本文主要是介绍linux 进程 内存 函数,UNIX高级环境编程(15)进程和内存分配 故宫角楼,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
故宫角楼是很多摄影爱好者常去的地方,夕阳余辉下的故宫角楼平静而安详。

?
首先,了解一下进程的基本概念,进程在内存中布局和内容。
此外,还需要知道运行时是如何为动态数据结构(如链表和二叉树)分配额外内存的。
一 进程
1 进程和程序
进程:是一个可执行程序的实例。
程序:包含一系列信息的文件,这些信息描述了如何在运行时创建一个进程。包含如下信息:
二进制格式标识:如最常见的ELF格式。
机器语言指令:对程序算法进行编码。
程序入口地址:标识程序开始执行时的起始指令位置。
数据:程序文件包含的变量初始值和程序使用的字面常量值,如字符串。
符号表和重定位表:描述程序中函数和变量的位置及名称。
共享库和动态链接信息:程序文件中所包含的一些字段,列出了程序运行时需要使用的共享库,以及加载共享库的动态链接器的路径名。
其他信息。
进程的再定义:进程是由内核定义的抽象的实体,并为该实体分配用以执行程序的各项系统资源。
从内核的角度看,进程由用户内存空间和一系列内核数据结构组成,其中用户内存空间包含了程序代码及代码所使用的变量,而内核数据结构则用于维护进程状态信息。
2 典型的进程内存布局
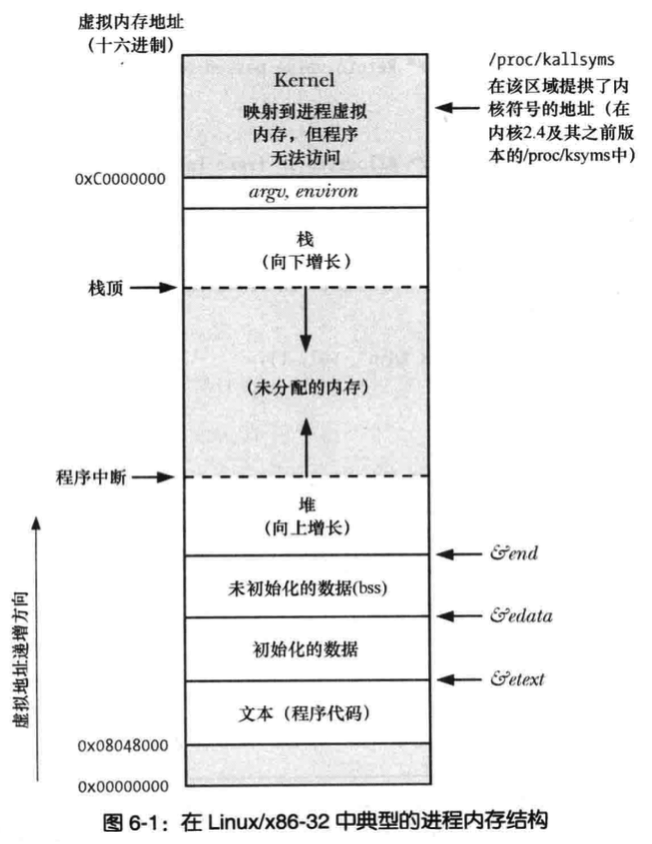
每个进程所分配的内存由很多部分组成,通常称之为“段(segment)”。如上图所示:
文本段:包含进程运行的程序机器语言指令。文本段具有只读属性,因此多个进程可同时运行同一程序,共享文本段。
初始化数据段:包含显式初始化的全局变量和静态变量。当程序加载到内存时,从可执行文件中读取这些变量的值。
未初始化数据段(BSS段,block started by symbol):包含了未进行显式初始化的全局变量和静态变量。程序启动之前,系统将本段内所有内存初始化为0.所以又叫做零初始化数据段。
栈(stack):动态增长和收缩的段,由栈帧(stack frame)组成。系统会为每个当前调用的函数分配一个栈帧。栈帧中存储了函数的局部变量、实参和返回值。
堆(heap):在运行时为变量动态进行内存分配的一块区域。堆顶端成为程序中断(program break)
将经过初始化的全局变量和静态变量与未经过初始化的全局变量和静态变量分开存放,其主要原因在于程序在磁盘上存储时,没有必要为未经过初始化的变量分配存储空间。相反,可执行文件只需记录未初始化数据段的位置及所需要大小,直到运行时再由程序加载器来分配这一空间。
需要注意一点时,该内存布局的讨论是在虚拟内存中的,并不是物理内存中的布局。
在后面会专门讨论虚拟内存的一些细节。
?
