本文主要是介绍使用Python连接MySQL,实现一个数据库管理系统(批发商零售商管理系统),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用软件PyQt5实现图形界面
使用Python中的pymysql包实现连接数据库操作
本项目较小,适用于零基础Python初学者,不会的百度,很快就能理解本文思路
文末有参考资料,里边大概列举了做出此系统需要的材料
一、需求分析
1.1 背景
软件名称:批发商商品管理系统
用户:零售商、批发商
1.2 任务目标
1.提供零售商查找商品信息和批发商的功能
2.提供批发商对商品的折扣、下架、进货、出货、利润比设置
3.系统符合实际使用要求,人机交货界面友好,操作方便
1.3 运行环境
Python 3.8
Mysql 8.2
1.4 开发工具
Navicat
Pycharm
PyQt5
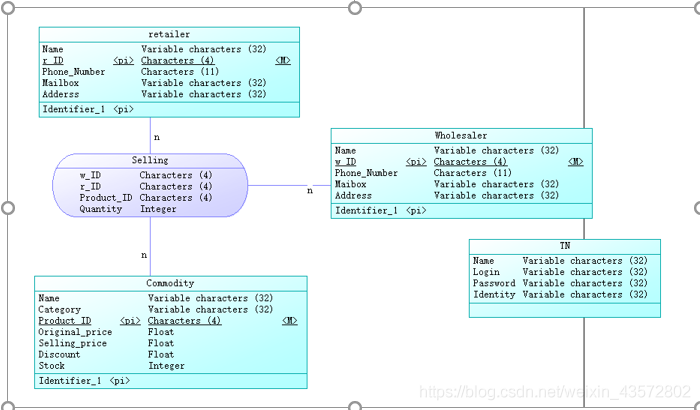
二、 关系模型
Wholesaler (Name, w_ID, Phone_Number, Maibox, Address)
Retailer(Name, r_ID, Phone_Number, Maibox, Address)
Commodity(Name,Category,Product_ID,Original_price,Selling_price,Discount, Stock)
Selling(w_ID, r_ID, Product_ID, Quantity)
