本文主要是介绍【转】URN_URI_URL详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
URI,Uniform Resource Identifier,统一资源标识符。
URN,Uniform Resource Name,统一资源命名
URL,Uniform Resource Location,统一资源定位符。
URI 简单来理解就是标识/定义了一个资源,而 URL 在定义/标识资源的同时还需要描述如何访问到该资源。可以认为 URL 是 URI 的一个子集。
举个例子:
公司里每个人都有一个内部唯一的花名,这个花名其实就可以认为是 URI,它对应了公司内部唯一的一个人(资源)。当我需要找这个人时,虽然我知道了花名(URI),但是并找不到他人,因为我不知道他的工位,这时候就需要知道他的工位号如 13B-11 ,工位号+花名其实就是一个 URL,它指定了一个人以及怎么找到这个人的位置。
上述例子可能并不规范,但是感觉这样比较容易理解区分。一般来说 URI 有一个通用的结构描述:scheme:[//[user:password@]host[:port]][/]path[?query][#fragment]
Example:
根据第三部分,三者关系如下:
URI: foo://example.com:804/over/there?name=ferret#nose
URN:example.com:804/over/there?name=ferret#nose 去掉scheme
URL: foo://example.com:804/over/there?name=ferret 去掉fragment
其实现在我们不必刻意去区分 URI / URL / URN 。在 [RFC3986]上已经明确说明这个点:
Future specifications and related documentation should
use the general term "URI" rather than the more restrictive terms
"URL" and "URN".
fragment
主要资源是由 URI 进行标识,URI 中的 fragment 用来标识次级资源。我理解看来,fragment 主要是用来标识 URI 所标识资源里的某个资源。
在 URI 的末尾通过 hash mark(#)作为 fragment 的开头,其中 # 不属于 fragment 的值。https://domain/index#L18
这个 URI 中 L18 就是 fragment 的值。这有哪些特殊的地方呢?
#有别于?,?后面的查询字符串会被网络请求带上服务器,而 fragment 不会被发送的服务器;- fragment 的改变不会触发浏览器刷新页面,但是会生成浏览历史;
- fragment 会被浏览器根据文件媒体类型(MIME type)进行对应的处理;
- Google 的搜索引擎会忽略
#及其后面的字符串。
针对以上几点特性,分别介绍下 URI fragment 的应用。
特性 1 & 2 单页面路由
针对 1、2 这两个特性,目前主要的应用就是单页面路由。具体原理简单描述如下:
JavaScript 提供了 location.hash 来操作当前 URI 的 fragment,同时提供了 Hashchange 事件监听 fragment 的变化。利用这两个 API 再结合上述特性 1、2 就可以实现一个简单前端路由。具体流程如下图:

Example
修改 location.hash 值,触发 hashchange 事件,JS 处理对应的逻辑,改变页面 UI 实现页面的跳转,并在浏览器中产生历史记录。
具体代码实现可以参考 vue-router hash 模式下的实现 [https://github.com/vuejs/vue-router/blob/dev/src/history/hash.js]。hashchange event 目前的兼容性表现较好,主流浏览器都支持【[caniuse]】。
实现单页面路由还会使用 H5 为 history 新增的两个 API History.pushState() & Histroy. replaceState ()。虽然在 URL 美观度上很令人满意,但是也存在缺点,如兼容性表现、对 Web 容器配置的额外要求 —— 直接使用 pushState 的 URL 访问应用,则会 404,需要 Web 容器对这些 URL 进行处理,重写到对应的 HTML 页面上。
具体代码实现可以参考 vue-router histroy 模式下的实现 [https://github.com/vuejs/vue-router/blob/dev/src/history/html5.js]。
