本文主要是介绍肥肥的主管和帅气的小饭饭讨论了下ForkJoinPool,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
肥肥的主管: 小饭饭,了解ForkJoinPool吗
帅气的小饭饭:了解啊,Caffeine中默认用到的处理线程池就是这个
肥肥的主管:和ThreadPoolExecutor有什么区别吗?
帅气的小饭饭:(⊙o⊙)…,这个没了解
肥肥的主管:有什么应用场景吗?能引入我们的游戏中吗?有什么弊端吗?
帅气的小饭饭:(⊙o⊙)…,我周末研究下
以上就是我,帅气的小饭饭被小肥肥刁难的日常了。

每次看到这个,总会邪恶的想到FuckXXX的。
其实好久前就知道这个FuckXXX了,比如Caffeine、Netty中默认提供的线程池,只是一直没有去研究它。
过了个周末,我李汉三终于搞懂了ForkJoinPool了,终于可以和小肥肥正面肝上了

「看完该篇文章你大概可以了解到这些知识点:」
ForkJoinPool是什么
和ThreadPoolExecutor有什么区别
应用场景是啥
好处和弊端
常见面试题
小肥肥: 周末不是研究了下ForkJoinPool吗?说说看是啥东西啊这?
*帅气的小饭饭:* 是啊是啊,可卖力了,现在已经研究透彻了,
ForkJoinPool是JDK7引入的线程池,核心思想是将大的任务拆分成多个小任务(即fork),然后在将多个小任务处理汇总到一个结果(即join),非常像MapReduce处理原理。
同时呢,它还提供基本的线程池功能,支持设置最大并发线程数,支持任务排队,支持线程池停止,支持线程池使用情况监控,也是AbstractExecutorService的子类,主要引入了“工作窃取”机制,在多CPU计算机上处理性能更佳。
为了让你看清楚这个过程,我还特地画了个流程图给你look look
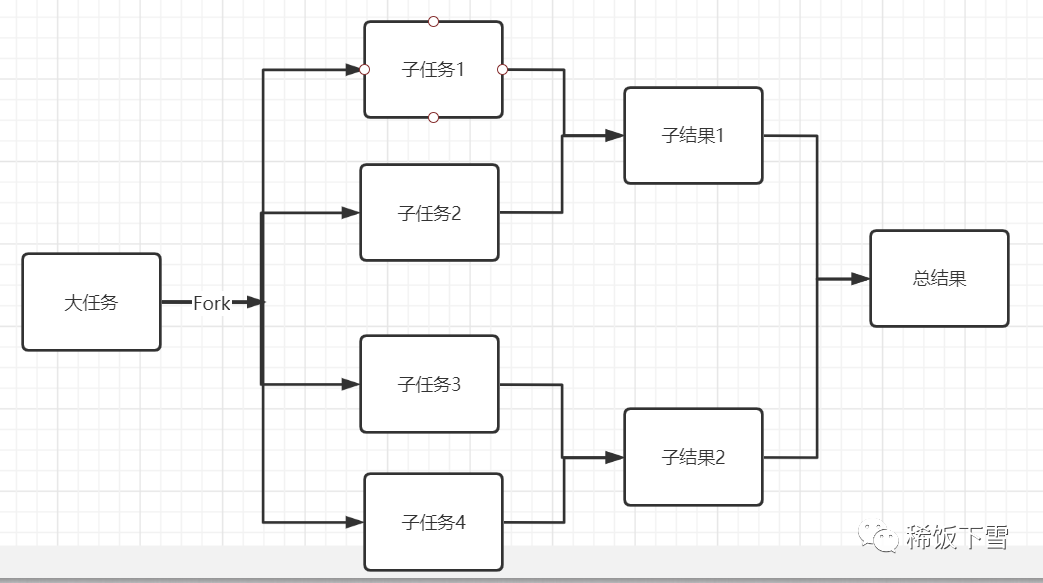
小肥肥:什么叫“工作窃取”机制啊,这么屌的
*帅气的小饭饭:*和它的名字一样啊,就是窃取啊,work-stealing(工作窃取),ForkJoinPool提供了一个更有效的利用线程的机制,当ThreadPoolExecutor还在用单个队列存放任务时,ForkJoinPool已经分配了与线程数相等的队列,当有任务加入线程池时,会被平均分配到对应的队列上,各线程进行正常工作,当有线程提前完成时,会从队列的末端“窃取”其他线程未执行完的任务,当任务量特别大时,CPU多的计算机会表现出更好的性能,就是这么强啊。

