本文主要是介绍一文看懂所有字符编码标准,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- ASCII
- 128个符号不够用
- 欧洲国家
- 亚洲国家
- GB2312
- GBK
- GB18030
- Unicode
- UTF-8
- QA
- 最高位b7是什么意思?
- UTF-8和UTF-16的区别
- UTF-8和UTF-32的区别
ASCII
ASCII(American Standard Code for Information Interchange)是一种字符编码标准,最初由美国国家标准协会(ANSI)制定,于1963年首次发布。ASCII编码用于将文本字符映射到二进制数值,使得计算机能够理解和处理这些字符。

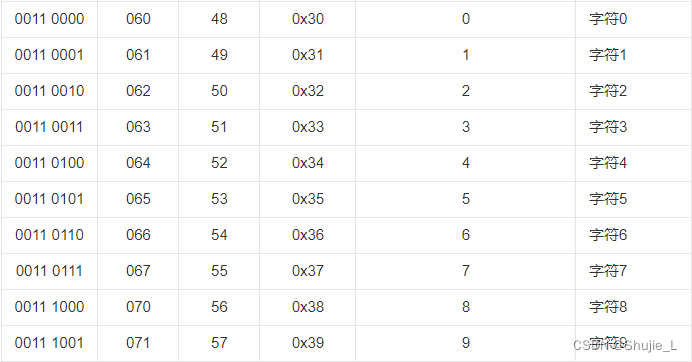
以下是ASCII编码的主要特点:
- 字符范围:
ASCII编码使用7位二进制数(0-127)表示128个字符,包括基本拉丁字母、数字(0-9)、标点符号、控制字符(例如回车、换行)等。
0~31及127(共33个)是控制字符或通信专用字符(其余为可显示字符)
如控制符:LF(换行)、CR(回车)、FF(换页)、DEL(删除)、BS(退格)、BEL(响铃)等;
通信专用字符:SOH(文头)、EOT(文尾)、ACK(确认)等;
32~126(共95个)是字符(32是空格),其中48~57为0到9十个阿拉伯数字。
65~90为26个大写英文字母,97~122号为26个小写英文字母,其余为一些标点符号、运算符号等。
同时还要注意,在标准ASCII中,其最高位(b7)用作奇偶校验位。
所谓奇偶校验,是指在代码传送过程中用来检验是否出现错误的一种方法,一般分奇校验和偶校验两种。
奇校验规定:正确的代码一个字节中1的个数必须是奇数,若非奇数,则在最高位b7添1;
偶校验规定:正确的代码一个字节中1的个数必须是偶数,若非偶数,则在最高位b7添1 。
- 扩展ASCII:
为了满足其他语言和符号的需求,后来提出了扩展ASCII编码,使用8位二进制数(0-255)表示256个字符。这包括了更多的特殊符号、重音符号以及其他语言的字符。
扩展ASCII码
后128个称为扩展ASCII码。许多基于x86的系统都支持使用扩展(或“高”)ASCII。扩展ASCII 码允许将每个字符的第8 位用于确定附加的128 个特殊符号字符、外来语字母和图形符号 。
-
不支持非拉丁字符:
ASCII主要针对英语和基本的拉丁字母,因此不包含用于表示其他语言(如中文、日文、俄文等)的字符。 -
通用性:
由于其简单、广泛支持的特点,ASCII曾经是计算机系统之间交换信息的基本标准。
虽然ASCII编码在早期计算机系统中非常流行,但随着全球化和对非英语字符的需求增加,它变得不够灵活。因此,后来的字符编码标准,如Unicode,提供了更广泛的字符支持,使得各种语言和符号都能够得到合适的表示。
ACII百度百科
128个符号不够用
欧洲国家
在英语中,用128个符号编码便可以表示所有,但是用来表示其他语言,128个符号是不够的。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是,一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的é的编码为130(二进制10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号 。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了é,在希伯来语编码中却代表了字母Gimel (ג),在俄语编码中又会代表另一个符号。但是不管怎样,所有这些编码方式中,0–127表示的符号是一样的,不一样的只是128–255的这一段。
亚洲国家
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 2562 = 65536 个符号
GB2312
