本文主要是介绍《数据库开发实践》之存储过程【知识点罗列+例题演练】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、什么是存储过程?
1.概念理解:
存储过程是一组为了完成特定功能的SQL语句集。通过组成SQL语句和控制语句,提供一种封装任务的方法。因此在创建编译好某个存储过程后,因为存储过程中有可执行操作的sql语句,用户可以根据需求,调用该过程时输入参数即可执行。简单一点理解,也就是相当于我们在JAVA里面写的代码一样,封装好 某个类、方法,这样在需要这个方法的时候就去调用其,就不用再重新又写、反复写。
2.存储过程的优点:
| (1)模块化的程序设计 |
| (2)在服务器端运行,具有高效率的执行力 |
| (3)减少网络流量,存储过程在编译后,也就是要在执行一次之后,它的执行规划就会保留在高速缓冲存储器中,用户在后期调用该存储过程时,后台便只需从高速缓冲存储器中调用编译好的二进制代码,提高了系统性能 |
| (4)确保数据库的安全,防止了用户暴露数据库表的细节,可以作为安全机制使用 |
3.存储过程的分类:
- 系统存储过程
- 用户自定义存储过程
二、Mysql语句创建、执行和删除存储过程
1.创建存储过程
| 创建时需要事先确定存储过程的三个组成部分: |
| (1).所有的输入参数以及传给调用者的输出参数。 |
| (2).被执行的针对数据库的操作语句,包括调用其他存储过程的语句。 |
| (3).返回给调用者的状态值以指明调用是成功还是失败。 |
(1) 创建语法格式:
CREATE PROCEDURE 存储过程名 ([参数 ... ]) [特征 ...] 存储过程体a.参数=:[ IN | OUT | INOUT ] 参数名 参数类型
- 参数的命名不要与所联系的数据表的列名出现相同的
- 有多个参数的时候,要用逗号隔开
IN类型——输入参数 可以使数据传递给存储过程 OUT类型——输出参数 当需要返回一个结果时使用 INOUT类型——输入/输出参数 两者都可以充当 b.特征=:LANGUAGE SQL | [NOT] DETERMINISTIC | { CONTAINS SQL | NO SQL | READS SQL DATA | MODIFIES SQL DATA } | SQL SECURITY { DEFINER | INVOKER } | COMMENT 'string'
特征 对应内容 LANGUAGE SQL 存储过程的语言为SQL [NOT] DETERMINISTIC 存储过程是否确定性,即存储过程对同样的输入参数产生的结果是否相同 CONTAINS SQL [默认选项] 存储过程的子程序包含SQL语句,但是不包含读、写数据的语句 NO SQL 存储过程中不包含SQL语句 READS SQL DATA 存储过程只读取SQL数据 MODIFIES SQL DATA 存储过程只修改SQL数据 SQL SECURITY { DEFINER | INVOKER } 存储过程执行的身份者指定
- DEFINER:默认。创建该存储过程的用户许可
- INVOKER:使用存储过程的用户许可
COMMENT 'string' 存储过程的描述备注,string是描述的内容。使用SHOW CREATE PROCEDURE 就可以显示该信息 c.存储过程体:存储过程的主体部分,包含了调用存储过程时必会执行的SQL语句。
- 开始标志是BEGIN,结束标志是END,只有 一条SQL语句时可以省略开始和结束标志;
- 还需要注意的一个点是,因为存储过程里面的SQL语句是以分号结尾的,所以服务器在处理程序的时候遇到第一个分号就会以为要结束程序了,所以需要我们使用“Delimiter 结束符号”命令将Mysql语句的结束标志更改一下,编译后再恢复分号结束标志。
2.修改存储过程特征
MySQL只能通过ALTER语句修改存储过程的特征,不能修改存储过程体的内容,如需修改存储过程体的内容,需要先删除存储过程再重新创建
3.查看存储过程
show procedure status [like 'pattern']; 其中,like 'pattern'为可选参数,用来匹配存储过程的名称,如果不指定该参数,则会查看所有的存储过程。
4.调用执行存储过程
call sp_name[(传参)];
其中,sp_name为所执行的存储过程名称,传参表示根据存储过程定义时的参数进行传参。
5.删除存储过程
drop procedure [if exists] 存储过程名;
三、异常处理
(1)MySQL定义异常捕获类型及处理方法的语法如下:
