本文主要是介绍Springer build pdf乱码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在textstudio中编辑时没有错误,在editor manager生成pdf时报错。

首先不要改源文件,着重看你的上传顺序:
将.tex文件,.bst文件,.cls文件,.bib文件, .bbl文件的类型,在editor manager中是Item。全部改为Manuscript类型。重新编辑即可解决问题。
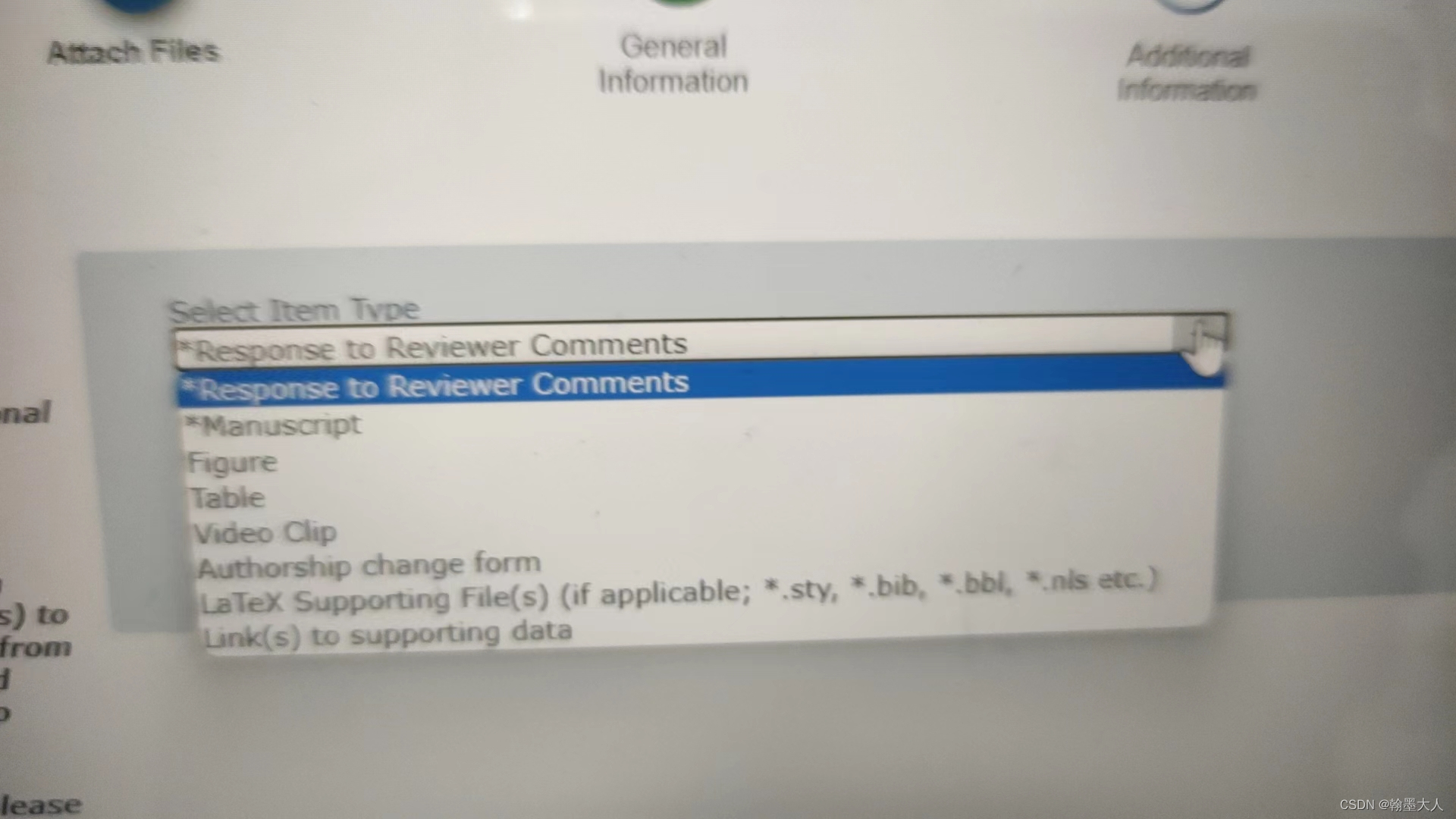
如果你编译成功但是出现:
说明你漏了一些文件,检查一定要包含上述五个文件。
正确的编译结果应该是:

这篇关于Springer build pdf乱码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