GB2312(Guójiā biāozhǔn 2312),也称为GB 2312,是中华人民共和国颁布的第一个汉字字符集标准。该标准发布于1980年,是中国国家标准总局颁布的简体字字符集标准之一。GB2312的主要目的是规范简体字的编码,以促进计算机系统和应用程序之间的字符标准化。
以下是GB2312的一些关键特点:
-
字符范围: GB2312规定了包括6,763个常用汉字和682个其他字符(包括拉丁字母、数字、标点符号等)的字符集。这些字符被组织成94行、94列的表格,每个表格包含一个字符。
-
双字节编码: GB2312采用了双字节编码方案,每个字符用两个字节表示。第一个字节在0xA1到0xF7之间,第二个字节在0xA1到0xFE之间。这种编码方案使得GB2312适用于8位编码系统。
-
编码规则: GB2312编码规则按照字符的位置在表格中的行列来确定。每个字符都有一个唯一的编码,其中第一个字节对应表格的行,第二个字节对应表格的列。
-
简体字标准: GB2312主要关注简体字,是为了解决简体字的字符标准化问题。由于繁体字较多,后来GBK(汉字内码扩展规范)和GB18030等标准被制定来支持更多字符。
尽管GB2312在中国大陆广泛使用,但它的字符集相对较小,不能涵盖所有的汉字字符。随着计算机和通信技术的发展,后续的字符集标准如GBK和GB18030逐渐取代了GB2312,以满足更多字符的需求。
GBK
GBK(Guójiā biāozhǔn kuòzhǎn),也称为GB18030的前身,是中华人民共和国颁布的汉字字符集标准之一。GBK于1995年发布,是GB2312的扩展,旨在支持更多的汉字字符,并加入了一些繁体字字符。
以下是GBK的一些关键特点:
-
字符范围: GBK包含了GB2312的所有字符,以及扩展了约20,000个繁体字和少数民族字符。总体而言,GBK字符集包含了超过87,000个字符。
-
双字节编码: 类似于GB2312,GBK也采用了双字节编码方案,每个字符用两个字节表示。这有助于保持向下兼容性,以便GB2312的文本可以在GBK环境中正确处理。
-
兼容性: GBK在设计上考虑了向下兼容GB2312,即GB2312中的字符在GBK中有相同的表示。这使得原本使用GB2312的应用程序可以逐渐过渡到使用GBK。
-
GB18030: GBK的后续版本是GB18030,它是一个更大的字符集,包含了丰富的字符,支持汉字、日文、韩文、藏文等多种语言。GB18030同时兼容GB2312、GBK和Unicode。
-
应用领域: GBK在中国大陆广泛应用于各种领域,包括操作系统、数据库、办公软件等。它为中文字符的表示提供了标准,尤其是在包含大量繁体字的场景中。
总体而言,GBK是为了扩展GB2312以满足更多字符需求而制定的标准。随着GB18030的出现,GBK逐渐被GB18030取代,后者支持更广泛的字符集,包括了Unicode的一部分。
GB18030
GB18030是中华人民共和国颁布的字符编码标准,是GBK的扩展,旨在支持更广泛的字符集,包括汉字、拉丁字母、日文、韩文等多种语言。GB18030于2005年发布,是中国国家标准总局颁布的一个国家标准。
以下是GB18030的一些关键特点:
-
字符范围: GB18030包含了GB2312和GBK的所有字符,同时还加入了更多的字符,使其成为一个非常庞大的字符集。总体而言,GB18030字符集包含了超过1,000,000个字符。
-
双字节和四字节编码: 类似于GBK,GB18030采用了双字节编码方案,每个字符用两个字节表示。此外,GB18030还引入了四字节编码,以支持更多字符。四字节编码使得GB18030能够表示Unicode字符集中的所有字符。
-
兼容性: GB18030在设计上考虑了向下兼容GBK和GB2312,即这些字符集中的字符在GB18030中有相同的表示。这使得原本使用GBK和GB2312的应用程序可以逐渐过渡到使用GB18030,而无需大规模修改现有的文本和软件资产。
-
多语言支持: GB18030不仅支持汉字,还支持多种语言的字符,包括拉丁字母、日文、韩文等。这使得GB18030成为一个更加通用的字符编码标准。
-
Unicode兼容: GB18030与Unicode的兼容性较好,能够表示Unicode字符集中的大多数字符。GB18030的设计目标之一是与Unicode保持一致,使得在处理不同字符集时更加方便。
