本文主要是介绍论文阅读——UniRepLKNet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
UniRepLKNet: A Universal Perception Large-Kernel ConvNet for Audio, Video, Point Cloud, Time-Series and Image Recognition
当我们将一个3×3的conv添加到一个小卷积核ConvNet中时,我们预计它会同时产生三种效果——1)使感受野更大,2)增加空间模式的抽象层次(例如,从角度和纹理到对象的形状),3)通过使其更深入,引入更多可学习的参数和非线性,来提高模型的一般表示能力。相比之下,我们认为,在大卷积核架构中,这三种影响应该解耦,因为模型应该利用大卷积核的实质性优势——即不深入就可以看到广泛的东西。由于在扩大感受野时,增加卷积核大小比堆叠更多层要有效得多,因此可以用少量的大卷积核层来建立足够的ERF,从而可以为其他有效结构节省计算预算,这些结构在增加空间模式的抽象层次或通常增加深度方面更有效。
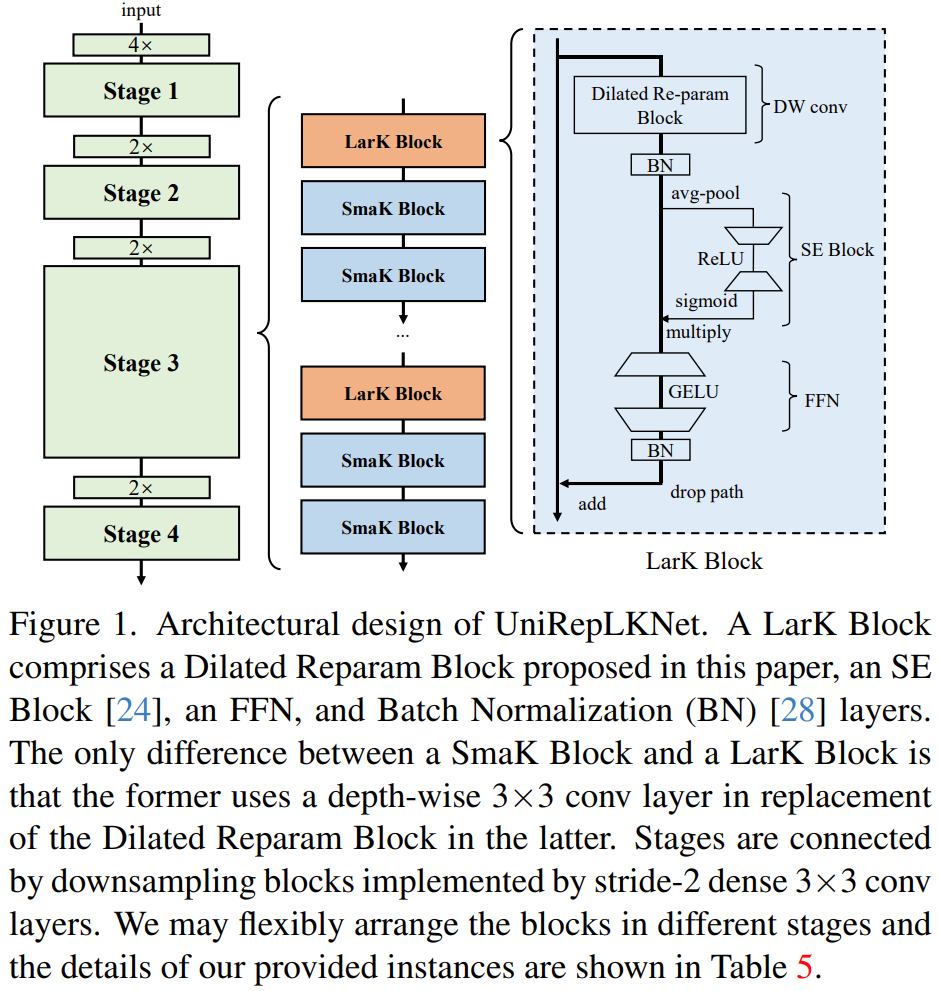
Dilated Reparam Block
膨胀卷积中忽略输入的像素相当于将额外的零项插入到conv卷积核中,因此具有小卷积核的膨胀conv层可以等效地转换为具有稀疏较大内核的非膨胀(即,r=1)层。
原来的卷积核:![]()