小肥肥: 我擦,好强,原理是啥啊
*帅气的小饭饭:*原理啊,我罗列下吧
ForkJoinPool 的每个工作线程都维护着一个工作队列(
WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。每个工作线程在运行中产生新的任务,通常是因为调用了fork(),会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务,这个窃取行为或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列,窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
*小肥肥:*了解了,那除此之外还和ThreadPoolExecutor有什么区别吗
*帅气的小饭饭:*(⊙o⊙)…,最大的区别就是这个工作窃取机制了,其他的,我想想看哦,突然想到了我们游戏内的线程池模型
我们游戏内使用的ThreadPoolExecutor线程池内的对应线程池是有明确规定的,比如A线程只能处理一批玩家的数据,B线程只能处理另一批玩家的数据,这里用了取摩的思想,而ForkJoinPool 这种窃取思想,自身是并行计算,无法对对应线程进行明确的工作划分,单纯这点来说,其实就不适合用来做我们的线程模型的载体了。
*小肥肥:*嗯,也是,那它有啥应用场景呢
*帅气的小饭饭:*ForkJoinPool 最适合的是计算密集型的任务,如果存在 I/O,线程间同步,sleep() 等会造成线程长时间阻塞的情况时,最好配合使用 ManagedBlocker,或者不用。
为了让小肥肥看清楚这个应用场景,我打开了idea,怒写了以下代码【其实是从网上看到的例子】
方案一:平平无奇的for循环解决
public interface Calculator {/*** 把传进来的所有numbers 做求和处理** @param numbers* @return 总和*/long sumUp(long[] numbers);
}日常代码
public class ForLoopCalculator implements Calculator {@Overridepublic long sumUp(long[] numbers) {long total = 0;for (long i : numbers) {total += i;}return total;}
}执行类
public static void main(String[] args) {long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();Instant start = Instant.now();Calculator calculator = new ForLoopCalculator();long result = calculator.sumUp(numbers);Instant end = Instant.now();System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");System.out.println("结果为:" + result); }
输出:
耗时:10ms
结果为:50000005000000
方案二:ExecutorService多线程方式实现
public class ExecutorServiceCalculator implements Calculator {private int parallism;private ExecutorService pool;public ExecutorServiceCalculator() {parallism = Runtime.getRuntime().availableProcessors(); // CPU的核心数 默认就用cpu核心数了pool = Executors.newFixedThreadPool(parallism);}//处理计算任务的线程private static class SumTask implements Callable<Long> {private long[] numbers;private int from;private int to;public SumTask(long[] numbers, int from, int to) {this.numbers = numbers;this.from = from;this.to = to;}@Overridepublic Long call() {long total = 0;for (int i = from; i <= to; i++) {total += numbers[i];}return total;}}@Overridepublic long sumUp(long[] numbers) {List<Future<Long>> results = new ArrayList<>();// 把任务分解为 n 份,交给 n 个线程处理 4核心 就等分成4份呗// 然后把每一份都扔个一个SumTask线程 进行处理int part = numbers.length / parallism;for (int i = 0; i < parallism; i++) {int from = i * part; //开始位置int to = (i == parallism - 1) ? numbers.length - 1 : (i + 1) * part - 1; //结束位置//扔给线程池计算results.add(pool.submit(new SumTask(numbers, from, to)));}// 把每个线程的结果相加,得到最终结果 get()方法 是阻塞的// 优化方案:可以采用CompletableFuture来优化 JDK1.8的新特性long total = 0L;for (Future<Long> f : results) {try {total += f.get();} catch (Exception ignore) {}}return total;}
}
执行类
