本文主要是介绍Visual Studio 2022 使用 Obfuscar 进行代码混淆,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、为什么要混淆
可以通过反编译程序集,直接就能看到你的源代码,这显然很不利于企业进行知识产权保护。
反编译方法可以参考:
https://www.cnblogs.com/Can-daydayup/p/17724033.html
二、有哪些混淆工具
Obfuscar、ConfuserEx、Dotfuscator、.NETReactor、Eazfuscator.NET、Xeoncode、Foxit等等,非常多。
三、Obfuscar的使用
我们介绍开源的Obfuscar。这是一个非常老牌的混淆工具,从 2014 年就对外分发。而且此工具也在不断持续迭代更新,完全支持 dotnet 6 版本,对 WPF 和 WinForms 等等的支持也是非常好,支持多个不同混淆方式和等级的配置,支持混淆之后生成符号文件。此工具是由 Lex Li 主导开发的,在 GitHub 上使用 MIT 最友好协议开源。此工具的使用方式有多个不同的方式,我比较推荐直接放在visual studio 2022中使用,因为开发完顺带就混淆编译,很省事。
1、通过Nuget安装Obfuscar。

2、在工程中新建Obfuscar.xml文件
内容如下:
<?xml version='1.0'?>
<Obfuscator><!-- 输入的工作路径,采用如约定的 Windows 下的路径表示法,如以下表示当前工作路径 --><!-- 推荐使用当前工作路径,因为 DLL 的混淆过程,需要找到 DLL 的所有依赖。刚好当前工作路径下,基本都能满足条件 --><Var name="InPath" value=".\bin\Debug\net6.0" /><!-- 混淆之后的输出路径,如下面代码,设置为当前工作路径下的 Obfuscar 文件夹 --><!-- 混淆完成之后的新 DLL 将会存放在此文件夹里 --><Var name="OutPath" value=".\bin\Debug\net6.0\Obfuscar" /><!-- 以下的都是细节的配置,配置如何进行混淆 --><!-- 使用 KeepPublicApi 配置是否保持公开的 API 不进行混淆签名,如公开的类型公开的方法等等,就不进行混淆签名了 --><!-- 语法的写法就是 name 表示某个开关,而 value 表示值 --><!-- 对于大部分的库来说,设置公开的 API 不进行混淆是符合预期的 --><Var name="KeepPublicApi" value="true" /><!-- 设置 HidePrivateApi 为 true 表示,对于私有的 API 进行隐藏,隐藏也就是混淆的意思 --><!-- 可以通过后续的配置,设置混淆的方式,例如使用 ABC 字符替换,或者使用不可见的 Unicode 代替 --><Var name="HidePrivateApi" value="true" /><!-- 设置 HideStrings 为 true 可以设置是否将使用的字符串进行二次编码 --><!-- 由于进行二次编码,将会稍微伤一点点性能,二次编码需要在运行的时候,调用 Encoding 进行转换为字符串 --><Var name="HideStrings" value="true" /><!-- 设置 UseUnicodeNames 为 true 表示使用不可见的 Unicode 字符代替原有的命名,通过此配置,可以让反编译看到的类和命名空间和成员等内容都是不可见的字符 --><Var name="UseUnicodeNames" value="true" /><!-- 是否复用命名,设置为 true 的时候,将会复用命名,如在不同的类型里面,对字段进行混淆,那么不同的类型的字段可以是重名的 --><!-- 设置为 false 的时候,全局将不会有重复的命名 --><Var name="ReuseNames" value="true" /><!-- 配置是否需要重命名字段,默认配置了 HidePrivateApi 为 true 将都会打开重命名字段,因此这个配置的存在只是用来配置为 false 表示不要重命名字段 --><Var name="RenameFields" value="true" /><!-- 是否需要重新生成调试信息,生成 PDB 符号文件 --><Var name="RegenerateDebugInfo" value="false" /><Var name="OptimizeMethods" value="true"/><Var name="SuppressIldasm" value="false"/><!-- 需要进行混淆的程序集,可以传入很多个,如传入一排排 --><!-- <Module file="$(InPath)\Lib1.dll" /> --><!-- <Module file="$(InPath)\Lib2.dll" /> --><Module file="$(InPath)\UavDataServer.dll"><!--SkipType跳过指定的类 Program是Main所在的类名--><!--<SkipType name="Program" />--><!--SkipMethod 跳过指定的方法--><!--<SkipMethod type="Program" name="Main"/>--></Module><Module file="$(InPath)\UavDataWorkerService.exe"><!--SkipType跳过指定的类 Program是Main所在的类名--><!--<SkipType name="Program" />--><!--SkipMethod 跳过指定的方法--><!--<SkipMethod type="Program" name="Main"/>--></Module><!-- 程序集的引用加载路径,对于 dotnet 6 应用,特别是 WPF 或 WinForms 项目,是需要特别指定引用加载路径的 --><!-- 这里有一个小的需要敲黑板的知识点,应该让 Microsoft.WindowsDesktop.App 放在 Microsoft.NETCore.App 之前 --><!-- 对于部分项目,如果没有找到如下顺序,将会在混淆过程中,将某些程序集解析为旧版本,从而失败 --><!--<AssemblySearchPath path="C:\Program Files\dotnet\shared\Microsoft.WindowsDesktop.App\6.0.1\" /><AssemblySearchPath path="C:\Program Files\dotnet\shared\Microsoft.NETCore.App\6.0.1\" />-->
</Obfuscator>其中,
InPath是你要混淆的dll或exe所在的目录,一般是你的生成目录,要改成你自己的相对路径。
OutPath则是混淆完成后的新dll或exe所输出到的目标目录,自己改。
Module标签则需要设置要混淆哪些dll或exe,有多个就添加多个Module标签。

