本文主要是介绍Big-endian与Little-endian详尽说明,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大端与小端存储详尽说明
大端与小端存储详尽说明
- 大端与小端存储详尽说明
- 一. 什么是字节序
- 二. 什么是大端存储模式
- 三. 什么是小端存储模式
- 四. 大小端各自的特点
- 五. 为什么会有大小端模式之分
- 六. 为什么要注意大小端问题
- 六. 大小端判定程序
- 七. 大端小端的转换
- 1)16位大小端转换
- 2)32位大小端转换
- 八. 大小端数据的存取
- 1)存储时
- 2)读取时
一. 什么是字节序
字节序,也就是字节的顺序,指的是多字节的数据在内存中的存放顺序。
在几乎所有的机器上,多字节对象都被存储为连续的字节序列。
不同的CPU有不同的字节序类型,最常见的有两种:
Little-Endian:将低序字节存储在起始地址(低位编址),也就是小端存储模式。
Big-Endian:将高序字节存储在起始地址(高位编址),也就是下面说的大端存储模式。
二. 什么是大端存储模式
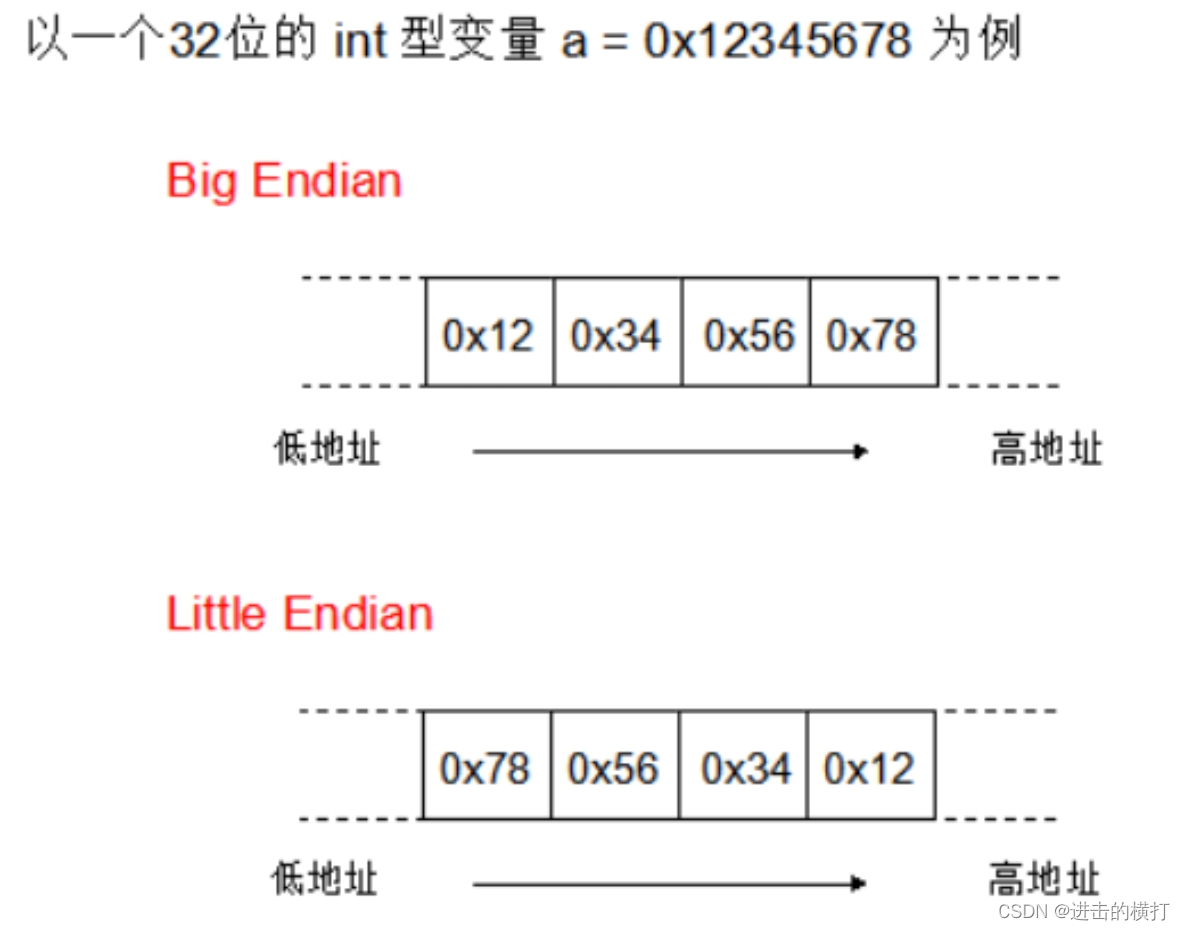
数据的低位保存在内存中的高地址中,数据的高位保存在内存中的低地址中;这样的存储模式有点儿类似于把数据当作字符串顺序处理:地址由小向大增加,而数据从高位往低位放;
高字节数据存储在低地址。
16进制数据:0x12345678
存储方式:(低地址)12|34|56|78(高地址)
数组表示:
buf[3] (0x78) – 低位
buf[2] (0x56)
buf[1] (0x34)
buf[0] (0x12) – 高位
记忆方法: 地址的增长顺序与值的增长顺序相反。
三. 什么是小端存储模式
数据的低位保存在内存中的低地址中,数据的高位保存在内存中的高地址中;这种存储模式将地址的高低和数据位权有效地结合起来,高地址部分权值高,低地址部分权值低,和我们的逻辑方法一致。
16进制数据:0x12345678
存储方式:(低地址)78|56|34|12(高地址)
数组表示:
buf[3] (0x12) – 高位
buf[2] (0x34)
buf[1] (0x56)
buf[0] (0x78) – 低位
记忆方法: 地址的增长顺序与值的增长顺序相同
四. 大小端各自的特点
小端模式 :强制转换数据不需要调整字节内容,1、2、4字节的存储方式一样。
大端模式 :符号位的判定固定为第一个字节,容易判断正负。网络传输一般使用的就是Big Endian,也被称之为网络字节序,或网络序。
五. 为什么会有大小端模式之分
这是因为在计算机系统中,我们是以字节为单位的,每个地址单元都对应着一个字节,一个字节为8bit。但是在C语言中除了8bit的char之外,还有16bit的short型,32bit的long型(要看具体的编译器),另外,对于位数大于8位的处理器,例如16位或者32位的处理器,由于寄存器宽度大于一个字节,那么必然存在着一个如果将多个字节安排的问题。因此就导致了大端存储模式和小端存储模式。
我们常用的x86结构是小端模式,而KEIL C51则为大端模式。很多的ARM,DSP都为小端模式。有些ARM处理器还可以由硬件来选择是大端模式还是小端模式。
因此可以说大端存储或小端存储都是由系统设定的,两者区别在于低地址存储的数据,因此可以写程序进行判断。
六. 为什么要注意大小端问题
C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的 0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。
