本文主要是介绍Python教程:socket()模块和套接字对象的内建方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、socket()模块函数
要使用socket.socket()函数来创建套接字,其语法如下:
socket(socket_family,socket_type,protocol=0)
如上所述,scoket_family不是AF_UNIX就是AF_INET,scoket_type可以是SOCK_STREAM或SOCK_DGRAM,protocol一般不填,默认值为0.
创建一个TCP/IP套接字,你要这样调用socket.socket():
tcpsock = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
同样的,创建一个UDP/IP的套接字,你要这样:
udpsock = socket.socket(socket.AF_INET,socket.SOCK_DGRAM)
由于socket有太多属性,我们一般使用from import socket *语句,将所有属性导入命名空间。
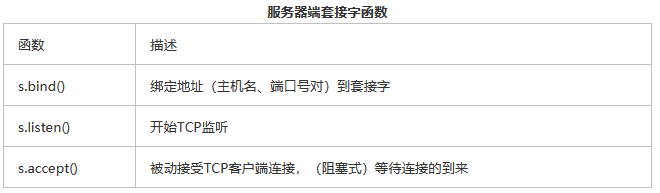
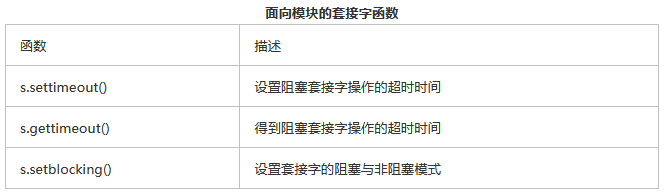
二、套接字对象内建方法
下面是一些套接字对象常用的方法。



提示:在运行网络应用程序时,最好在不同的电脑上执行服务器和客户端的程序。
三、创建TCP服务器和TCP客户端
根据上面的介绍,现在我们应该能创建一个完整的通信模型了。下面是理论上的伪代码:
1.套接字理论模型
先来创建一个TCP服务器
#创建一个TCP服务器ss = socket() #创建服务器套接字ss.bind() #把地址绑定到套接字上ss.listen() #监听连接inf_loop: #服务器无线循环cone,addr = ss.accept() #接收客户端连接comm_loop: #通信循环cone.recv()/cs.send() #对话(接受与发送)cone.close() #关闭客户端套接字
ss.close() #关闭服务器套接字(可选)
所有的套接字都用socket.socket()函数来创建。服务器需要“坐在某个端口上”等待请求。所以它们必须要绑定到一个本地的地址上。
由于TCP是一个面向连接的通信系统,在TCP服务器可以开始工作之前,要先完成一些设置。
TCP服务器必须监听(进来的)连接,设置完成之后,服务器就可以进入无线循环了。
一个简单的(单线程的)服务器会调用accept()函数等待连接的到来,
默认情况下,accept()函数是阻塞式的,即程序在连接到来之前会处于挂起状态。套接字也支持非阻塞模式。
一旦接收到一个连接,accept·()函数就会返回一个单独的客户端套接字用于后续的通信。
使用新的客户端套接字就像把客户的电话转给一个客户服务人员。当一个客户打电话进来的时候,总机接了电话,然后把电话转到合适的人那里来处理客户的需求。
这样就可以空出主机,也就是最初的那个服务器套接字。
当客户端连接关闭后,服务器继续等待下一个客户端的连接。代码的最后一行会把服务器套接字关闭,由于是无限循环也许用不到。
再来创建一个TCP客户端
#创建一个TCP客户端
ss = socket() #创建一个客户端套接字
ss.connect() #尝试连接服务器
comm_loop: #通信循环cs.send()/cs.recv() #对话(接受或发送)
cs.close() #关闭客户端套接字
在客户端有了套接字之后,马上就可以调用connect()函数去连接服务器。连接建立之后,就可以与服务器开始对话了,对话结束后,客户端就可以关闭套接字,结束连接
2.建立一个单一的连接
服务器端
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
from socket import *
cs = socket(AF_INET,SOCK_STREAM)
cs.bind(('127.0.0.1',8888))
cs.listen(5)print("Wait for......")