特性 3 HTML 锚点
在 HTML 中比较常见的一个应用 —— 页面内定位。在页面中通过设置标签的 id 属性来定义锚点,从而实现锚点定位。实际上锚点定位的实现正是依赖了 fragment 的特性 3。如这个 URI https://domain/index.html#L18,假设返回的文件类型是 text/html,则浏览器会读取 URI’s fragment,然后在页面中寻找 L18 这个锚点,并将页面滚动到该锚点的位置。
因此我们当点击 <a href="#top">top</a>时,实际上处理过程是 URI 的 hash 发生变化,然后浏览器读取新的 fragment,并寻找 DOM 中是否存在对应的锚点,将该锚点显示到页面中。
在 MIME Type 为 HTML 或 XML 时,如https://domain/index.html#这个 URI 中是空的 fragment,则浏览器默认显示页面的最顶端。
URI 对应的资源类型不同,浏览器对该 URI’s fragment 的处理方式就不一样,具体不同类型的处理方式可以参阅:[https://en.wikipedia.org/wiki/Fragment_identifier#Examples] 。
特性 4
特性4 其实是针对 hash 模式前端路由来说的一个缺点。因为 fragment 会被 Google 搜索引擎忽略掉,因此对于用 hash 模式前端路由的应用的 SEO 来说是很不友好的。不过 Google 给了一个方案,就是在 # 紧跟一个 ! ,这样Google 搜索引擎就会将这个 URI 进行转换,如 https://domain/index.html#!L18转换后就成为了 https://domain/index.html?_escaped_fragment_=L18。这样搜索引擎就会携带上 URI’s fragment 直接去访问这个 URI,开发者可以利用这个 trick 优化网站的 SEO。
小结
- fragment 对于 HTML 文档来说就是页面内的定位标识符,可以实现 HTML 页面内的定位。当然浏览器针对不同类型的资源会有区分的处理 fragment;
- 利用 fragment 实现前端页面无刷新修改 Brower’s URI;
- 根据搜索引擎规则,可以优化无刷新修改页面的 SEO;
对于 URI’s fragment 的探究也就到这里,附上下关的参考 Links: - [http://www.ietf.org/rfc/rfc3986.txt]
- [https://en.wikipedia.org/wiki/Fragment_identifier]
- [http://www.ruanyifeng.com/blog/2011/03/url_hash.html]
作者:KentonYu
链接:https://www.jianshu.com/p/2c07fbb52b45
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
URI 官方解释是:统一资源标识符
URL 官方解释是:统一资源定位符
以前对互联网的地址和资源的理解非常肤浅,导致一直无法理解两者的区别, 即使看懂了过几天就忘记了.随着我在知识的完善,如今已经理解了,于是写下来,分享给大家.理解不到位还请包含.
URI
首先,我们必须理解 互联网**资源(Resources)**这个概念: 在网络上,任何一个具体的信息,都是一个资源,比如说一行文字,一张图片,一段视频,一种服务(增删改查等). 客户端发生的每次请求都是在请求一个或多个资源,
互联网上资源这么多, 那么就必定要区分他们,于是就给每一个资源取了一个名字(标识符),而且这个名字是独一无二的,不同的资源,必定有不同的名字(标识符)
这就好比,我们每个人都有一个唯一的身份证号码,他是独一无二的, 只要你是个人,那就一定有唯一的身份证号码. (未成年,黑户等就别考虑了,杠精就没意思了)
URL
资源的名字虽然取好了,但是我们的目的是要访问这些资源啊,取了名字还不够,我们得想一个办法访问到某个具体的资源, 换句话说,我们需要定位到某个资源,于是定位符就出现了
这就好比, 虽然每个人都有唯一的身份证号码,但是我即使知道某个人(某个资源)的身份证号码(标识符),也无法找到这个人现在在哪里, 也就是无法定位这个人,这个人可能今天在北京,明天又跑到深圳去了,但是不管他去哪里,他的身份证号码(标识)始终都是不会变的.
疑惑解答
说到这里想必大家都明白了,原来URI是给网络资源取唯一的名字, URL是定位到某个具体资源的地址.
但是这样的理解虽然正确,但是还不够!我们接着说.
