本文主要是介绍元旦特辑:Note7---交换排序,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
前言🔔
1. 基本思想🀄️
2. 冒泡排序🟡
2.1 代码实现💛
2.1.1 sort.h
2.1.2 sort.c
2.1.3 test.c
2.2 特性总结🟨
3. 快速排序🔴
3.1 基本思想❤️
4. hoare版本---递归❣️
4.1 思路分析❤️🩹
4.2 代码实现💔
4.2.1 sort.h
4.2.2 sort.c
4.2.3 test.c
5.快排优化❤️🔥
5.1 三数取中🅾️
5.1.1 sort.c
5.1.2 测试结果
5.2 小区间优化🛑
5.2.1 sort.c
6. 挖坑法---递归🆘
6.1 思路分析🅰️
6.2 代码实现🅱️
6.2.1 sort.c
7. 前后指针版本---递归🟥
7.1 思路分析♥️
7.2 代码实现♦️
7.2.1 sort.c
8. 快速排序---非递归🔻
8.1 思路分析⛔️
8.2 代码实现🚫
8.2.1 sort.h
8.2.2 sort.c
8.2.3 test.c
9. 特性总结🔺
10. 性能对比♣️
后语🔕
前言🔔
上篇博客,我们一起学习了选择排序:直接选择排序和堆排序的相关知识点。今天,我们要学习交换排序:冒泡排序和快速排序的实现+特性总结。下面,开始今天的学习吧!
1. 基本思想🀄️
基本思想:所谓交换,就是根据序列中两个记录键值(key)的比较结果来对换这两个记录在序列中的位置
交换排序的特点是:将键值较大的记录向序列的尾部移动,键值较小的记录向序列的前部移动。
2. 冒泡排序🟡
想必冒泡排序大家都很了解了,这里就不再过多详述思路,直接上代码!
当然了,有不懂的或者忘记的小伙伴可以点击下方链接🔗:
别划走!真的不看看全是干货的初级C语言练习题吗?一滴水都没有哦还有解析-CSDN博客文章浏览阅读175次,点赞35次,收藏14次。排序问题,兔子繁殖问题,二分法查找,计算阶乘之和,求2个数的最大公约数
https://blog.csdn.net/2301_79184587/article/details/132089061

2.1 代码实现💛
2.1.1 sort.h
#pragma once
#include<stdio.h>
#include<stdlib.h>//打印
void PrintArray(int* a, int n);
// 冒泡排序
void BubbleSort(int* a, int n);2.1.2 sort.c
#include"sort.h"
//打印
void PrintArray(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");
}// 冒泡排序
void BubbleSort(int* a, int n)
{for (int i = 0; i<n; i++){for (int j = 0; j < n - i-1; j++){if (a[j] > a[j + 1])Swap(&a[j], &a[j + 1]);}}
}2.1.3 test.c
#include"sort.h"
// 冒泡排序
void testBubbleSort()
{int a[] = { 3,2,6,8,9,7,5,10,1,4 };int n = sizeof(a) / sizeof(int);BubbleSort(a, n);PrintArray(a, n);
}int main()
{testBubbleSort();return 0;
}
2.2 特性总结🟨
冒泡排序的特性总结:
1. 冒泡排序是一种非常容易理解的排序
2. 时间复杂度:O(N^2)
3. 空间复杂度:O(1)
4. 稳定性:稳定
3. 快速排序🔴
3.1 基本思想❤️
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程(分为:递归思想和非递归思想),直到所有元素都排列在相应位置上为止。
4. hoare版本---递归❣️
4.1 思路分析❤️🩹
快速排序是基于二叉树实现的--->递归
每次左子树将key的位置排到正确的位置--->再将key视为新的根--->key的左边视为新的左子树--->递归重复--->然后再到右子树--->以此类推最后整体有序

4.2 代码实现💔
4.2.1 sort.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
// 快速排序hoare版本
int QuickSort1(int* a, int begin, int end);4.2.2 sort.c
#include"sort.h"
//打印
void PrintArray(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");
}//交换