anne,addr = cs.accept()
print(anne)
print(addr)
anne.close()
客户端
from socket import *
cl = socket(AF_INET,SOCK_STREAM)
cl.connect(("127.0.0.1",8888))
cl.send("Hello,world".encode("utf-8"))
cl.close()
先启动服务器:
Wait for...... #accept处于等待状态
然后执行客户端,看服务器端的变化:
<socket.socket fd=384, family=AddressFamily.AF_INET, type=SocketKind.SOCK_STREAM, proto=0, laddr=('127.0.0.1', 8888), raddr=('127.0.0.1', 54883)>
('127.0.0.1', 54883) #客户端IP地址和端口号
上面的的代码有点单一,有多个客户端同时访问该如何?这就该用到后面的多线程,稍后会讲,这里有另外的折中代码,可以一直访问,虽然一次只能访问一个。
#服务器端
from socket import *
cs = socket(AF_INET,SOCK_STREAM)
cs.bind(("127.0.0.1",8888))
cs.listen(5)
print("Have Listen")while True:cone,addr = cs.accept()while True:data = cone.recv(1024)if len(data) == 0:break #如果收到TCP消息,则关闭客户端套接字print(data.decode("utf-8"))cone.send(data.upper())cone.close()
cs.close()#客户端
from socket import *
cs = socket(AF_INET,SOCK_STREAM)
cs.connect(("127.0.0.1",8888))
while True:ssg = input(">>>").strip()if not ssg:continue #避免空格造成的停顿cs.send(ssg.encode("utf-8")) #发data = cs.recv(1024)print(data.decode("utf-8")) #收
cs .close()
下面是在linux下的版本测试:
#服务端
#!/usr/bin/env python
#coding:utf-8from socket import *
import timeHOST = '192.168.43.131'
PORT = 8808
BUFSIZ = 1024
ADDR = (HOST,PORT)tcpser = socket(AF_INET,SOCK_STREAM)
tcpser.bind(ADDR)
tcpser.listen(5)while True:print "等待连接......"anne,addr = tcpser.accept()print "...连接:",addrwhile True:data = anne.recv(BUFSIZ)if not data:breakanne.send('[%s] %s' % (time.strftime('%c'),data))anne.close()
tcpser.close()#客户端
#!/usr/bin/env pythonfrom socket import *HOST = '192.168.43.131'
PORT = 8088
BUFSIZ = 1024
ADDR = (HOST,PORT)tcpcli = socket(AF_INET,SOCK_STREAM)
tcpcli.connect(ADDR)while True:data = input(">>>")if not data:continuetcpcli.send(data.encode("utf-8"))data = tcpcli.recv(BUFSIZ)if not data:breakprint(data.decode("utf-8"))
tcpcli.close()
四、创建UDP服务器和UDP客户端
由于UDP服务器不是面向连接的,所以不用像TCP服务器那样做那么多设置工作。
创建一个UDP服务器
#创建UDP服务器
ss = socket() #创建一个服务器套接字
ss.bind() #绑定服务器套接字
inf_loop: #服务器无限循环cs = ss.recvfrom()/ss.sendto() #对话(接收与发送)
ss.close() #关闭服务器套接字
从伪代码中可以看出,使用的还是那套先创建套接字然后绑定到本地地址(主机/端口)的方法,无限循环中包含了从客户接受消息。
创建一个TCP服务器
#创建一个UDP服务器
cs = socket() #创建客户端套接字
comm_loop: #通讯循环cs.sendto()/cs.recvfrom() #对话(发送/接收)
cs.close() #关闭客户端套接字
创建一个真实的案例:
'''
遇到问题没人解答?小编创建了一个Python学习交流QQ群:531509025
寻找有志同道合的小伙伴,互帮互助,群里还有不错的视频学习教程和PDF电子书!
'''
#创建一个服务器
from socket import *HOST = "127.0.0.1"
PORT = 8989
BUFSIZ = 1024
ADDR = (HOST,PORT)udpser = socket(AF_INET,SOCK_DGRAM)
udpser.bind(ADDR)while True:print("等待请求......")conn,addr = udpser.recvfrom(BUFSIZ) #接收到的消息无需转交udpser.sendto( conn.upper(),addr) #需要的话返回一个结果就可以了print("...来自",addr)udpser.close()
UDP和TCP服务器的另一个重要的区别是,由于数据报套接字是无连接的,所以无法把客户端连接交给另外的套接字进行后续的通讯。
这些服务器只是接收消息,需要的话,给客户端返回一个结果就可以了。
#创建一个客户端服务器
from socket import *HOST = "127.0.0.1"
PORT = 8989
BUFSIZ = 1024
ADDR = (HOST,PORT)udpcli = socket(AF_INET,SOCK_DGRAM)while True:data = input(">>>")if not data:breakudpcli.sendto(data.encode("utf-8"),ADDR)data,ADDR = udpcli.recvfrom(BUFSIZ)if not data:continueprint(data.decode("utf-8"))udpcli.close()
UDP客户端的循环基本上与TCP客户端的完全一样。唯一的区别就是,我们不用先去跟UDP服务器建立连接,而是直接把消息发送出去,然后等待服务器的回复。
还可以,创建多个客户端,UDP不同于TCP需要建立连接。
#服务端
from socket import *
server = socket(AF_INET,SOCK_DGRAM)
server.bind(('127.0.0.1',9100))
while True:conn,addr = server.recvfrom(1024)print("访问来自%s,端口号是:%s" % (addr[0],addr[1]))server.sendto(conn.upper(),addr) #返回消息的时候,必须指定端口号和ip#客户端1
from socket import *
client = socket(AF_INET,SOCK_DGRAM)
while True:data = input(">>>") #发送空格也行,不会报错,一次发送,也不会占用资源client.sendto(data.encode("utf-8"),('127.0.0.1',9100))conn,addr = client.recvfrom(1024)print(conn.decode('utf-8'))#客户端2
from socket import *
client = socket(AF_INET,SOCK_DGRAM)
while True:data = input(">>>")client.sendto(data.encode("utf-8"),('127.0.0.1',9100))conn,addr = client.recvfrom(1024)print(conn.decode('utf-8'))
执行结果:
访问来自127.0.0.1,端口号是:60715
访问来自127.0.0.1,端口号是:60716
小结:
总的来说,UDP和TCP服务的流程相同,有两点:UDP无需提前连接直接发送消息,UDP服务器无法把客户端的连接转交出去。
这篇关于Python教程:socket()模块和套接字对象的内建方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