URI 是URL的爹, URI不管是从出生时间,还是表示的范围,都要早于(大于)URL, 说的更加正式一点就是: URL是URI的子集. 还有其他子集URN,本文主要说URI和URL.
很多人不能理解,为什么URL是URI的子集?
在习惯思维下,我们通常会这样想: 地址确定了,这个资源就确定了,那么URL应该包含更多的信息, 而URI仅仅只是一个名字,怎么会URI的范围反而大呢?
能想出这个问题说明你理解的还不错,我来解释下:
- 实际上,资源的地址是不固定了,比如说我们今天访问淘宝的主页,和明天访问,地址一样,但是访问到的内容(资源)却不同, 但是资源的名字是不变的.
- URI是一种抽象概念, 而URL的基于抽象的一种具体.如果没有资源(资源必定有标识符URI)了,地址的存在也就没有意义了.
- 我们(警察叔叔)可以通过某个人身份证号码(URI),无论在任何时候都能有办法找到这个人的地址,即使这个人的地址经常变化.
- 在程序中,抽象的范围是大于具体的,比如说三角形表示的含义,一定比等边三角形表示的含义多,前者是抽象,后者是具体,还可以有其他的具体实现,比如直角三角形.
RES
最后,推荐大家学习RES(英文: Representational State Transfer,简称 REST)风格的URL , RES的中文叫:表现层状态转换 ,学习了之后,你一定能很好的理解URL和URI,但是学习这个需要一点基础,因为他有点和我们平常的思维不太一样.虽然他本质很简单.
由于不是本文重点,我就找一些资料,供大家阅读,资料写的比较官方:
REST(英文: Representational State Transfer,简称 REST)描述了一个架构样式的网络系统,比如 web 应用程序。它首次出在 2000 年 Roy Fielding 的博士论文中,他是 HTTP 规范的主要编写者之 一。在目前主流的三种 Web 服务交互方案中, REST 相比于 SOAP(Simple Object Access protocol, 简单对象访问协议)以及 XML-RPC 更加简单明了,无论是对 URL 的处理还是对 Payload 的编码, REST 都倾向于用更加简单轻量的方法设计和实现。值得注意的是 REST 并没有一个明确的标准,而更 像是一种设计的风格。它本身并没有什么实用性,其核心价值在于如何设计出符合 REST 风格的网络接 口。
restful 的优点 它结构清晰、符合标准、易于理解、 扩展方便,所以正得到越来越多网站的采用。 restful 的特性: 资源(Resources) : 网络上的一个实体,或者说是网络上的一个具体信息。它可以是一段文 本、一张图片、一首歌曲、一种服务,总之就是一个具体的存在。可以用一个 URI(统一资源定位 符)指向它,每种资源对应一个特定的 URI 。要获取这个资源,访问它的 URI 就可以,因此 URI 即为每一个资源的独一无二的识别符。表现层(Representation) : 把资源具体呈现出来的形 式,叫做它的表现层 (Representation)。比如,文本可以用 txt 格式表现,也可以用 HTML 格 式、 XML 格式、 JSON 格式表现,甚至可以采用二进制格式。状态转化(State Transfer) : 每 发出一个请求,就代表了客户端和服务器的一次交互过程。HTTP 协议,是一个无状态协议,即所 有的状态都保存在服务器端。因此,如果客户端想要操作服务器,必须通过某种手段, 让服务器 端发生“ 状态转化” (State Transfer)。而这种转化是建立在表现层之上的,所以就是 “ 表现层状 态转化” 。具体说,就是 HTTP 协议里面,四个表示操作方式的动词: GET 、 POST 、 PUT、 DELETE。它们分别对应四种基本操作: GET 用来获取资源, POST 用来新建资源, PUT 用来更 新资源, DELETE 用来删除资源 .
