本文主要是介绍基于NASM搭建一个能编译汇编语言的汇编软件工具环境(利用NotePad++),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 一、创建汇编语言源程序
- 二、Notepad++的下载、安装、使用
- 三、下载和安装编译器NASM
- 3.1 下载NASM编译器
- 3.2 安装并配置环境变量
- 四、编译汇编语言源程序(使用命令)
- 五、下载和使用配套源码及工具
- 六、将编译功能集成到Notepad++
一、创建汇编语言源程序
创建txt文件
然后,记事本文件后缀由txt修改为asm
然后用记事本打开编辑
二、Notepad++的下载、安装、使用
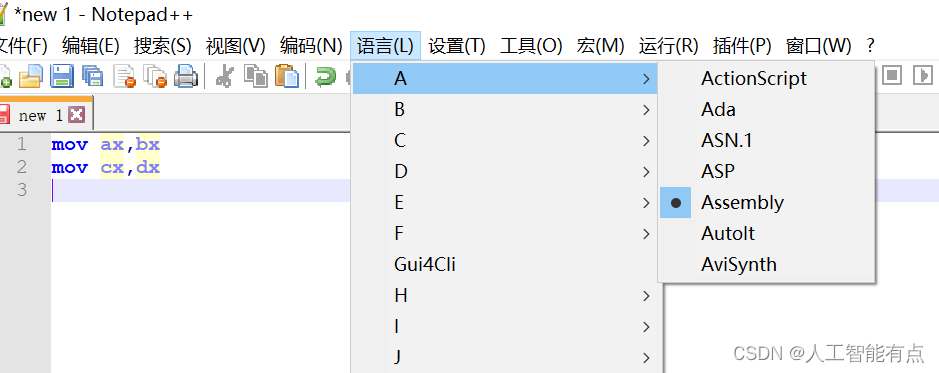
下载直接去官网,安装好之后,可以按照下图选择语言高亮
三、下载和安装编译器NASM
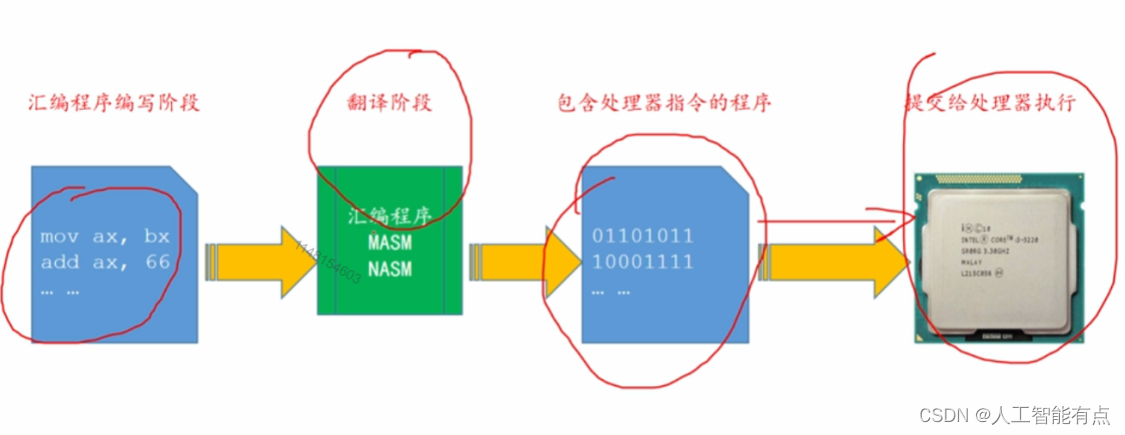
汇编写的程序是一些文本和符号,处理器(机器)看不懂。为此我们需要把汇编程序转换成包含处理器指令的程序。转换过程由汇编语言的编译器进行的。
汇编语言的编译器很多,MASM、NASM
3.1 下载NASM编译器
这里选择NASM编译器,我的电脑系统是Windows10。
下载链接:https://www.nasm.us/pub/nasm/releasebuilds/2.14.02/
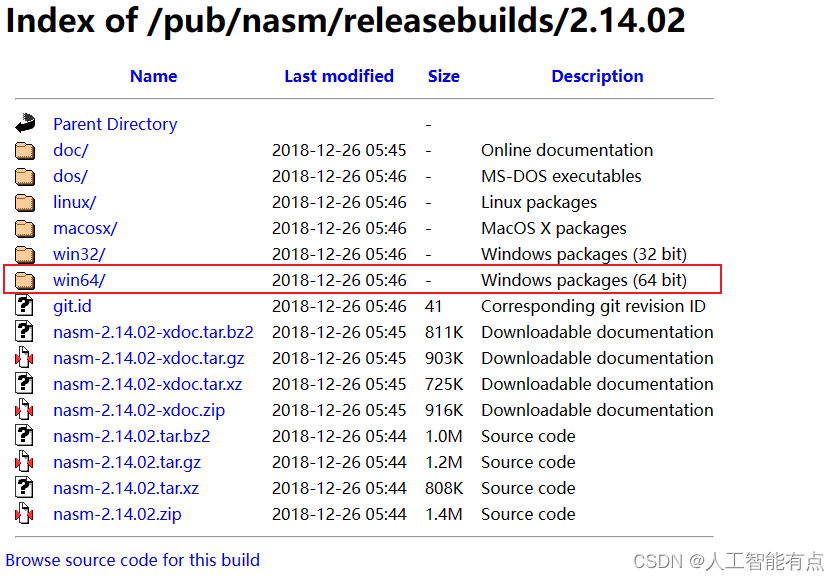