二 内存分配
1 在堆上分配内存
堆:一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾,随着内存的分配和释放而增减。将堆的当前内存顶部边界称为“程序中断(program break)”
program break是一个非常重要的概念,因为分配和释放内存的实际动作就是改变进程的program break位置。
program break的起始位置(堆的大小为0)位于未初始化数据段末尾之后。
细节:在分配新的内存后,program break位置升高,程序可以访问新分配区域内的任何内存地址,而此时物理内存页尚未分配。内存会在进程首次试图访问这些虚拟内存地址时自动分配新的物理内存页。
函数malloc和free
malloc函数声明
#include
void *malloc(size_t size);
作用:在堆上分配参数size字节大小的内存。
返回值:成功返回指向新分配内存起始地址的指针,失败返回NULL
free函数声明?
#include
void free(void *ptr);
?作用:释放ptr参数所指向的内存块,该参数应该是之前由malloc或者其他内存分配函数之一所返回的地址。
需要注意的是:一般情况下,free并不降低program break的位置,而是将这块内存增加到空闲内存列表中,供后续的malloc函数循环使用。因为:
被释放的内存块通常位于堆的中间,而非堆的顶部,因而降低program break是不可能的。
它最大限度地减少了内核调用调整program break系统调用的次数。
通常程序会持有分配的内存或者反复释放和重新分配,而不是释放所有内存再运行一段时间。
仅当堆顶空闲内存“足够”大的时候,free函数的glibc实现会调用sbrk()来降低program break的地址,至于“足够”与否则取决于malloc函数包行为的控制参数(128KB为典型值)。这减少了必须对sbrk()发起的调用次数。
malloc和free的实现
malloc()的实现
扫描之前由free()所释放的空闲内存块列表,以求找到尺寸大于或者等于要求的一块内存
如果这一内存块的尺寸正好与要求相当,就把它直接返回给调用者。
如果是一块较大的内存,那么将对其进行分割,在将一块大小相当的内存返回给调用者的同时,把较小的那块空闲内存块保留在空闲列表。
如果在空闲内存列表中找不到足够大的空闲内存块,那么malloc会调用sbrk()以分配更多的内存,并且malloc会分配出比所需字节数更多的内存,将超出的部分置于空闲内存列表中。
free()的实现
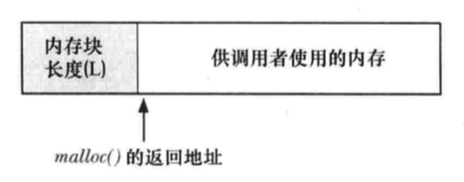
首先先了解两点:malloc返回的内存块和空闲列表中的内存块的结构
为了知道每一个内存块的大小,当malloc分配内存块时,会额外分配几个字节来存放记录这块内存大小的整数值。该整数位于内存块的起始处,而实际返回给调用者的内存地址恰好位于这一长度记录字节之后。如下图所示:
为了管理空闲内存列表,free()会使用内存块本身的空间来存放链表指针,将自身添加到列表中。如下图所示:

所以,在频繁地分配和释放内存之后,堆中的链表可能会变成下图的样子,空闲链表中的空闲内存会和已分配的在用内存混杂在一起。
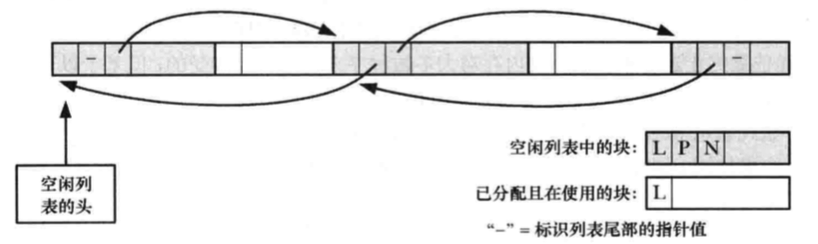
?
三 编程需要注意的事项
通过对内存相关知识更多的了解,在平时编程的时候,应更清楚为什么我们需要遵守下面的规则。
分配一块内存后,不要改变这块内存范围外的任何内容。
释放同一块已分配内存超过一次是错误的。当两次释放同一块内存时,常见的后果是导致不可预知的行为。
若非经由malloc函数包中函数所返回的指针,绝不能在调用free()函数使用。
如果需要反复分配内存,那么应当确保释放所有已使用完毕的内存,不然将导致内存泄露。
?
虽然在我们平时的工作当中,可能涉及不到这么底层的原理,但是通过对这些基本原理的了解,可以让我们更加清除,我们写代码究竟在写些什么 :)
?
参考资料:
《Linux/Unix系统编程手册(上册)》 第6章,第7章?
这篇关于linux 进程 内存 函数,UNIX高级环境编程(15)进程和内存分配 故宫角楼的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