3、设置生成事件指令
项目属性中,添加生成后事件
"$(Obfuscar)" Obfuscar.xml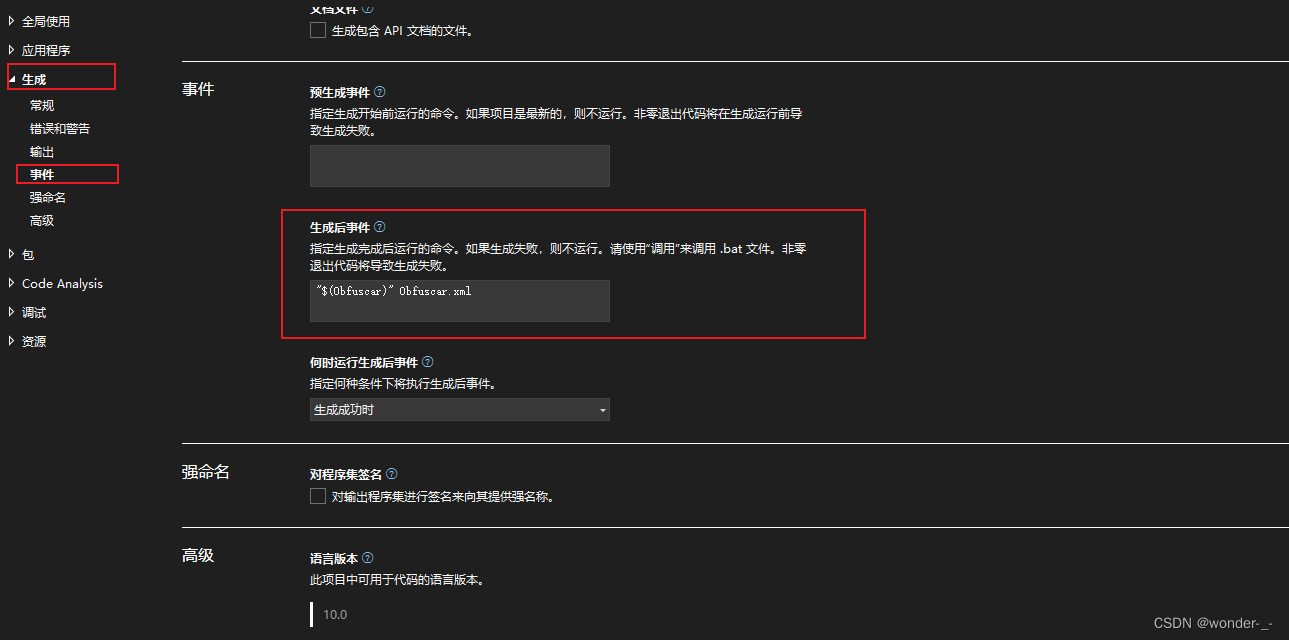
4、最后编译运行即可,在我的输出路径下,能看到

然后把混淆后的新dll替换到程序目录下,发给运维上线即可。
5、对了,验证下是否混淆效果
使用ILSpy打开混淆后的dll,发现方法名、参数、一些变量名都被混淆了:

我的需求达到这样的效果已经足够了。具体混淆哪些内容都是通过那个xml进行配置的,具体详细学习要仔细看官方文档了。
问题记录:exe混淆没成功,还没时间研究是什么问题。不过一般混淆dll已经足够了。
参考:
Obfuscar的使用_obfuscar 使用-CSDN博客
这篇关于Visual Studio 2022 使用 Obfuscar 进行代码混淆的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