public static void main(String[] args) {long[] numbers = LongStream.rangeClosed(1, 10000000).toArray();Instant start = Instant.now();Calculator calculator = new ExecutorServiceCalculator();long result = calculator.sumUp(numbers);Instant end = Instant.now();System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");System.out.println("结果为:" + result); // 打印结果500500}
输出:
耗时:30ms
结果为:50000005000000
方案三:采用ForkJoinPool(Fork/Join)
public class ForkJoinCalculator implements Calculator {private ForkJoinPool pool;//执行任务RecursiveTask:有返回值 RecursiveAction:无返回值private static class SumTask extends RecursiveTask<Long> {private long[] numbers;private int from;private int to;public SumTask(long[] numbers, int from, int to) {this.numbers = numbers;this.from = from;this.to = to;}//此方法为ForkJoin的核心方法:对任务进行拆分 拆分的好坏决定了效率的高低@Overrideprotected Long compute() {// 当需要计算的数字个数小于6时,直接采用for loop方式计算结果if (to - from < 6) {long total = 0;for (int i = from; i <= to; i++) {total += numbers[i];}return total;} else { // 否则,把任务一分为二,递归拆分(注意此处有递归)到底拆分成多少分 需要根据具体情况而定int middle = (from + to) / 2;SumTask taskLeft = new SumTask(numbers, from, middle);SumTask taskRight = new SumTask(numbers, middle + 1, to);taskLeft.fork();taskRight.fork();return taskLeft.join() + taskRight.join();}}}public ForkJoinCalculator() {// 也可以使用公用的线程池 ForkJoinPool.commonPool():// pool = ForkJoinPool.commonPool()pool = new ForkJoinPool();}@Overridepublic long sumUp(long[] numbers) {Long result = pool.invoke(new SumTask(numbers, 0, numbers.length - 1));pool.shutdown();return result;}
}
输出:
耗时:390ms
结果为:50000005000000
方案四:采用并行流
public static void main(String[] args) {Instant start = Instant.now();long result = LongStream.rangeClosed(0, 10000000L).parallel().reduce(0, Long::sum);Instant end = Instant.now();System.out.println("耗时:" + Duration.between(start, end).toMillis() + "ms");System.out.println("结果为:" + result); // 打印结果500500}
输出:
耗时:130ms
结果为:50000005000000
并行流底层也是Fork/Join框架,只是任务拆分优化得很好。
耗时效率方面解释:Fork/Join 并行流等当计算的数字非常大的时候,优势才能体现出来。也就是说,如果你的计算比较小,或者不是CPU密集型的任务,不太建议使用并行处理。
小肥肥: 不明觉厉,看起来就是不适用,使用它的好处和弊端呢?
帅气的小饭饭:好处就是对CPU的充分利用了,特别是在计算密集型的任务的时候,弊端就是需要对任务进行拆分,拆分的好坏也意味着任务的好坏,对开发人员来说,还是有点成本存在的。
小肥肥: 嗯,确实,我这边有份简历,有某初级游戏开发说用上了这个技术,你设计下相关面试题问问人家吧。
帅气的小饭饭: 好吧,那这边大概设计以下几道面试题吧
什么是ForkJoin?
说说看ForkJoin的内部原理?
大概聊聊工作窃取机制?
如何充分利用CPU,计算超大数组中所有整数的和?
这些面试题的答案基本上都在我们聊的话题中啦。
小肥肥: 挺好的,等着升资深开发吧你,周末还学习,对了,总结下,将刚刚的聊天记录总结下,然后后期做个分享。
帅气的小饭饭: 哦豁,可以啊,先加点钱啊,穷啊,我总结下吧
ForkJoinPool特别适合于“分而治之”算法的实现;
ForkJoinPool和ThreadPoolExecutor是互补的,不是谁替代谁的关系,二者适用的场景不同;
ForkJoinTask有两个核心方法——fork()和join(),有三个重要子类——RecursiveAction、RecursiveTask和CountedCompleter;
ForkjoinPool内部基于“工作窃取”算法实现;
每个线程有自己的工作队列,它是一个双端队列,自己从队列头存取任务,其它线程从尾部窃取任务;
ForkJoinPool最适合于计算密集型任务,但也可以使用ManagedBlocker以便用于阻塞型任务;
RecursiveTask内部可以少调用一次fork(),利用当前线程处理,这是一种技巧;
- 原创不易,帮忙点个在看、分享支持一下 -
- 往期文章推荐 -

聊聊Autowired的常考面试题

面试官告诉你什么是JMM和常考面试题

去年面了多个候选人,看看我挖的坑还有他们应该要补的Java基础(二)

去年面了多个候选人,看看我挖的坑还有他们应该要补的Java基础(一)

一起玩dubbo,万字长文揭秘服务暴露
一起玩dubbo,先入个门
帅气的小饭饭带你看看这个世界
这篇关于肥肥的主管和帅气的小饭饭讨论了下ForkJoinPool的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