URI、URL、URN区别
起源
这三个缩略词是Tim Berners-Lee在一篇名为RFC 3986: Uniform Resource Identifier (URI): Generic Syntax的文档中定义的互联网标准追踪协议。
引文:
统一资源标识符(URI)提供了一个简单、可扩展的资源标识方式。URI规范中的语义和语法来源于万维网全球信息主动引入的概念,万维网从1990年起使用这种标识符数据,并被描述为“万维网中的统一资源描述符”。

Tim Berners-Lee ,万维网的发明者,同时也是万维网联盟(W3C)的负责人。照片由 Paul Clarke 遵循CC BY-SA 4.0 协议提供。
区别
首先我们要弄清楚一件事:URL和URN都是URI的子集。
换言之,URL和URN都是URI,但是URI不一定是URL或者URN。为了更好的理解这个概念,看下面这张图片。

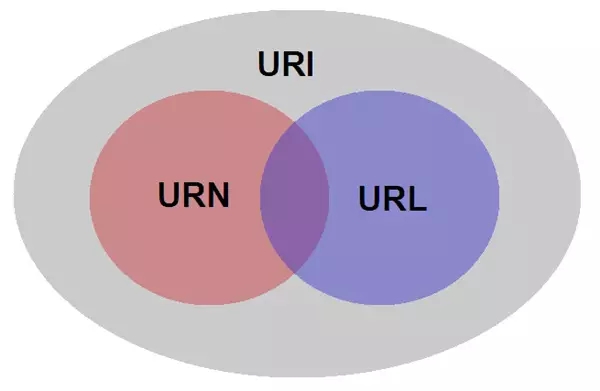
通过下面的例子(源自 Wikipedia),我们可以很好地理解URN 和 URL之间的区别。如果是一个人,我们会想到他的姓名和住址。
URL类似于住址,它告诉你一种寻找目标的方式(在这个例子中,是通过街道地址找到一个人)。要知道,上述定义同时也是一个URI。
相对地,我们可以把一个人的名字看作是URN;因此可以用URN来唯一标识一个实体。由于可能存在同名(姓氏也相同)的情况,所以更准确地说,人名这个例子并不是十分恰当。更为恰当的是书籍的ISBN码和产品在系统内的序列号,尽管没有告诉你用什么方式或者到什么地方去找到目标,但是你有足够的信息来检索到它。引自这篇文章:
所有的URN都遵循如下语法(引号内的短语是必须的):
< URN > ::= "urn:" < NID > ":" < NSS >
其中NID是命名空间标识符,NSS是标识命名空间的特定字符串。
一个用于理解这三者的例子
我们来看一下上述概念如何应用于与我们息息相关的互联网。
再次引用Wikipedia ,这些引文给出的解释,比上面人员地址的例子更为专业:
关于URL:
URL是URI的一种,不仅标识了Web 资源,还指定了操作或者获取方式,同时指出了主要访问机制和网络位置。
关于URN:
URN是URI的一种,用特定命名空间的名字标识资源。使用URN可以在不知道其网络位置及访问方式的情况下讨论资源。
现在,如果到Web上去看一下,你会找出很多例子,这比其他东西更容易让人困惑。我只展示一个例子,非常简单清楚地告诉你在互联网中URI 、URL和URN之间的不同。
我们一起来看下面这个虚构的例子。这是一个URI:
http://bitpoetry.io/posts/hello.html#intro
我们开始分析
http://
是定义如何访问资源的方式。另外
bitpoetry.io/posts/hello.html
是资源存放的位置,那么,在这个例子中,
#intro
是资源。
URL是URI的一个子集,告诉我们访问网络位置的方式。在我们的例子中,URL应该如下所示:
http://bitpoetry.io/posts/hello.html
URN是URI的子集,包括名字(给定的命名空间内),但是不包括访问方式,如下所示:
bitpoetry.io/posts/hello.html#intro
就是这样。现在你应该能够辨别出URL和URN之间的不同。
这篇关于【转】URN_URI_URL详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