DECLARE handler_action HANDLER FOR condition_value [, condition_value] ... statement handler_action: CONTINUE | EXIT | UNDO condition_value: mysql_error_code | SQLSTATE [VALUE] sqlstate_value | condition_name|SQLWARNING|NOT FOUND| SQLEXCEPTION
a.HANDLER :异常关键词
b.FOR:声明
c.statement:表示出现某种条件、错误的时候需要执行的语句
- 可以是简单的一句SQL语句
- 可以是复杂的多行语句——这里就需要用起始标签Begin和结束标签End
d.hander_action:异常类型,表示执行完statement后希望系统执行什么动作
- CONTINUE | EXIT | UNDO
- continue:程序继续——SQL WARNING和NO FOUND 的默认处理方法
- exit:跳出程序——SQLEXCEPTION的默认处理方法
- undo:程序回滚,撤销
d.condition_value:表示一个异常处理可以定义成针对多种情况进行相应的操作
condition_value 内容 mysql_error_code MySQL错误码,一个由mysql自定义的数字 SQLSTATE[VALUE] sqlstate_value SQL状态码,一个由五个字符组成的字符串 condition_name 条件名称,使用declare...condition语句定义 SQLWARNING SQL警告,表示SQLSTATE中字符串以‘01’起始的错误 NOT FOUND 找不到,表示SQLSTATE中字符串以‘02’起始的错误 SQLEXCEPTION SQL异常,表示SQLSTATE中字符串不以‘00’,‘01’,‘02’起始的错误
其中,‘00’是表示成功执行。
四、例题演练
1.创建一个存储过程p_yg1:
实现根据传入参数部门名称可以查询各部门所有员工的员工编号,员工姓名和职务。并调用此存储过程查询“技术”部门员工的员工编号,员工姓名和职务
delimiter // create procedure p_yg1( IN departmentName varchar(30)) begin select ygxx.ygbh,ygxx.name,ygxx.zw from ygxx inner join bmxx on ygxx.ssbmbh=bmxx.bmbh where bmxx.bmmc=departmentName; end // delimiter;(1)创建存储过程p_yg1
(2)调用存储过程p_yg1


2.创建一存储过程p_intsp1:
- 通过带参数的存储过程向表spxx中插入一条数据,传入参数为spbh,spmc,sslb,jg,sl
- 如果插入主键重复数据(错误号1062),则将spbh和spmc插入错误记录表splog中
- 数据插入时间赋为当前日期,操作标志位赋上'insert'。
DELIMITER // CREATE PROCEDURE p_intsp1 (IN spbh VARCHAR(20), IN spmc VARCHAR(30), IN sslb VARCHAR(20), IN jg DOUBLE, IN sl INT) BEGINDECLARE t_error INTEGER DEFAULT 0;DECLARE CONTINUE HANDLER FOR 1062 SET t_error = 1;INSERT INTO spxx (spbh, spmc,sslb, jg, sl) VALUES (spbh, spmc,sslb, jg, sl);IF t_error = 1 THENINSERT INTO splog (spbjlog, spmclog, sjlog, bz) VALUES (spbh, spmc, NOW(), 'insert');ELSE COMMIT;END IF;END // DELIMITER ;(1)创建存储过程p_intsp1
(2)调用存储过程
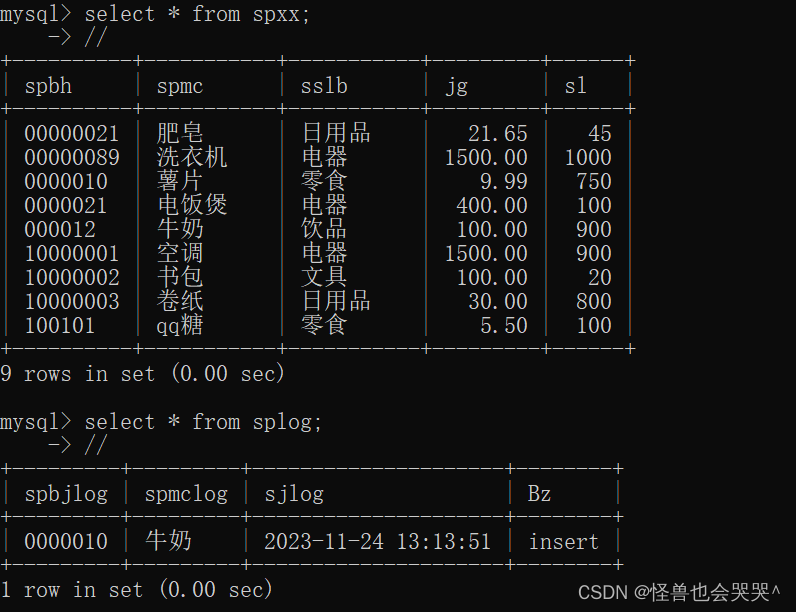
a.展示当前的商品信息表和记录表
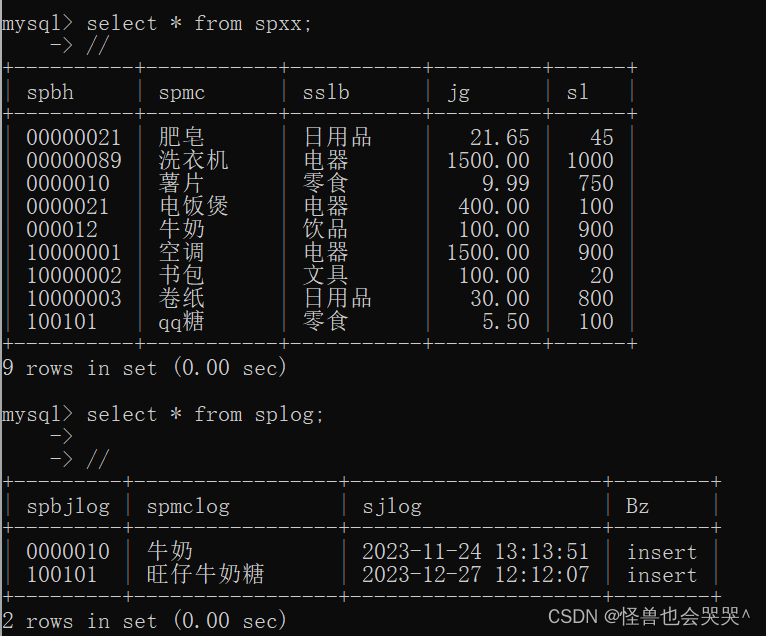
b.插入一条数据,重复了主键id
c.此时商品信息表没有新数据插入,记录log表插入新数据



这篇关于《数据库开发实践》之存储过程【知识点罗列+例题演练】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







