的SQL
- 2)、Without connnector 实现代码
- 3)、With CSVConnector 实现代码
本文给以scala的语言给出来Table API 针对时态表的join操作。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文除了maven依赖外,没有其他依赖。
本文需要有kafka的运行环境。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
一、maven依赖
本文maven依赖参考文章:【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表 中的依赖,为节省篇幅不再赘述。
二、示例:时态表的join(scala版本)
该示例来源于:https://developer.aliyun.com/article/679659
假设有一张订单表Orders和一张汇率表Rates,那么订单来自于不同的地区,所以支付的币种各不一样,那么假设需要统计每个订单在下单时候Yen币种对应的金额。
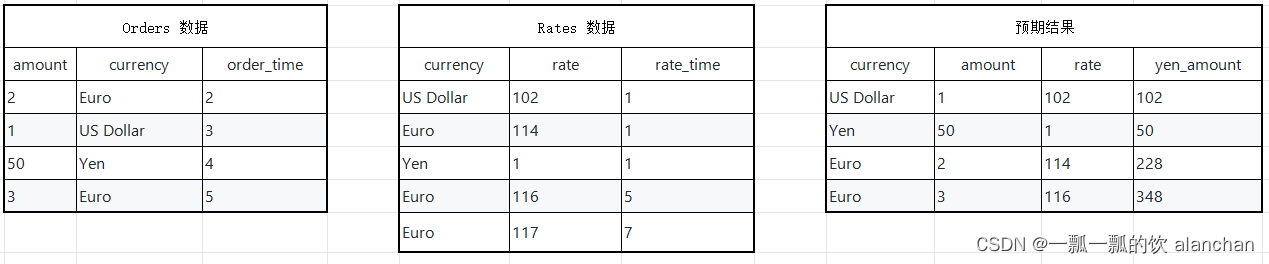
1)、统计需求对应的SQL
SELECT o.currency, o.amount, r.rateo.amount * r.rate AS yen_amount
FROMOrders AS o,LATERAL TABLE (Rates(o.rowtime)) AS r
WHERE r.currency = o.currency2)、Without connnector 实现代码
object TemporalTableJoinTest {def main(args: Array[String]): Unit = {val env = StreamExecutionEnvironment.getExecutionEnvironmentval tEnv = TableEnvironment.getTableEnvironment(env)env.setParallelism(1)
// 设置时间类型是 event-time env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)// 构造订单数据val ordersData = new mutable.MutableList[(Long, String, Timestamp)]ordersData.+=((2L, "Euro", new Timestamp(2L)))ordersData.+=((1L, "US Dollar", new Timestamp(3L)))ordersData.+=((50L, "Yen", new Timestamp(4L)))ordersData.+=((3L, "Euro", new Timestamp(5L)))//构造汇率数据val ratesHistoryData = new mutable.MutableList[(String, Long, Timestamp)]ratesHistoryData.+=(("US Dollar", 102L, new Timestamp(1L)))ratesHistoryData.+=(("Euro", 114L, new Timestamp(1L)))ratesHistoryData.+=(("Yen", 1L, new Timestamp(1L)))ratesHistoryData.+=(("Euro", 116L, new Timestamp(5L)))ratesHistoryData.+=(("Euro", 119L, new Timestamp(7L)))// 进行订单表 event-time 的提取val orders = env.fromCollection(ordersData).assignTimestampsAndWatermarks(new OrderTimestampExtractor[Long, String]()).toTable(tEnv, 'amount, 'currency, 'rowtime.rowtime)// 进行汇率表 event-time 的提取val ratesHistory = env.fromCollection(ratesHistoryData).assignTimestampsAndWatermarks(new OrderTimestampExtractor[String, Long]()).toTable(tEnv, 'currency, 'rate, 'rowtime.rowtime)// 注册订单表和汇率表tEnv.registerTable("Orders", orders)tEnv.registerTable("RatesHistory", ratesHistory)val tab = tEnv.scan("RatesHistory");
// 创建TemporalTableFunctionval temporalTableFunction = tab.createTemporalTableFunction('rowtime, 'currency)
//注册TemporalTableFunction
tEnv.registerFunction("Rates",temporalTableFunction)val SQLQuery ="""|SELECT o.currency, o.amount, r.rate,| o.amount * r.rate AS yen_amount|FROM| Orders AS o,| LATERAL TABLE (Rates(o.rowtime)) AS r|WHERE r.currency = o.currency|""".stripMargintEnv.registerTable("TemporalJoinResult", tEnv.SQLQuery(SQLQuery))val result = tEnv.scan("TemporalJoinResult").toAppendStream[Row]// 打印查询结果result.print()env.execute()}}- OrderTimestampExtractor 实现如下