插零后:![]()
可以通过步长为r的转置卷积实现:![]()
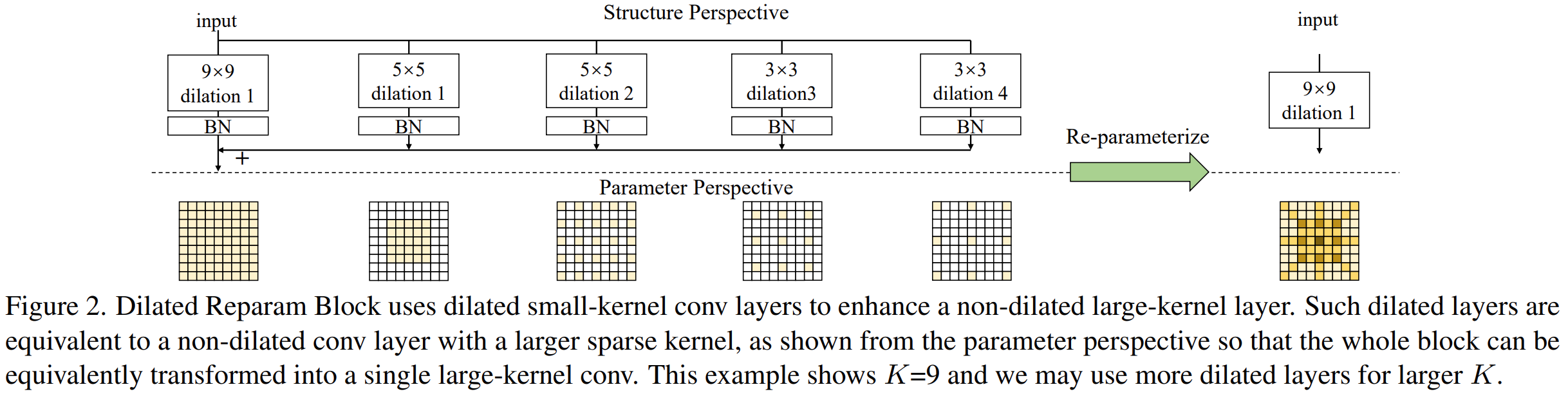
Reparam块,它使用一个非膨胀的小卷积核和多个膨胀的小卷积核层来增强非膨胀的大卷积核conv层。大核大小K,平行的卷积层大小k,膨胀率r,
另外设计了四个结构加深模型:

不同卷积核:

不同模块:

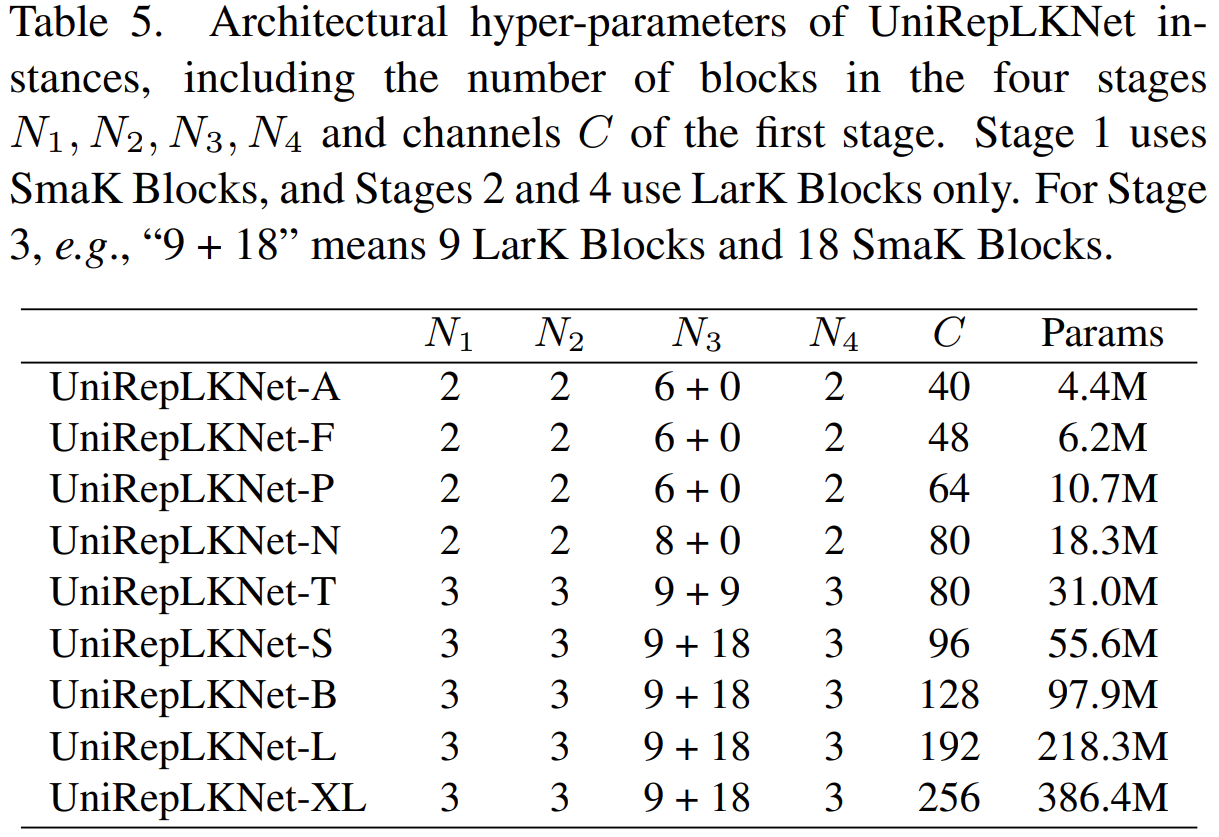
