本文主要是介绍【分布式链路追踪技术】sleuth+zipkin,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


目录
1.概述
2.搭建演示工程
3.sleuth
4.zipkin
5.插拔式存储
5.1.存储到MySQL中
5.2.用MQ来流量削峰
6.联系作者
1.概述
当采用分布式架构后,一次请求会在多个服务之间流转,组成单次调用链的服务往往都分散在不同的服务器上。这就会带来一个问题:
故障难以溯源。
发起请求,然后请求报错,到底是调用链中哪一环出了问题?很难以定位。这时候就需要用到链路追踪技术了。所谓的链路追踪技术,也就是想办法让分布式系统中的单次请求的链路调用成为可被追踪的,便于在出现故障的时候进行快速的定位溯源。
目前有两套实现思路:
-
基于日志来实现,常用到的有Sleuth、zipkin
-
基于agent来实现,常用到的有skywaiking
本文讲解的是其中基于日志实现的sleuth以及其配套的可视化套件zipkin。
关于分布式链路追踪作者上文讲过详细的概论:
https://bugman.blog.csdn.net/article/details/135175596?spm=1001.2014.3001.5502
2.搭建演示工程
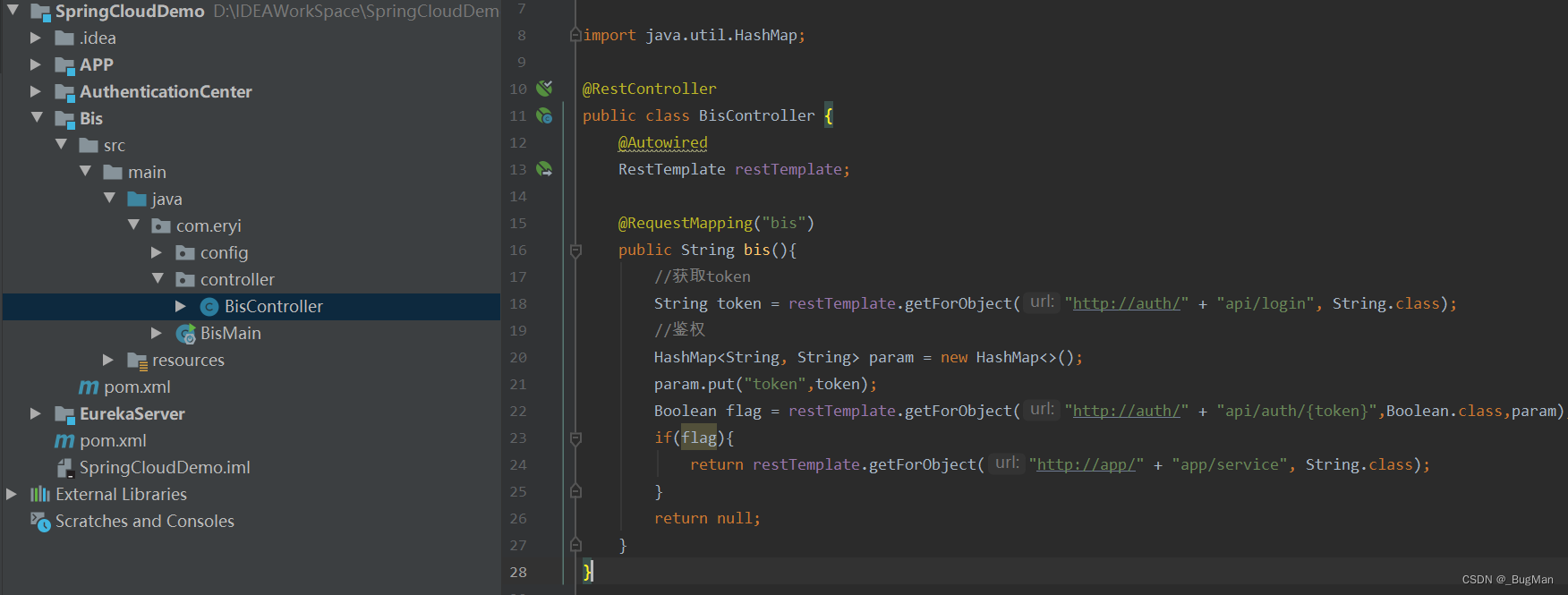
本次用于演示的工程很简单,用spring cloud来搭建三个服务,一个app服务用来提供服务,一个鉴权中心用来登录以及鉴权,一个bis服务用来聚合:

在bis中调用鉴权中心来登录获取token,然后校验token,校验通过后调用app提供的服务:
spring cloud的成体系的文章,在博主的另一个专栏,从0开始一步步深入浅出(该系列登上过2023年的新星计划):
http://t.csdnimg.cn/PDgr3
3.sleuth
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>3.1.8</version>
</dependency>
去访问bis,会看到:
bis的日志:

AuthenticationCenter的日志:

APP的日志:

我想到这里很多读者会有个疑问。
问:
sleuth这么保证一个链路上的traceID是相同的?