TN(Name, Login, Password, Identity)
三、E-R图
实际中并未使用Selling关系
四、项目实现
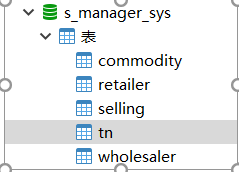
4.1建立数据库
按关系模式写出数据库结构
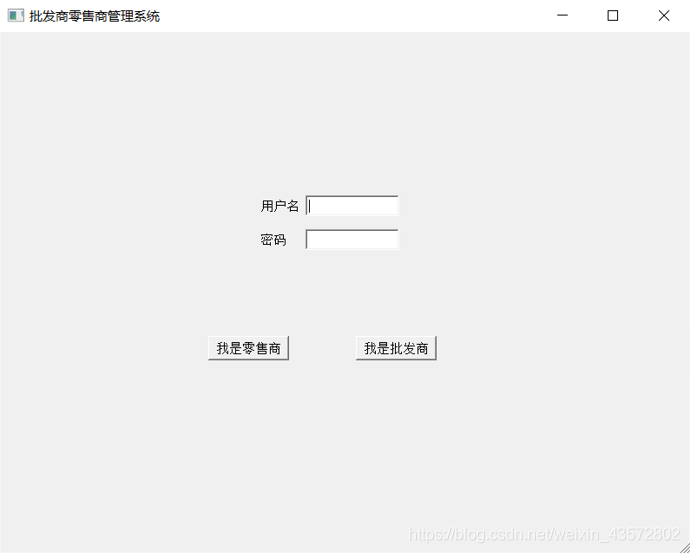
4.2界面设计
4.2.1用户登录页面
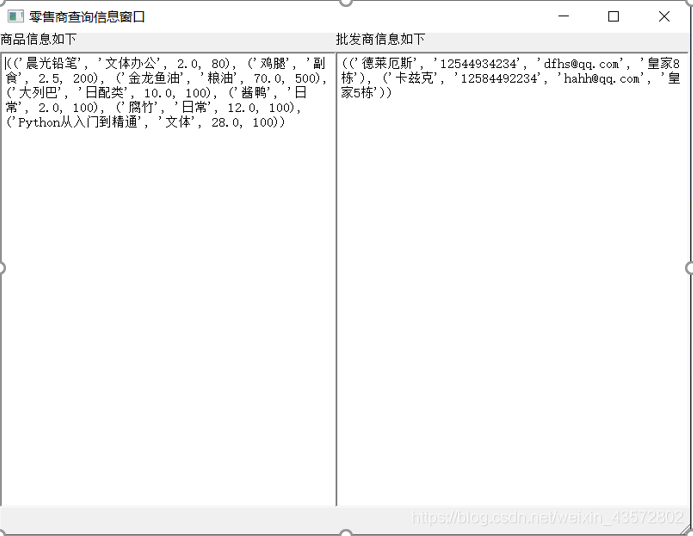
4.2.2零售商查询信息页面
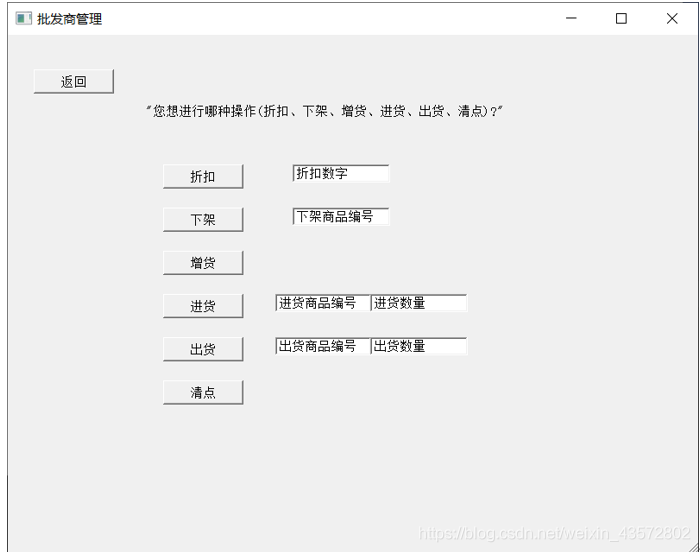
4.2.3批发商管理商品页面如下
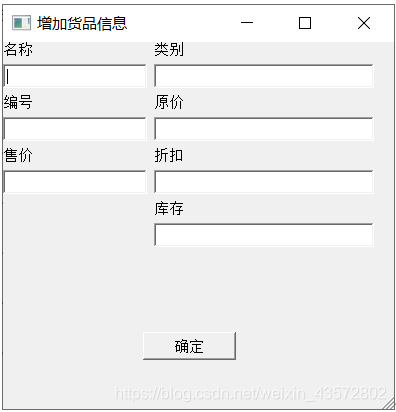
4.2.4增货界面如下
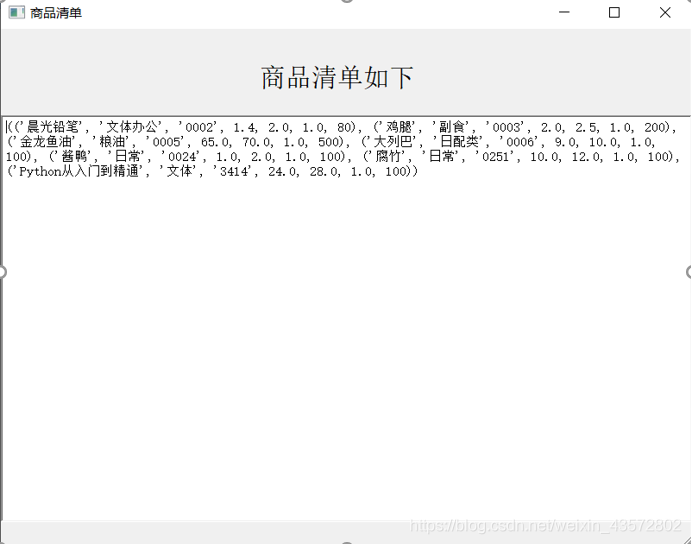
4.2.5清点商品界面如下
4.2.4 设计思路
在本机python3.8导入pymysql包和pyqt5、pyqt5-tools后就可以开始编写了,思路是先不用图形界面,直接在pycharm上设计代码,之后用pyqt5进行界面设计; PyQt5 是用来创建Python GUI应用程序的工具包。作为一个跨平台的工具包,PyQt5可以在所有主流操作系统上运行,使用PyQt5的好处是可以先使用QtDesigner进行可视化设计,然后将生成的.ui文件转换成.py文件;代码编写及其简单。
五、实现功能的相应mysql语句+代码
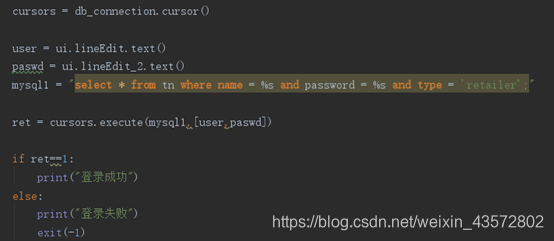