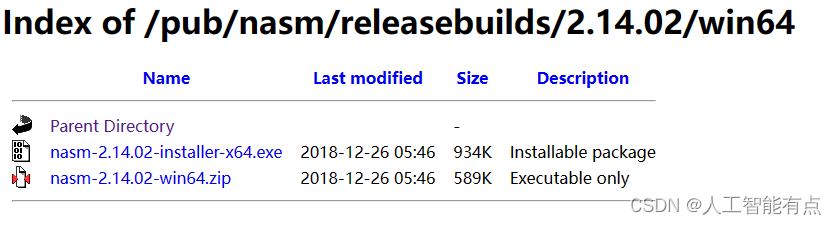
安装程序安装或者压缩包安装。这里下载exe安装程序安装(双击exe文件后的安装过程中有一个本地化的复选框需要勾选上)。
3.2 安装并配置环境变量
双击上面下载好的exe文件安装后,需要配置一下环境变量,目的是可以在每个路径下直接使用NASM编译器进行编译汇编程序。
这里安装在了C盘
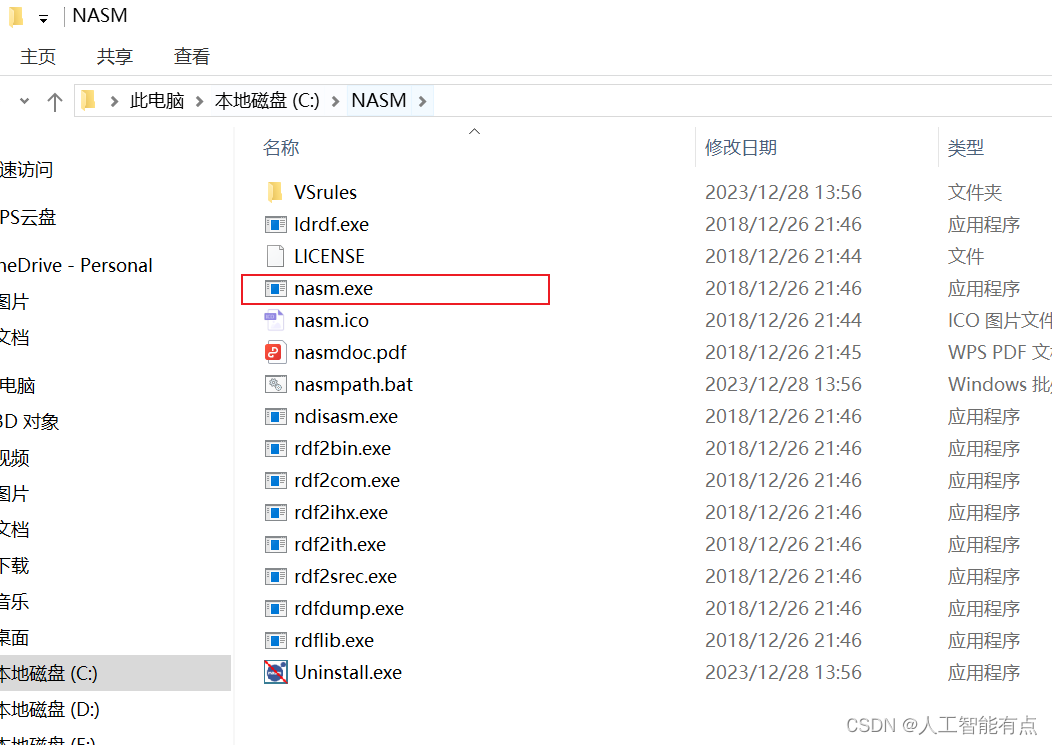
需要程序 nasm.exe 的路径 C:\NASM 添加为环境变量。如何添加环境变量的教程多如牛毛,不加以赘述。
四、编译汇编语言源程序(使用命令)
NASM不具有图形界面,相反,只能在命令行使用。
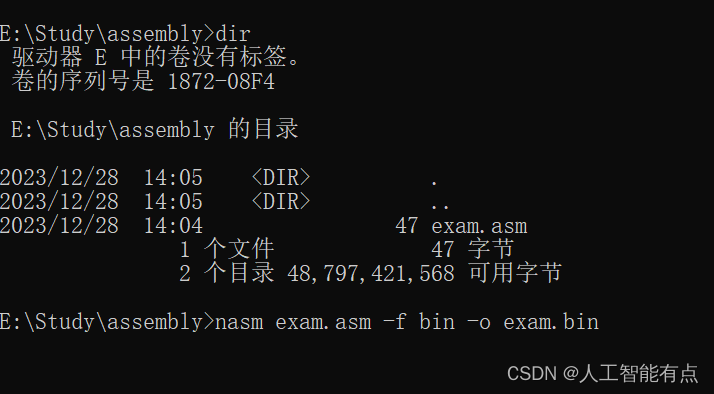
如果这时按下回车键,将执行编译过程,并生成一个包含处理器指令的文件,
- nasm是启动程序
- -f 选项用来指定输出格式
- bin是说明只包含存二进制,即只有处理器识别的机器代码
- -o 选项用来指定输出文件名
- 这里指定exam.bin
命令:nasm exam.asm -f bin -o exam.bin (需配置环境变量才能正常执行)
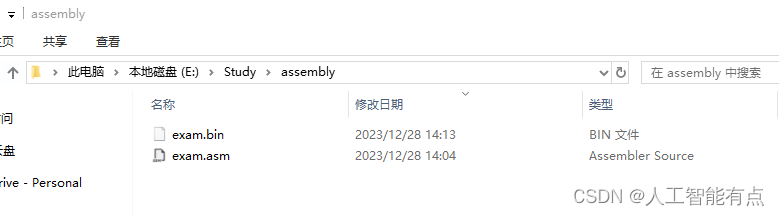
以上是编辑源文件到翻译源文件的过程
五、下载和使用配套源码及工具
16进制查看器(工具包中的):不能显示为字符的就显示为原点。
使用16进制查看器,查看汇编源程序:
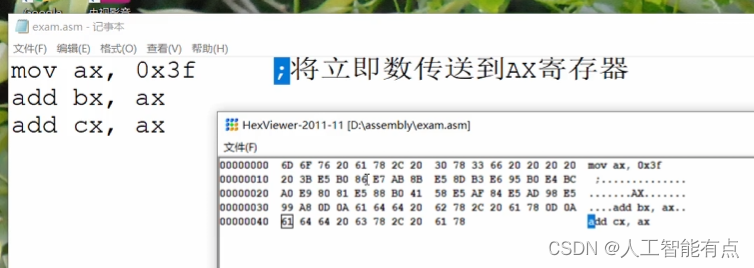