答:
当一个请求进入 Spring Cloud 的微服务系统时,Sleuth 会生成一个唯一的 Trace ID。如果请求是从另一个使用 Sleuth 的服务传入的,Sleuth 会提取并使用该服务传入的 Trace ID。Sleuth 集成了这些通信协议,如HTTP协议,并在服务间调用时自动将 Trace ID 添加到 HTTP 请求的头部、消息的元数据等中。
4.zipkin
光有了日志,进行问题排查还是要一条条的翻,还是很繁琐。所以配套出现了可视化套件,由推特开发的——zipkin。其能对标准opentracing格式的日志进行收集和展示。zipkin采用的标准的CS架构,client向server发数据。
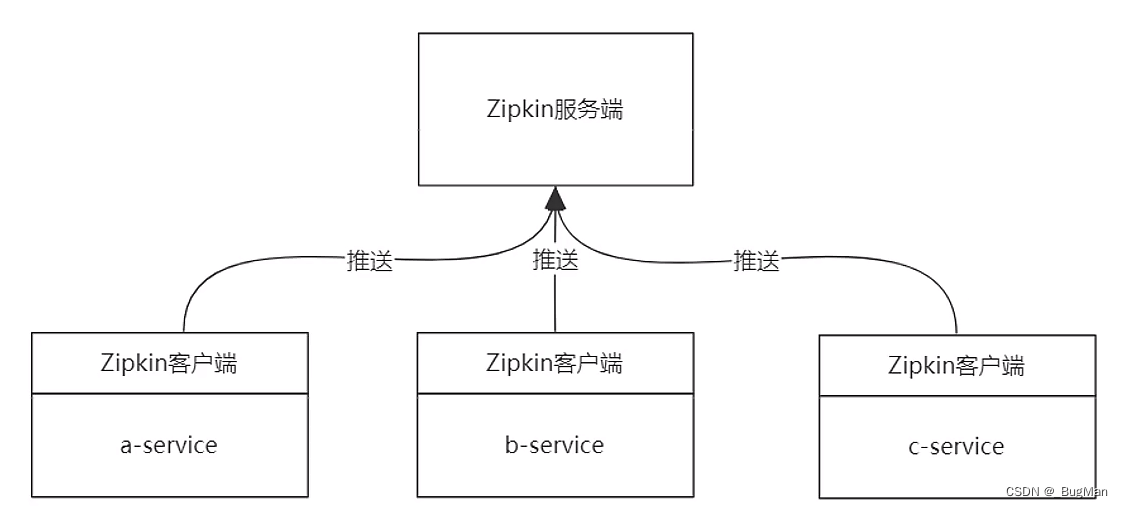
服务端:
服务端是一个jar包,直接跑起来就可以,下载地址:
Central Repository: io/zipkin/zipkin-server
客户端:
依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.1.RELEASE</version>
</dependency>
配置:
#zipkin server地址