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}// 快速排序hoare版本
void QuickSort(int* a, int begin, int end)
{//判断区间//begin==end---只剩余1个数值,不要排序了//begin>end---不存在该区间(空)if (begin >= end)return;int left = begin, right = end;int key = begin;//单趟排序while (left < right){//右边找小//可能在找大小的时候,left和right就会相遇while (left<right&&a[right] >= a[key])right--;//左边找大while (left < right && a[left] <= a[key])left++;Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);//递归思想key = left;//三个区间:[begin,key-1] key [key+1,end]QuickSort(a, begin, key - 1);//左区间QuickSort(a, key + 1, end);//右区间
}4.2.3 test.c
#include"sort.h"
// 快速排序hoare版本
void testQuickSort()
{int a[] = { 3,2,6,8,9,7,5,10,6,1,4 };int n = sizeof(a) / sizeof(int);QuickSort(a,0, n-1);PrintArray(a, n);
}
int main()
{testQuickSort();return 0;
}
5.快排优化❤️🔥
我们习惯于直接将区间最左边的位置设置为key,但是在有序/接近有序(计算机不知道有序啊)的情况下,这样的设置会使时间复杂度达到O(N^2),我们最理想的情况是,每次key都在中间,这样时间复杂度就降低了不少:O(N*logN)
为了验证结论,我们测试一下性能对比(10万个数据):
乱序:

有序:

所以我们需要优化一下:key到底怎么设置最好?
5.1 三数取中🅾️
选取一个不是最大也不是最小的值做key,那么有序的情况下,瞬间就可以变成理想情况
可以避开最坏情况;解决有序的时候在debug下崩溃(栈溢出)的情况
注意是选中位数,不是中间位置的数
5.1.1 sort.c
//三数取中
int GetMid(int* a, int begin, int end)
{int mid = (end + begin) / 2;if (a[begin] < a[mid]){if (a[mid] < a[end])return mid;else if (a[begin] > a[end])return begin;elsereturn end;}else{if (a[mid > a[end]])return mid;else if (a[begin] > a[end])return end;elsereturn begin;}
}// 快速排序hoare版本
void QuickSort(int* a, int begin, int end)
{//判断区间//begin==end---只剩余1个数值,不要排序了//begin>end---不存在该区间(空)if (begin >= end)return;int mid = GetMid(a, begin, end);Swap(&a[mid], &a[begin]);//交换位置---还是让最左边的值做keyint left = begin, right = end;int key = begin;//单趟排序while (left < right){//右边找小//可能在找大小的时候,left和right就会相遇while (left<right&&a[right] >= a[key])right--;//左边找大while (left < right && a[left] <= a[key])left++;Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);//递归思想key = left;//三个区间:[begin,key-1] key [key+1,end]QuickSort(a, begin, key - 1);//左区间QuickSort(a, key + 1, end);//右区间
}5.1.2 测试结果
还是在有序的情况下(10万个数据):

5.2 小区间优化🛑
一般到最后的3-4层递归的时候,我们选择实行小区间优化
1. 为什么要小区间优化?
快排也是递归实现的,例如:最理想的情况(二分法)到最后几个数进行排序时,递归多次,排序代价大。
2. 为什么最后3-4层的时候小区间优化?
因为快排类似于满二叉树的递归,最后几层占的节点数比较多--->递归次数比较多3. 选择什么排序方法来进行优化?