因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。
六. 大小端判定程序
请写一个C函数,若处理器是Big_endian的,则返回0;如果Little_endian的,则返回1。
int checkLittleEndian()
{{union w{int a;char b;} c;c.a = 1;return (c.b == 1);}
}
联合体union的存放顺序是全部成员都从低地址开始存放,解答利用该特性,轻松地得到了CPU对内存采用Little-endian仍是Big-endian模式读写。
void Endianness()
{int a = 0x12345678;if( *((char*)&a) == 0x78)cout << "Little Endian" << endl;elsecout << "Big Endian" << endl;
}
这一种是通过强制类型转换的方式来判断大小端的。如果是小端的话,低位字节0x78的内容应该是存放在低地址中。
七. 大端小端的转换
1)16位大小端转换
#define BSWAP_16(x) \ (uint_16)((((uint_16)(x) & 0x00ff) << 8) | \ (((uint_16)(x) & 0xff00) >> 8) \ )
或者是函数的形式
uint_16 bswap_16(uint_16 x)
{return (((uint_16)(x) & 0x00ff) << 8) | \(((uint_16)(x) & 0xff00) >> 8) ;
}
2)32位大小端转换
#define BSWAP_32(x) \ (uint_32)((((uint_32)(x) & 0xff000000) >> 24) | \ (((uint_32)(x) & 0x00ff0000) >> 8) | \ (((uint_32)(x) & 0x0000ff00) << 8) | \ (((uint_32)(x) & 0x000000ff) << 24) \ )
或者是函数的形式
uint_32 bswap_32(uint_32 x)
{ return (((uint_32)(x) & 0xff000000) >> 24) | \ (((uint_32)(x) & 0x00ff0000) >> 8) | \ (((uint_32)(x) & 0x0000ff00) << 8) | \ (((uint_32)(x) & 0x000000ff) << 24) ;
}
八. 大小端数据的存取
1)存储时
1)先按照数据类型开辟一个空间。
int a;4字节|——|——|——|——|
2)数据定义。a=0x123456;
3)数据分割成存储单元(字节)。
0x12——0x34——0x56
4)不用考虑谁先放谁后放,我们要按顺序放,先放0x12,再放0x34……
5)大端存储方式,先往低地址放
|0x12|0x34|0x56|——|
小段存储方式,先往高地址放
|——|0x56|0x34|0x12|
2)读取时
读取时:
1)大端依次读出,小端倒叙读出。读取时,字节内部是一个整体不受倒叙影响。
2)读取后,就和之前未存储时顺序一致了,也就是数没发生变化。
char只占有一个字节,因此字符不需要考虑大小端,而字符串又是单个字符的组合,因此也不需要考虑大小端。因此,在网络通信中,通信信息为字符串,不需要考虑大小端问题。
这篇关于Big-endian与Little-endian详尽说明的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