import java.SQL.Timestampimport org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Timeclass OrderTimestampExtractor[T1, T2]extends BoundedOutOfOrdernessTimestampExtractor[(T1, T2, Timestamp)](Time.seconds(10)) {override def extractTimestamp(element: (T1, T2, Timestamp)): Long = {element._3.getTime}
}3)、With CSVConnector 实现代码
在实际的生产开发中,都需要实际的Connector的定义,下面我们以CSV格式的Connector定义来开发Temporal Table JOIN Demo。
1、genEventRatesHistorySource
def genEventRatesHistorySource: CsvTableSource = {val csvRecords = Seq("ts#currency#rate","1#US Dollar#102","1#Euro#114","1#Yen#1","3#Euro#116","5#Euro#119","7#Pounds#108")// 测试数据写入临时文件val tempFilePath =FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_rate", "tmp")// 创建Source connectornew CsvTableSource(tempFilePath,Array("ts","currency","rate"),Array(Types.LONG,Types.STRING,Types.LONG),fieldDelim = "#",rowDelim = CommonUtils.line,ignoreFirstLine = true,ignoreComments = "%")}2、genRatesOrderSource
def genRatesOrderSource: CsvTableSource = {val csvRecords = Seq("ts#currency#amount","2#Euro#10","4#Euro#10")// 测试数据写入临时文件val tempFilePath =FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_order", "tmp")// 创建Source connectornew CsvTableSource(tempFilePath,Array("ts","currency", "amount"),Array(Types.LONG,Types.STRING,Types.LONG),fieldDelim = "#",rowDelim = CommonUtils.line,ignoreFirstLine = true,ignoreComments = "%")}3、主程序
import java.io.Fileimport org.apache.flink.api.common.typeinfo.{TypeInformation, Types}
import org.apache.flink.book.utils.{CommonUtils, FileUtils}
import org.apache.flink.table.sinks.{CsvTableSink, TableSink}
import org.apache.flink.table.sources.CsvTableSource
import org.apache.flink.types.Rowobject CsvTableSourceUtils {def genWordCountSource: CsvTableSource = {val csvRecords = Seq("words","Hello Flink","Hi, Apache Flink","Apache FlinkBook")// 测试数据写入临时文件val tempFilePath =FileUtils.writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")// 创建Source connectornew CsvTableSource(tempFilePath,Array("words"),Array(Types.STRING),fieldDelim = "#",rowDelim = "$",ignoreFirstLine = true,ignoreComments = "%")}def genRatesHistorySource: CsvTableSource = {val csvRecords = Seq("rowtime ,currency ,rate","09:00:00 ,US Dollar , 102","09:00:00 ,Euro , 114","09:00:00 ,Yen , 1","10:45:00 ,Euro , 116","11:15:00 ,Euro , 119","11:49:00 ,Pounds , 108")// 测试数据写入临时文件val tempFilePath =FileUtils.writeToTempFile(csvRecords.mkString("$"), "csv_source_", "tmp")// 创建Source connectornew CsvTableSource(tempFilePath,Array("rowtime","currency","rate"),Array(Types.STRING,Types.STRING,Types.STRING),fieldDelim = ",",rowDelim = "$",ignoreFirstLine = true,ignoreComments = "%")}def genEventRatesHistorySource: CsvTableSource = {val