5.1登录
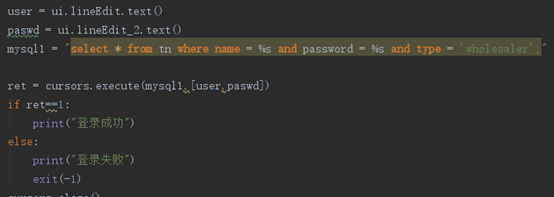
5.2零售商查询信息
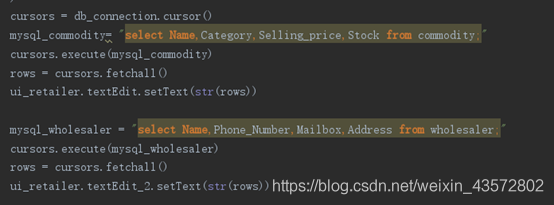
5.3批发商进行折扣

5.4批发商下架商品
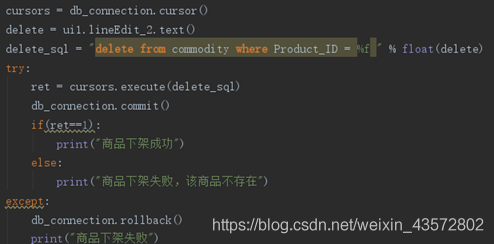
5.5批发商增加商品(增货)
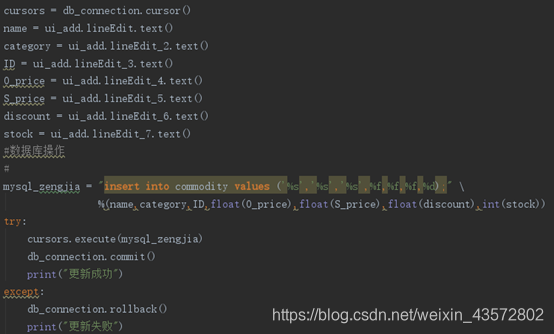
5.6批发商进货
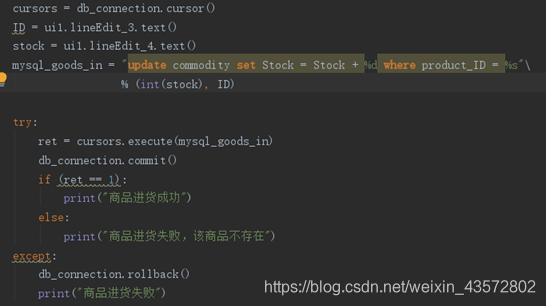
5.6批发商出货
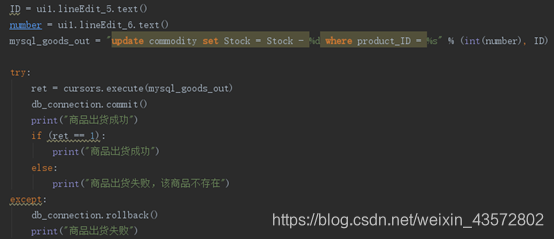
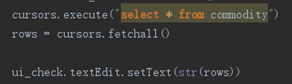
5.6批发商清点
六、代码设计综述
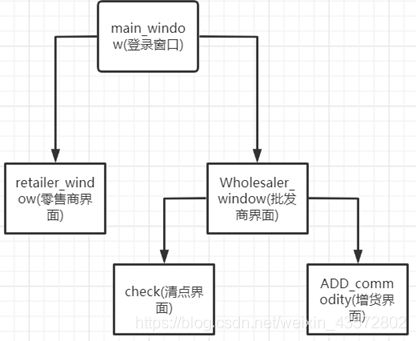
利用PyQt5完成界面的编写,生成py文件,然后通过添加事件监听来做出具体操作,
所有窗口的具体监听事件全部放到主函数中,具体代码可以看附件。
参考材料
Python连接mysql数据库
Windows环境安装PyQt5
PyQt5入门教程
百度
源代码已经更新到本人的GitHub仓库,还不会使用GitHub,等更新了删除线再去掉
这篇关于使用Python连接MySQL,实现一个数据库管理系统(批发商零售商管理系统)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