spring.zipkin.base-url=http://localhost:9411/
#client向server发送数据的方式,web,http报文
spring.zipkin.sender.type=web
效果:
zipkin的启动日志里已经清晰的告诉了Web界面的访问地址是多少:

访问127.0.0.1:9411/可以看到:
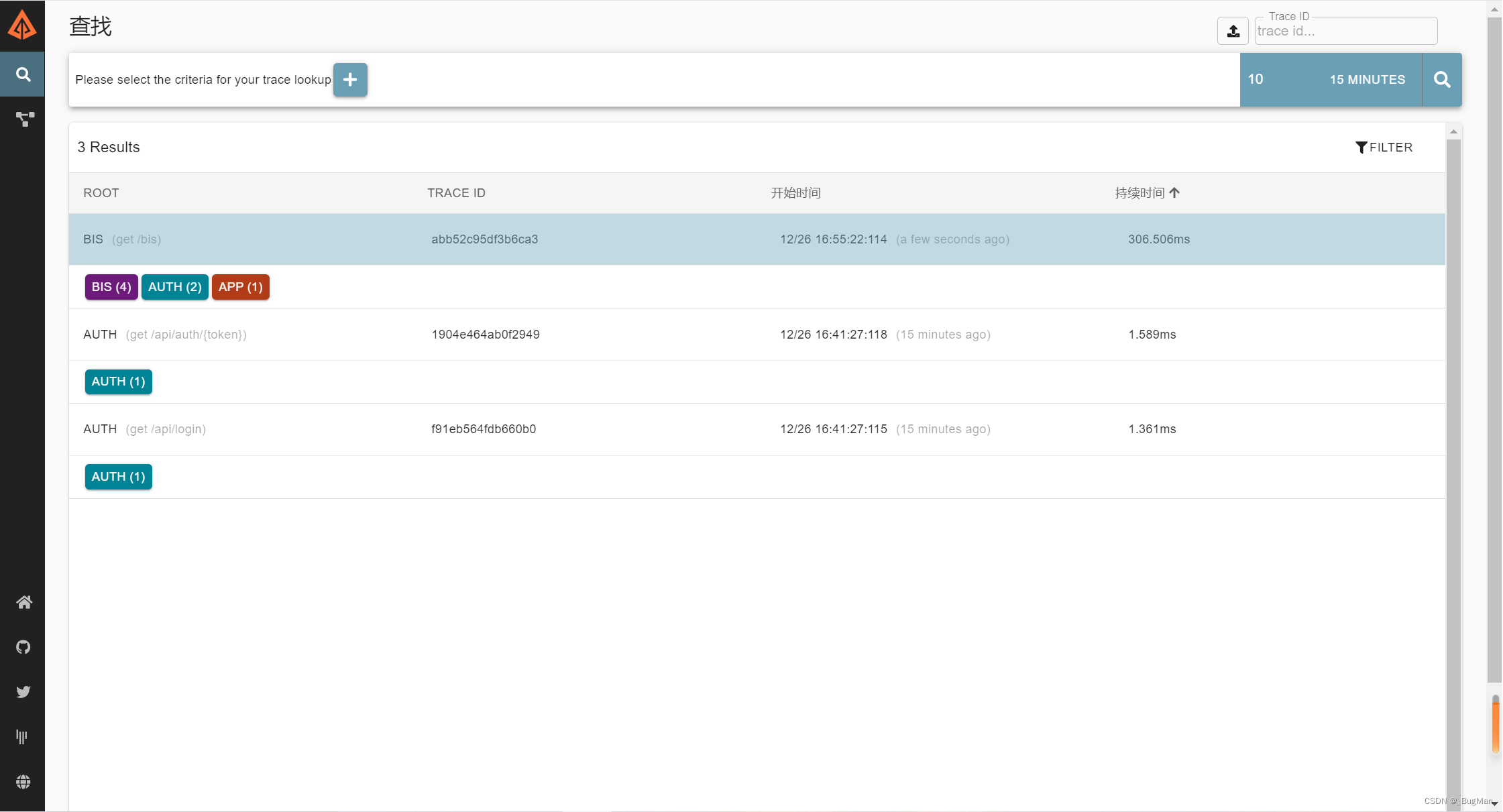
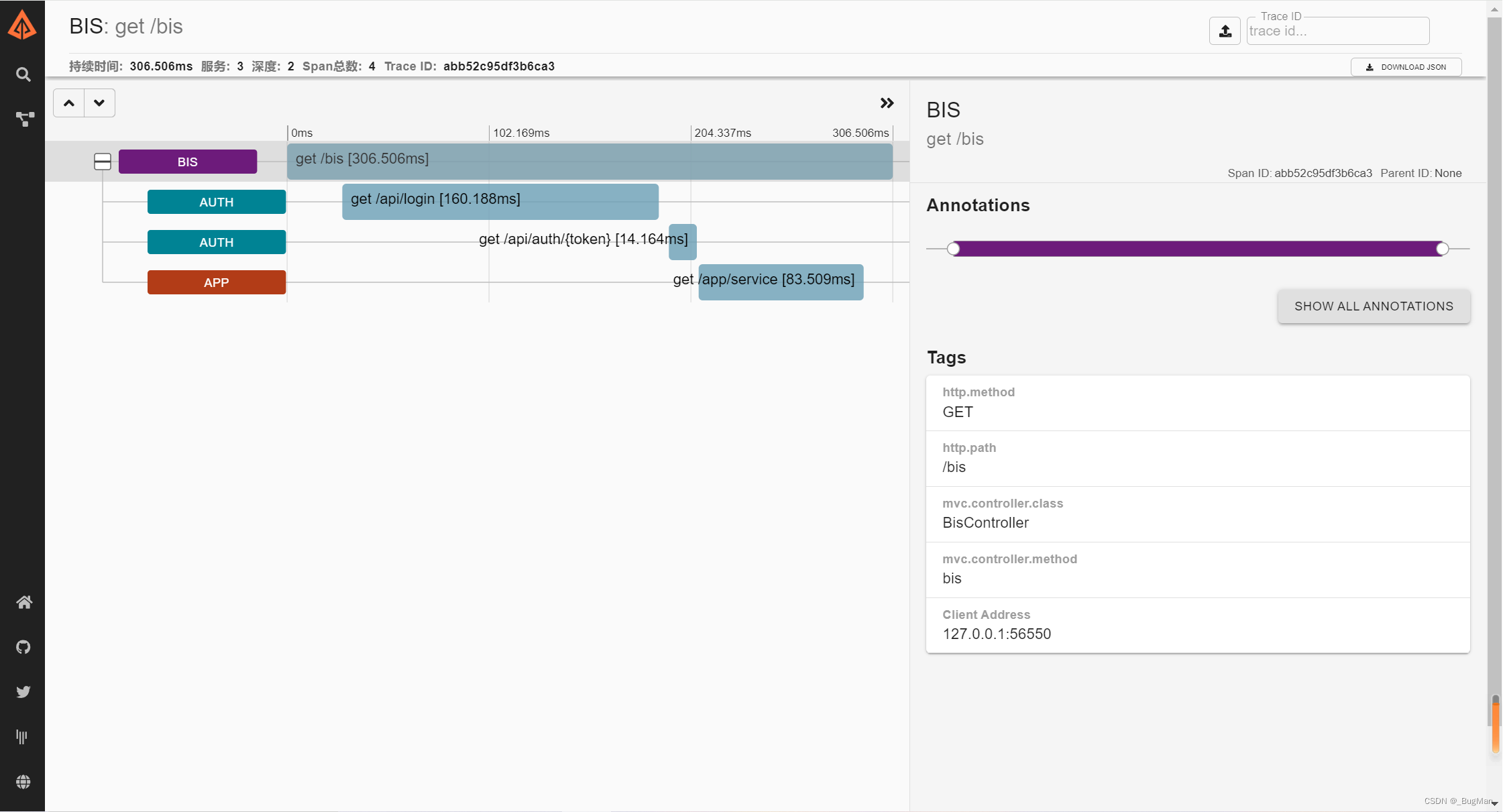
点进链路可以看到单次请求的详细内容:
5.插拔式存储
zipkin从各个client中收集到的server上的数据存到哪儿去?默认是将数据存储在内存中,除此之外zipkin还支持多种数据的存储方式,如mysql、ES等,根据场景需要可自行切换。
5.1.存储到MySQL中
要存储到MySQL中首先当然是要先建表,zipkin在项目文件中自带了mysql的建表脚本:
https://github.com/openzipkin/zipkin/blob/master/zipkin-storage/mysql-v1/src/main/resources/mysql.sql