上图中的HexViewer程序中显示的是,exam.asm文件内容的16进制形式。左侧是偏移地址,右侧是符号显示,中间的16进制部分是与右侧符号对应的16进制形式,其中在右侧的原点说明对应的一个字节的16进制不能显示为正常字符。
将汇编源程序文件exam.asm文件进行编译,通过命令 nasm exam.asm -f bin -o exam.bin ,生成了一个二进制指令文件exam.bin。使用16进制查看器HexViewer来查看其内容:
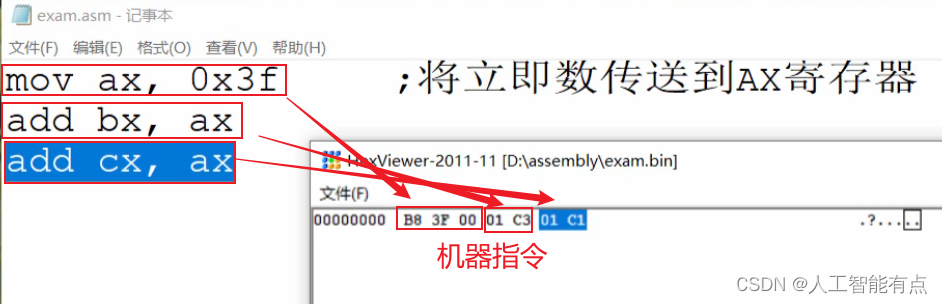
其文件内容都是处理器可以识别和执行的指令。
六、将编译功能集成到Notepad++
在Notepad++的菜单栏中选择“运行(R)”->“运行(R)”
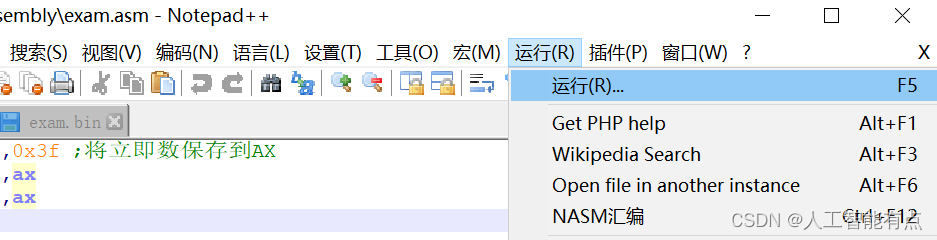
在弹出的窗口输入如下命令,点击保存,然后定义自己的快捷键。记得替换C:\NASM\nasm.exe为自己的编译器路径。
cmd /k pushd "$(CURRENT_DIRECTORY)" & C:\NASM\nasm.exe -f bin "$(FULL_CURRENT_PATH)" -o "$(NAME_PART).bin" & PAUSE & EXIT
至此,编译功能就集成在文本编辑器当中了。
扩展:

这篇关于基于NASM搭建一个能编译汇编语言的汇编软件工具环境(利用NotePad++)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