小区间就可以不用快排的递归思想排序了(麻烦),可以用别的排序方法:
1.希尔排序
适合数据多的时候,因为会先进行预排序(将大的尽快放到后面,将小的尽快放到前面)
2.堆排序
需要先建堆然后再选数排序
3.冒泡排序
之后的性能对比测试后发现:比较low
4.直接插入排序
适应性强(有序/乱序都可以适应),比较好
5.2.1 sort.c
// 快速排序hoare版本
void QuickSort(int* a, int begin, int end)
{//判断区间//begin==end---只剩余1个数值,不要排序了//begin>end---不存在该区间(空)if (begin >= end)return;if (end - begin + 1 <= 10)//值不确定,最后几层递归就行//排序并不是每次都是从0开始的万一时右子树排序InsertSort(a+begin, end - begin + 1);else {int mid = GetMid(a, begin, end);Swap(&a[mid], &a[begin]);//交换位置---还是让最左边的值做keyint left = begin, right = end;int key = begin;//单趟排序while (left < right){//右边找小//可能在找大小的时候,left和right就会相遇while (left < right && a[right] >= a[key])right--;//左边找大while (left < right && a[left] <= a[key])left++;Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);//递归思想key = left;//三个区间:[begin,key-1] key [key+1,end]QuickSort(a, begin, key - 1);//左区间QuickSort(a, key + 1, end);//右区间}