csvRecords = Seq("ts#currency#rate","1#US Dollar#102","1#Euro#114","1#Yen#1","3#Euro#116","5#Euro#119","7#Pounds#108")// 测试数据写入临时文件val tempFilePath =FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_rate", "tmp")// 创建Source connectornew CsvTableSource(tempFilePath,Array("ts","currency","rate"),Array(Types.LONG,Types.STRING,Types.LONG),fieldDelim = "#",rowDelim = CommonUtils.line,ignoreFirstLine = true,ignoreComments = "%")}def genRatesOrderSource: CsvTableSource = {val csvRecords = Seq("ts#currency#amount","2#Euro#10","4#Euro#10")// 测试数据写入临时文件val tempFilePath =FileUtils.writeToTempFile(csvRecords.mkString(CommonUtils.line), "csv_source_order", "tmp")// 创建Source connectornew CsvTableSource(tempFilePath,Array("ts","currency", "amount"),Array(Types.LONG,Types.STRING,Types.LONG),fieldDelim = "#",rowDelim = CommonUtils.line,ignoreFirstLine = true,ignoreComments = "%")}/*** Example:* genCsvSink(* Array[String]("word", "count"),* Array[TypeInformation[_] ](Types.STRING, Types.LONG))*/def genCsvSink(fieldNames: Array[String], fieldTypes: Array[TypeInformation[_]]): TableSink[Row] = {val tempFile = File.createTempFile("csv_sink_", "tem")if (tempFile.exists()) {tempFile.delete()}new CsvTableSink(tempFile.getAbsolutePath).configure(fieldNames, fieldTypes)}}4、运行结果
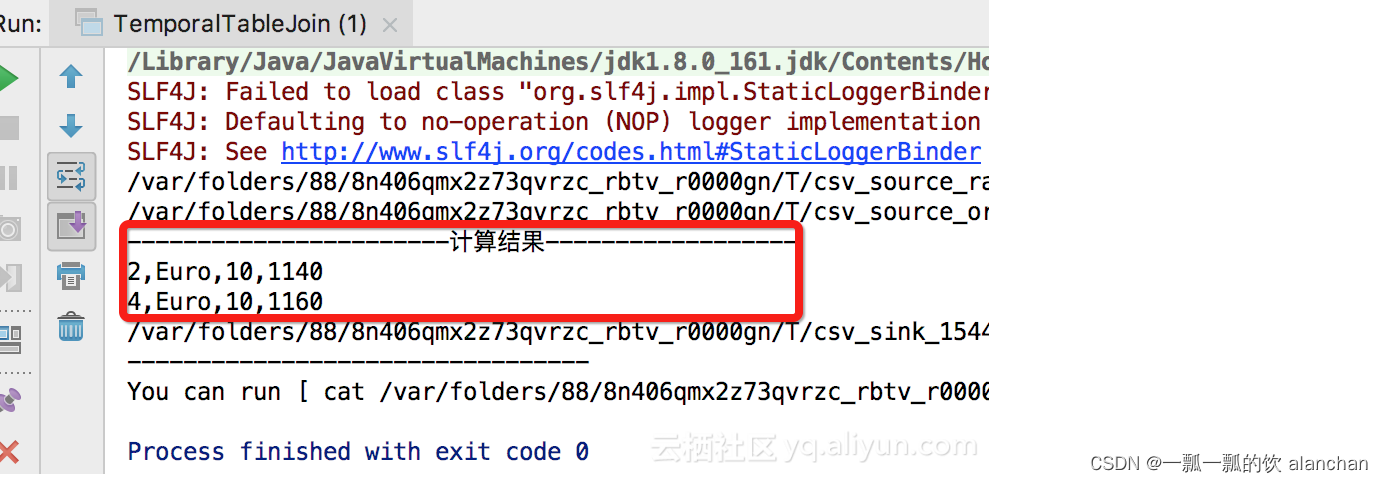
以上,本文给以scala的语言给出来Table API 针对时态表的join操作。
如果需要了解更多内容,可以在本人Flink 专栏中了解更新系统的内容。
本文更详细的内容可参考文章:
17、Flink 之Table API: Table API 支持的操作(1)
17、Flink 之Table API: Table API 支持的操作(2)
本专题分为以下几篇文章:
【flink番外篇】9、Flink Table API 支持的操作示例(1)-通过Table API和SQL创建表
【flink番外篇】9、Flink Table API 支持的操作示例(2)- 通过Table API 和 SQL 创建视图
【flink番外篇】9、Flink Table API 支持的操作示例(3)- 通过API查询表和使用窗口函数的查询
【flink番外篇】9、Flink Table API 支持的操作示例(4)- Table API 对表的查询、过滤操作
【flink番外篇】9、Flink Table API 支持的操作示例(5)- 表的列操作
【flink番外篇】9、Flink Table API 支持的操作示例(6)- 表的聚合(group by、Distinct、GroupBy/Over Window Aggregation)操作
【flink番外篇】9、Flink Table API 支持的操作示例(7)- 表的join操作(内联接、外联接以及联接自定义函数等)
【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)
【flink番外篇】9、Flink Table API 支持的操作示例(9)- 表的union、unionall、intersect、intersectall、minus、minusall和in的操作
【flink番外篇】9、Flink Table API 支持的操作示例(10)- 表的OrderBy、Offset 和 Fetch、insert操作
【flink番外篇】9、Flink Table API 支持的操作示例(11)- Group Windows(tumbling、sliding和session)操作
【flink番外篇】9、Flink Table API 支持的操作示例(12)- Over Windows(有界和无界的over window)操作
【flink番外篇】9、Flink Table API 支持的操作示例(13)- Row-based(map、flatmap、aggregate、group window aggregate等)操作
【flink番外篇】9、Flink Table API 支持的操作示例(14)- 时态表的join(java版本)
【flink番外篇】9、Flink Table API 支持的操作示例(1)-完整版
【flink番外篇】9、Flink Table API 支持的操作示例(2)-完整版
这篇关于【flink番外篇】9、Flink Table API 支持的操作示例(8)- 时态表的join(scala版本)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