server的源码工程的配置文件中可以看到,存储默认是内存,参数有默认值,但是支持传参来设置:
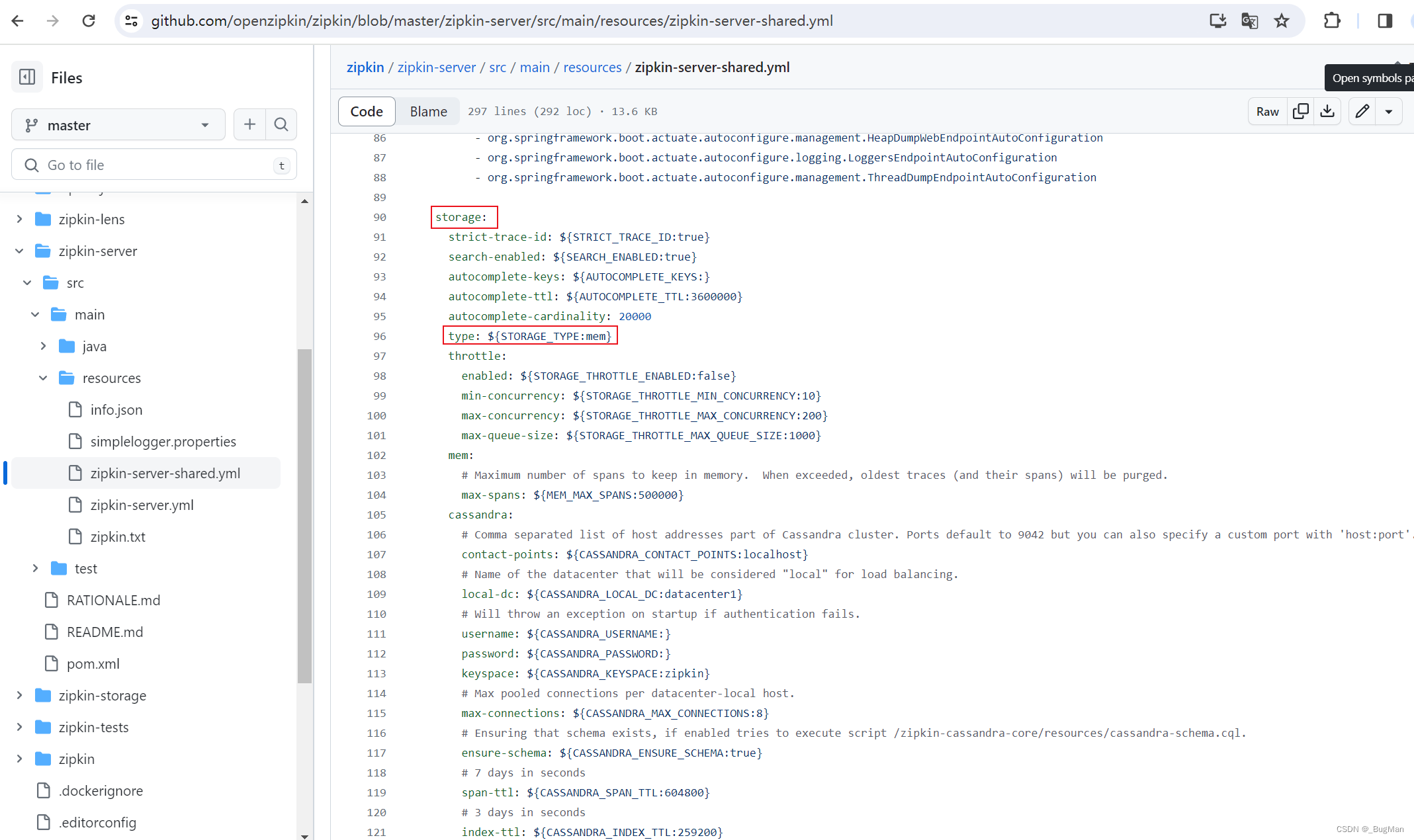
所以在用java -jar启动的时候可以通过跟参数的方式来切换存储类型:
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSOL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=admin --MYSQL_DB=zipkin
这样数据就会存进MySQL中来进行持久化了。
5.2.用MQ来流量削峰
zipkin支持多种数据的存储方式,如mysql、ES等,默认是将数据存储在内存中。
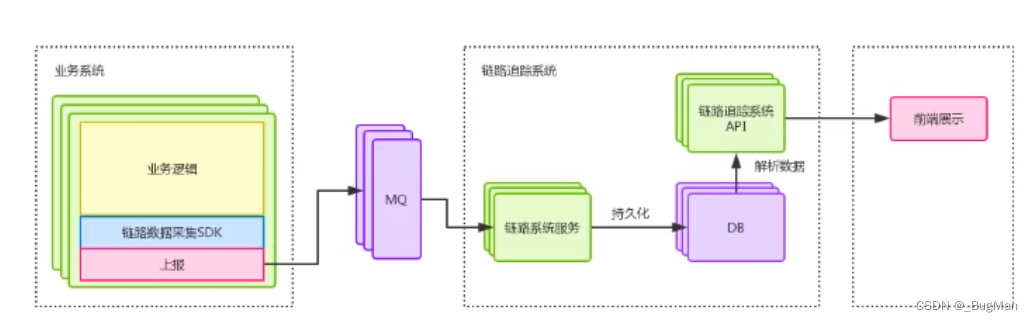
server端:
从配置文件中可以看到,zipkin server支持Kafka、rabbitMQ等多种MQ,具体配置是用启动传参的方式来配置的:

想用哪种MQ,直接去配置即可,这里以rabbitMQ为例:
java -jar zipkin-server-2.20.1-exec.jar --STORAGE_TYPE=mysql --MYSQL_HOST=localhost --MYSOL-TCP-PORT=3306 --MYSOL_USER=root --MYSQL_PASS=admin --MYSQL_DB=zipkin --RABBIT_ADDRESSES=10.1.2.10:5672 --RABBIT_USER=quest --RABBIT_PASSWORD=guest --RABBIT_VIRTUAL_HOST=/ --RABBIT_QUEUE=zipkin
client端:
client端增加以下关于mq的配置:
#zipkin server地址
spring.zipkin.base-url=http://localhost:9411/
#client向server发送数据的方式,rabbitmq
spring.zipkin.sender.type=rabbit
#队列名称
spring.zipkin.rabbitmq.queue=zipkin
#服务器IP、端口号、账户名、密码
spring.rabbitmq.host=10.1.2.10
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
#虚拟主机地址
spring.rabbitmq.virtual-host=/
#是否开启发布重试
spring.rabbitmq.listener.direct.retry.enabled=true
#最大重试次数
spring.rabbitmq.listener.direct.retry.max-attempts=5
#重试间隔时间
spring.rabbitmq.listener.direct.retry.initial-interval=5000
#是否开启消费者重试
spring.rabbitmq.listener.simple.retry.enabled=true
#最大重试次数
spring.rabbitmq.listener.simple.retry.max-attempts=5
#最大间隔时间
spring.rabbitmq.listener.simple.retry.initial-interval=5000
6.联系作者
公众号:
博主会在上面成体系的输出后端干货。

商务合作、各种交流:
这篇关于【分布式链路追踪技术】sleuth+zipkin的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