不同大小模型:
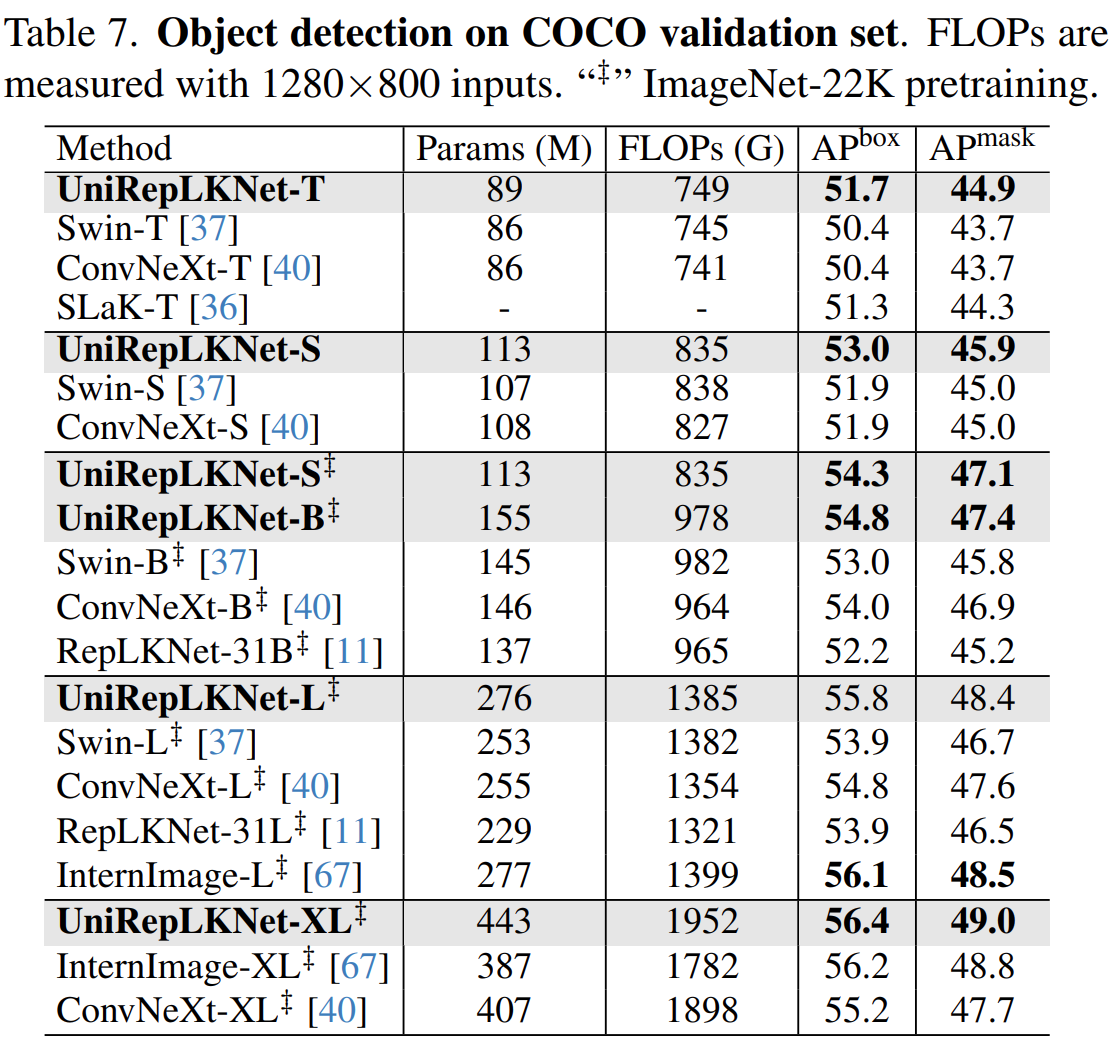
在不同任务的表现:
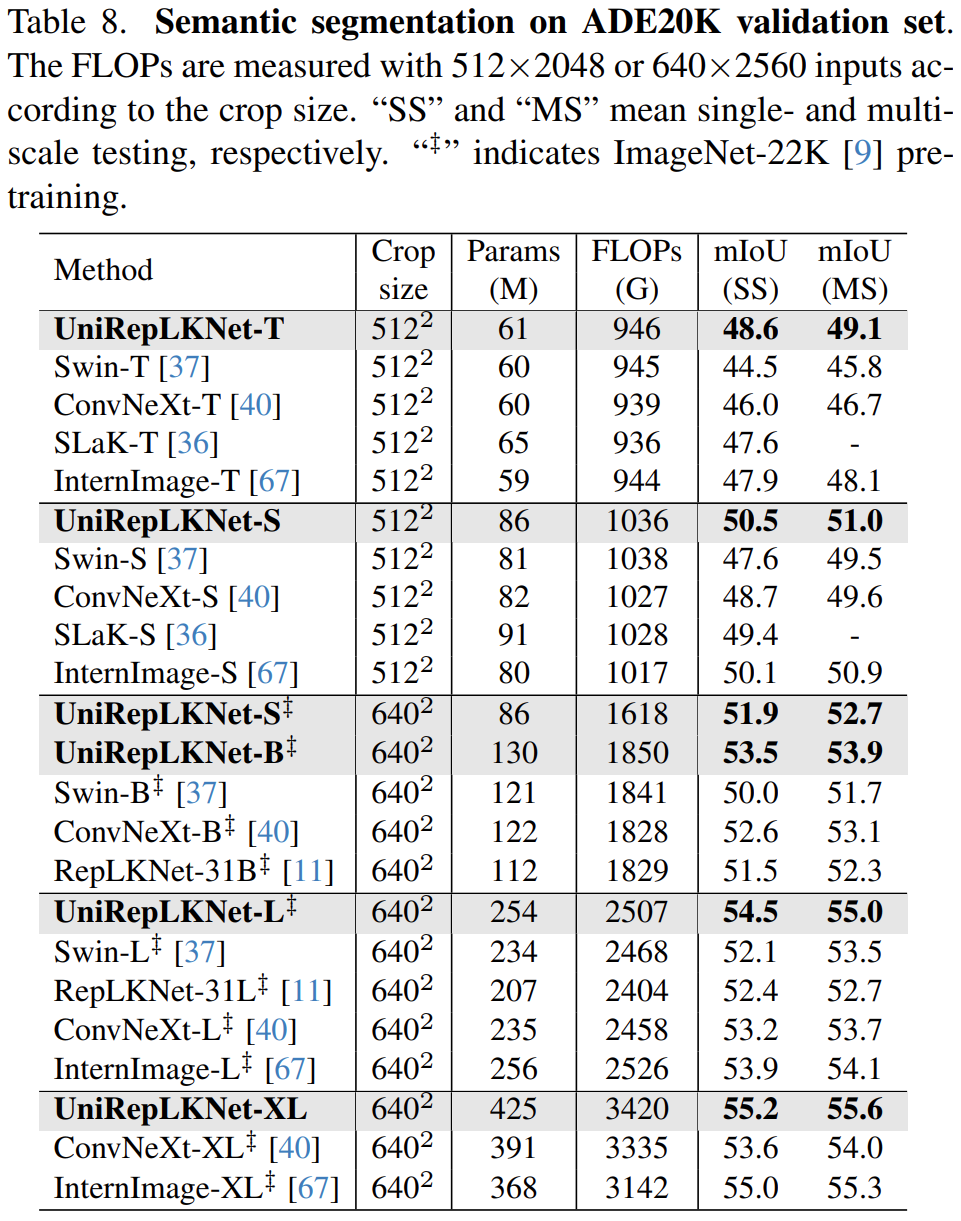
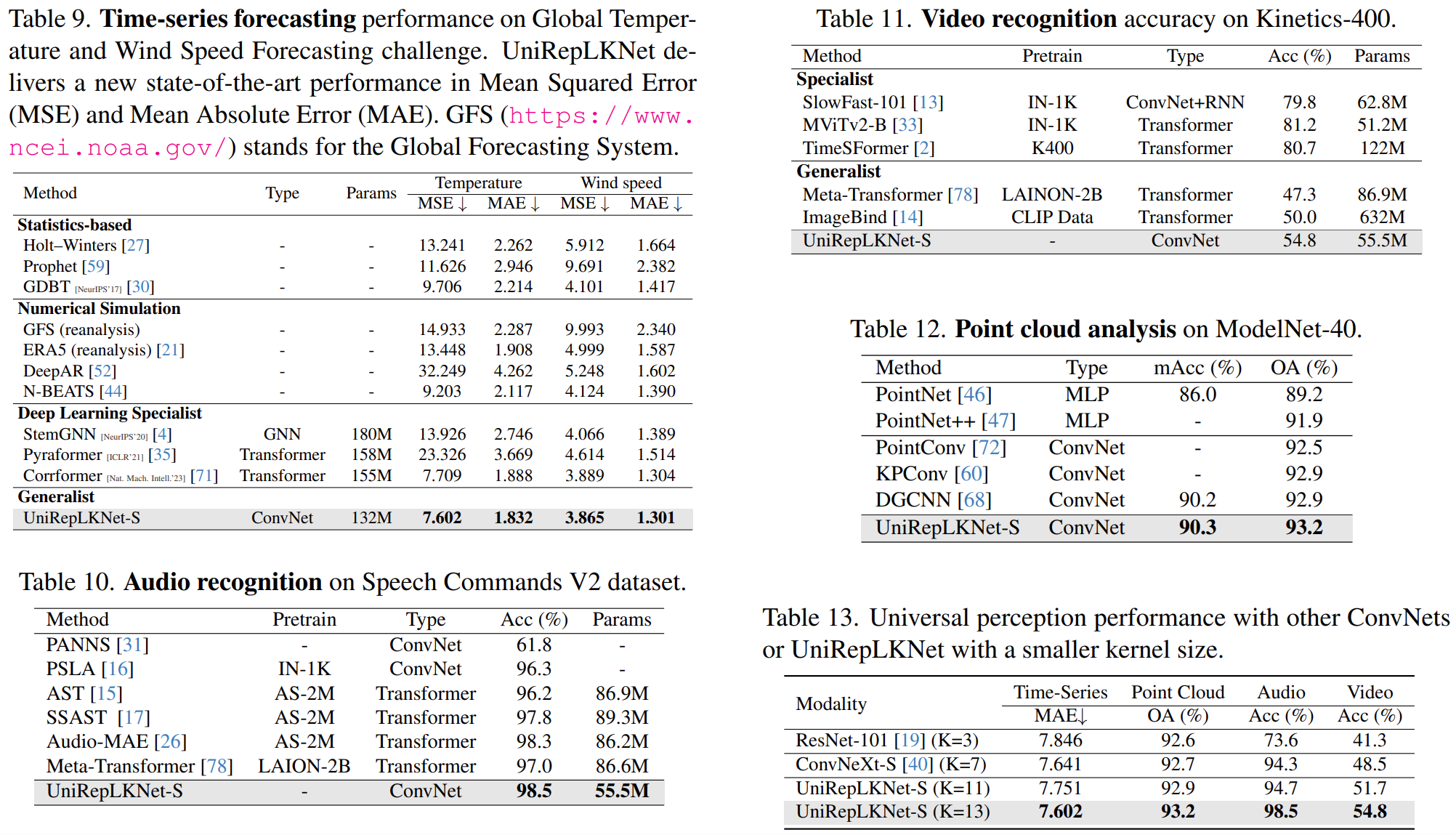
这篇关于论文阅读——UniRepLKNet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)