}由于现在编译器优化的比较好,所以小区间优化的效果其实在debug和release下都不是很明显(debug的优化效果还是比release的明显一点的),所以平时小区间优化也没有很大的作用(可以不写),我们这里就不使用小区间优化了
6. 挖坑法---递归🆘
修改的地方:修改单趟遍历( hoare版本的坑太多了)
性能优势:无
思路优势:更好理解
6.1 思路分析🅰️
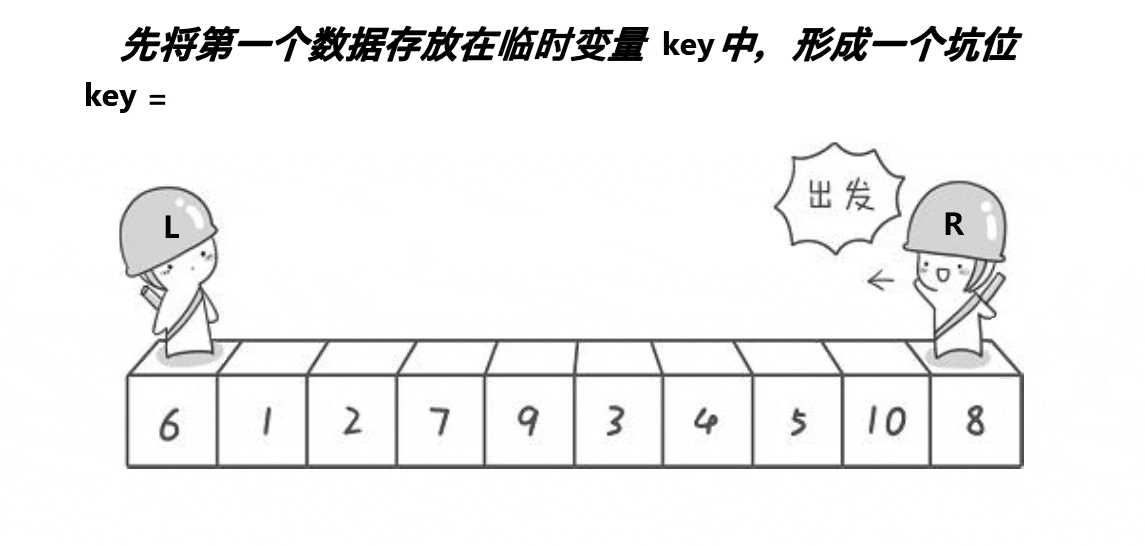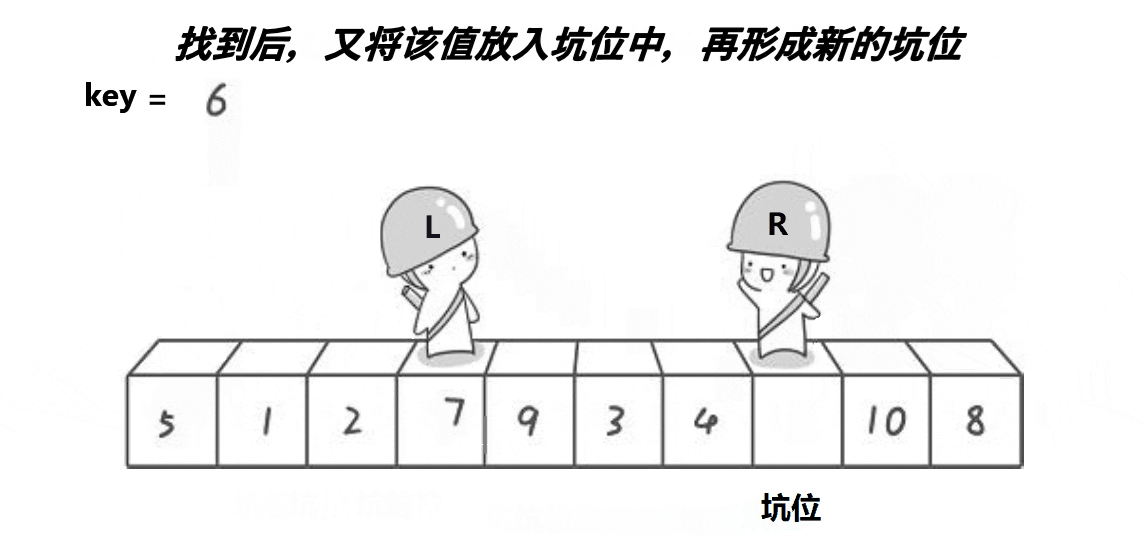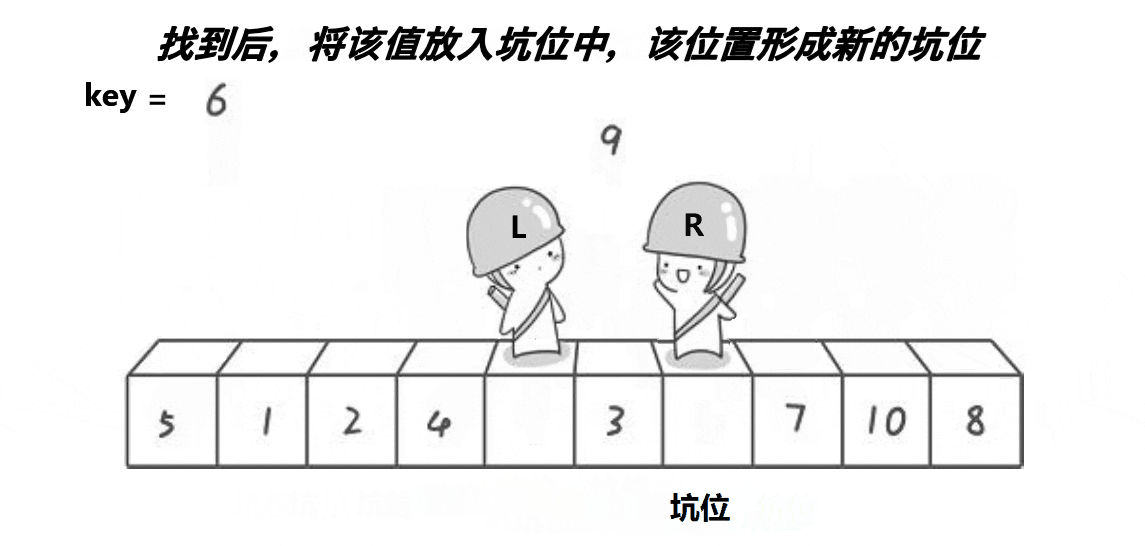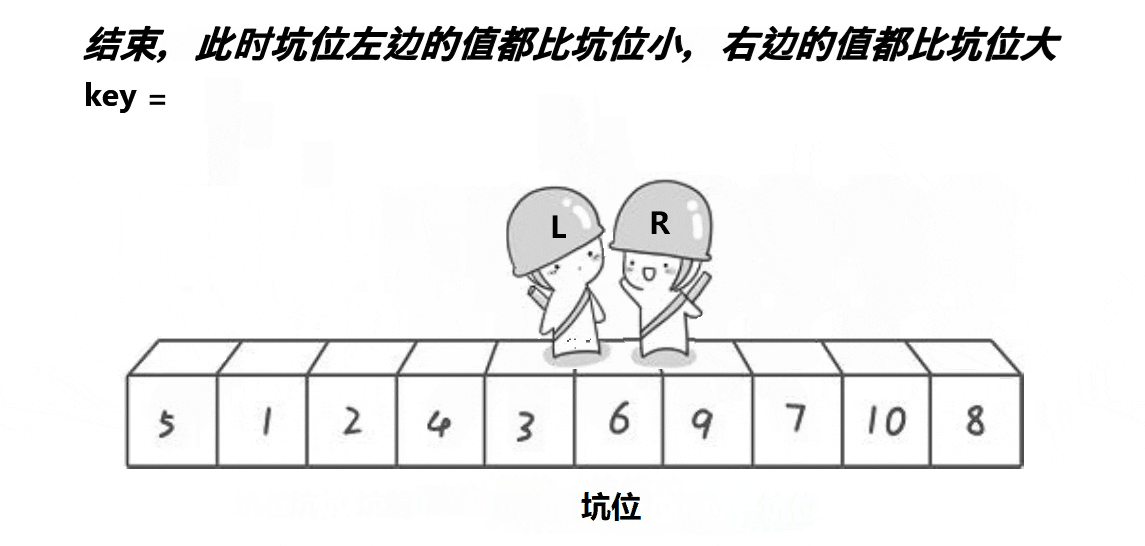
L和R必有一个在坑位上
1.先指定头是key,将值存到临时变量key中,将头的位置先设置是坑位
2.R先找小,找到后将该位置的值放到坑位指向的位置,此位置变成新的坑位
3.然后L找大,找到之后将该位置的值放到坑位指向的位置,此位置变成新的坑位
4.以此类推,直到L和R相遇,那么遍历结束5.最后将key存的值放到相遇位置(也就是新的坑位)
6.2 代码实现🅱️
注意有3种实现单趟排序的方法--->前面的hoare版本的代码需要修改一下--->使3种方法被快排调用方便
6.2.1 sort.c
// 快速排序--hoare版本
int PartSort1(int* a, int begin, int end)
{int mid = GetMid(a, begin, end);Swap(&a[mid], &a[begin]);//交换位置---还是让最左边的值做keyint left = begin, right = end;int key = begin;//单趟排序while (left < right){//右边找小//可能在找大小的时候,left和right就会相遇while(left<right&&a[right] >= a[key])right--;//左边找大while(left < right && a[left] <= a[key])left++;Swap(&a[left], &a[right]);}Swap(&a[left], &a[key]);return left;
}// 快速排序--挖坑法
int PartSort2(int* a, int begin, int end)
{int mid = GetMid(a, begin, end);Swap(&a[mid], &a[begin]);//交换位置---还是让最左边的值做keyint left = begin, right = end;int key = a[begin];int hole = begin;while (left<right){while(left < right && a[right] >= key)right--;a[hole] = a[right];hole = right;while (left < right && a[left] <= key)left++;a[hole] = a[left];hole = left;}a[hole] = key;return hole;
}//快速排序
void QuickSort(int* a, int begin, int end)
{//判断区间//begin==end---只剩余1个数值,不要排序了//begin>end---不存在该区间(空)if (begin >= end)return;//要调用哪种单趟排序就修改一下int key = PartSort2(a, begin, end);QuickSort(a, begin, key - 1);QuickSort(a, key + 1, end);
}7. 前后指针版本---递归🟥
7.1 思路分析♥️
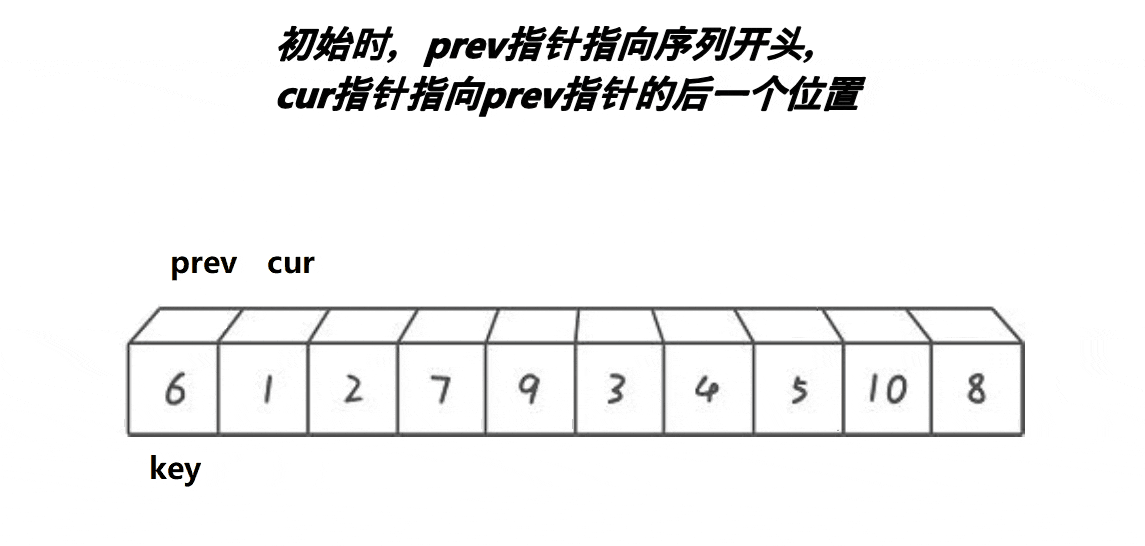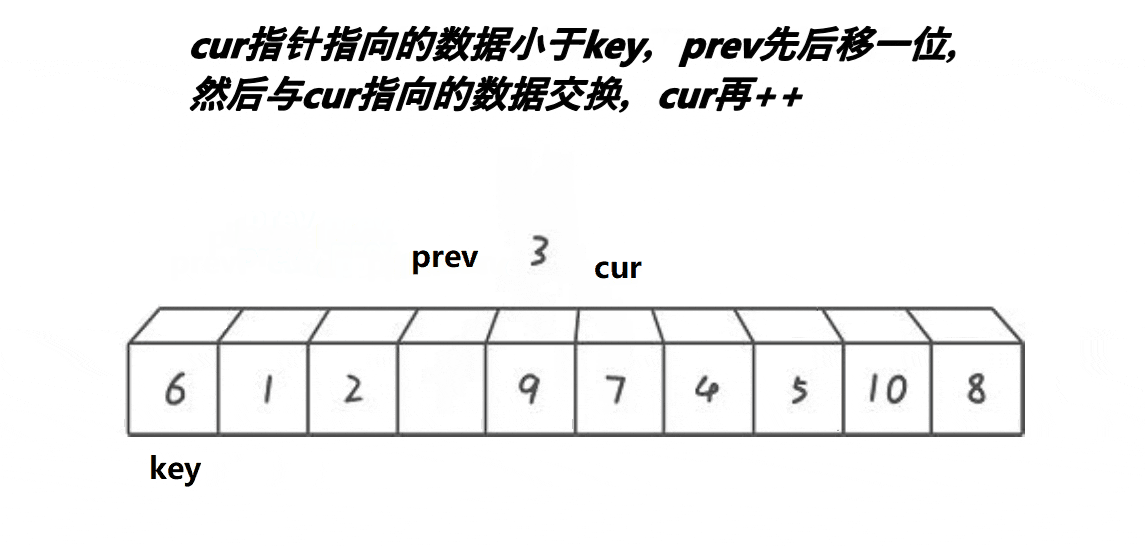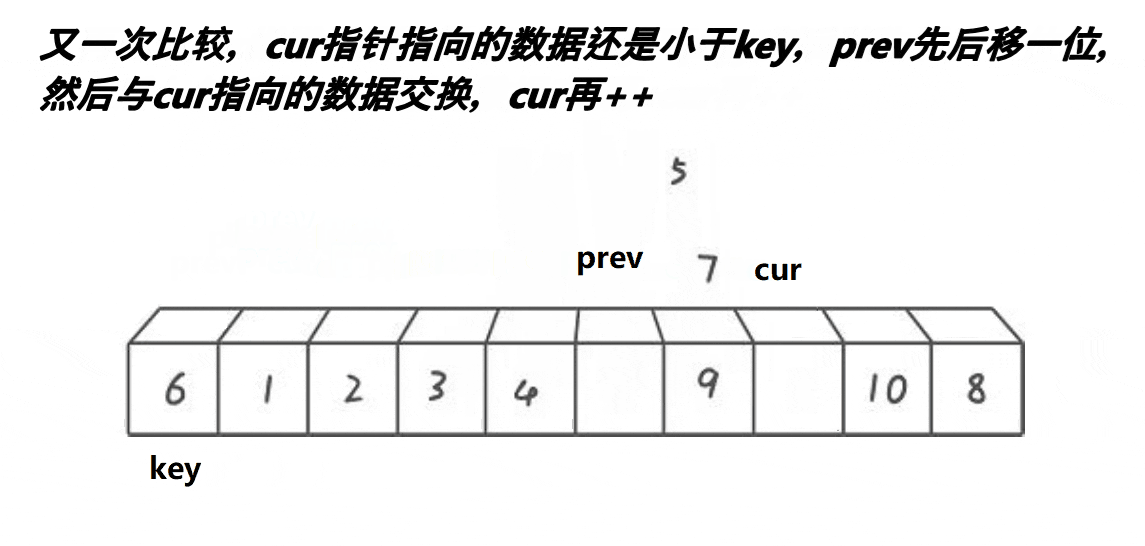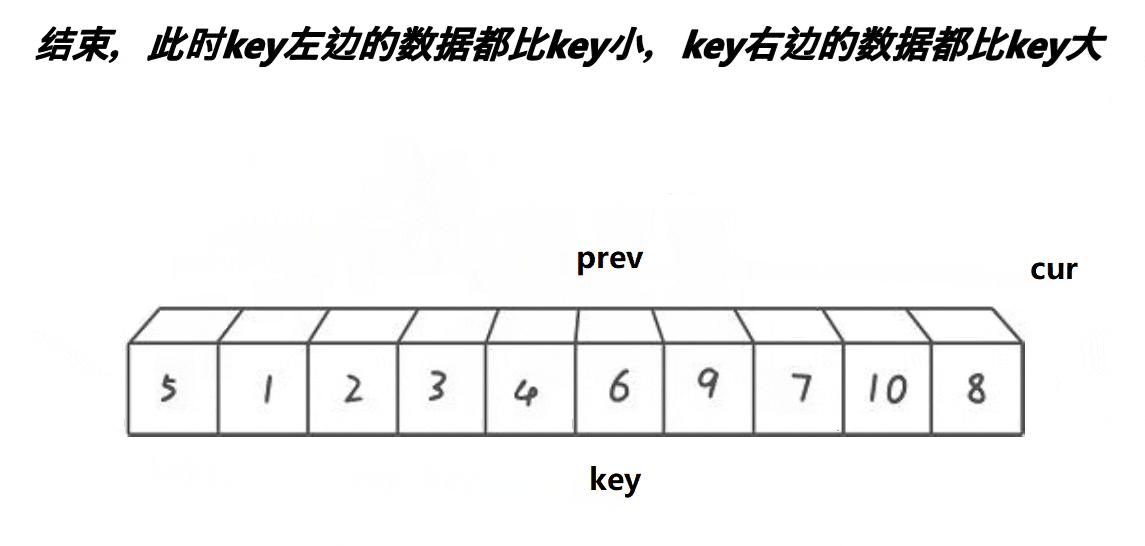
1.将头的值存储到临时变量key中,prev指针指向头,cur指针指向prev的next
2.cur找小
是:prev++,cur指向的内容和prev指向的内容交换,cur++(一开始的时候会出现自己和自己交换的场景但是没有影响)
不是:cur++
3.cur越界时,将prev指向的内容和key交换prev要不然紧跟着cur(把比key小的留在后面),要不然和cur有差距时,相差的都是比key大的值
7.2 代码实现♦️
7.2.1 sort.c
// 快速排序--前后指针法
int PartSort3(int* a, int begin, int end)
{int mid = GetMid(a, begin, end);Swap(&a[mid], &a[begin]);//交换位置---还是让最左边的值做keyint key = begin;int prev = begin, cur = prev + 1;while (cur <= end){if (a[cur] < a[key]&&++prev!=cur)Swap(& a[prev], & a[cur]);cur++;}Swap(&a[prev], &a[key]);key = prev;return prev;
}8. 快速排序---非递归🔻
不似递归胜似递归
掌握非递归的意义:
1.掌握快排(有时候递归太多--->栈溢出--->使用非递归)
2.考察对递归的理解(非递归时建立在递归的理解之上的)
8.1 思路分析⛔️
1. 循环实现
2.借助栈实现(先进后出)--->最后回调的时候,慢慢变成有序的
数据结构的栈(后进先出)(利用的是堆实现的,堆的空间是很大的)
实现的主要思想不变,就是实现左右区间排序的方法从递归--->非递归思路:
最开始是把整段数组存到栈里面,每次从栈里面取出一段区间出来,然后单趟排,然后再将2段区间存到栈里面,循环往复,直到栈为空
对于左右2段区间,以前是递归子问题,现在是把其存到栈里面,依次取出来单趟排序
8.2 代码实现🚫
8.2.1 sort.h
//非递归快排
void QuickSortNonR(int* a, int begin, int end);8.2.2 sort.c
#include"sort.h"
#include"stack.h"
//打印
void PrintArray(int* a, int n)
{for (int i = 0; i < n; i++)printf("%d ", a[i]);printf("\n");
}//交换
void Swap(int* p1, int* p2)
{int tmp = *p1;*p1 = *p2;*p2 = tmp;
}// 快速排序--前后指针法
int PartSort3(int* a, int begin, int end)
{int mid = GetMid(a, begin, end);Swap(&a[mid], &a[begin]);//交换位置---还是让最左边的值做keyint key = begin;int prev = begin, cur = prev + 1;while (cur <= end){if (a[cur] < a[key]&&++prev!=cur)Swap(& a[prev], & a[cur]);cur++;}Swap(&a[prev], &a[key]);key = prev;return prev;
}//非递归快排
void QuickSortNonR(int* a, int begin, int end)
{Stack ST;StackInit(&ST);//存数组开始结束的下标StackPush(&ST, end);StackPush(&ST, begin);while (!StackEmpty(&ST)){int left = StackTop(&ST);StackPop(&ST);int right = StackTop(&ST);StackPop(&ST);int key = PartSort3(a, left, right);//[left,key-1] key [key+1,right]//1个/空:判断一下是否需要入栈(就像递归一样判断是否需要递归)//注意顺序一致,先右后左就都一样的顺序if (left < key - 1){StackPush(&ST, key - 1);StackPush(&ST, left);}if (right > key + 1){StackPush(&ST, right);StackPush(&ST, key + 1);}}StackDestroy(&ST);
}8.2.3 test.c

9. 特性总结🔺
1. 快速排序整体的综合性能和使用场景都是比较好的,所以才敢叫快速排序
2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(logN)
4. 稳定性:不稳定

10. 性能对比♣️
有序:
有序或者接近有序:冒泡和直接插入差别不大
乱序:直接插入优势大Reason:冒泡在任何情况下(不做优化)是严格的等差数列;直接插入只有在逆序情况下是严格的等差数列
乱序:


后语🔕
今天,我们学习了交换排序。重点在于快速排序的3种单趟排序的实现方法和非递归实现快排!希望大家有所收获!之后我们会讲述最后一种排序:归并排序
本次的分享到这里就结束了!!!
PS:小江目前只是个新手小白。欢迎大家在评论区讨论哦!有问题也可以讨论的!期待大家的互动!!!
公主/王子殿下,请给我点赞👍+收藏⭐️+关注➕(这对我真的很重要!!!)
元旦快乐🎉

这篇关于元旦特辑:Note7---交换排序的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