GB18030的推出使得中国的计算机系统更好地支持了不同语言和字符,为全球化和多语言信息交流提供了支持。在使用GB18030时,应用程序需要考虑字符的双字节或四字节表示方式,以确保正确处理各种字符。
Unicode
Unicode是一种字符编码标准,旨在统一世界上各种语言和符号的字符表示。它提供了一个唯一的数字码点(code point)来表示每个字符,包括文字、标点符号、数学符号、技术符号以及世界上各种语言的字符。
以下是Unicode的一些关键特点:
-
统一性: Unicode旨在提供一个统一的字符集,覆盖全球范围内的所有书写系统。这包括了几乎所有已知的语言,从基本的拉丁字母到中文、阿拉伯文、希伯来文等。
-
唯一码点: 每个字符在Unicode中都有一个唯一的数字码点,用来标识该字符。这个码点通常用16进制表示,例如,拉丁字母"A"的Unicode码点是U+0041。
-
多字符集支持: Unicode定义了多个字符集,包括UTF-8、UTF-16、UTF-32等。这些字符集用于在计算机系统中以不同的方式表示Unicode字符。
-
向后兼容: Unicode的设计考虑了向后兼容性,以确保新的版本能够与旧版本兼容。这有助于保护现有的文本和软件资产。
-
广泛应用: Unicode在计算机领域中得到了广泛应用,包括操作系统、编程语言、数据库、文本处理软件等。它也是互联网上文本通信的标准。
-
表情符号和特殊符号: Unicode还包括了各种表情符号(emoji)和特殊符号,使其更适用于现代通信和互联网文化。
Unicode的目标是解决字符编码的碎片化问题,使得不同语言和文化的字符能够在计算机系统中得到一致的表示。UTF-8、UTF-16和UTF-32等编码方案是用来在计算机中存储和传输Unicode字符的具体实现。Unicode的普及促进了全球化信息交流,为各种语言和文化的数字化提供了基础。
UTF-8
UTF-8(Unicode Transformation Format-8)是一种变长字符编码方案,用于表示Unicode字符集中的字符。它是Unicode的一种实现方式,具有以下特点:
-
变长编码: UTF-8使用变长编码,即不同的字符可能由不同数量的字节表示。常用的ASCII字符使用一个字节表示,而其他字符可能需要两、三、甚至四个字节。这种设计使得UTF-8在存储和传输文本时能够更灵活地适应不同字符的需求。
-
ASCII兼容: UTF-8是兼容ASCII编码的。ASCII字符集中的字符在UTF-8中有相同的表示,保持了对现有ASCII文本的向后兼容性。这意味着UTF-8编码的文本可以无缝地包含和表示ASCII文本。
-
字节顺序: UTF-8是无字节序的编码方案,因为每个字符都是独立的字节序列。这使得在不同的计算机系统之间更容易地进行文本交换,而无需考虑字节序的问题。
-
Unicode字符表示: UTF-8可以表示Unicode字符集中的所有字符,包括拉丁字母、汉字、表情符号等。这使得UTF-8成为全球性的字符编码标准,广泛用于互联网、操作系统、编程语言等各个领域。
-
空间效率: 对于常用的英文字母和符号,UTF-8使用一个字节表示,与ASCII编码相同。这保持了对ASCII文本的空间效率,而对于其他字符,UTF-8的变长编码方式也能够有效地利用空间。
UTF-8是互联网上最常用的字符编码方式,广泛应用于网页、文本文件、数据库等。它为全球范围内的文本交流提供了一种通用的解决方案,因为它能够表示几乎所有的Unicode字符。
QA
最高位b7是什么意思?
在计算机中,字节是由二进制位(bit)组成的,通常是8位一个字节。对于字节的每个位,我们可以用索引从0到7来表示,其中0是最低位(最右边的位),7是最高位(最左边的位)。
在讨论字节的最高位时,我们通常使用 b7 表示字节的第7位。这个位的值为1或0,取决于具体的上下文和字节的内容。在某些编码方案中,最高位可能用于表示符号、标志或其他信息。
在UTF-8编码中,最高位(b7)通常用于表示多字节字符的起始。UTF-8的编码规则中,以0开头的字节表示单字节字符,而以1开头的字节表示多字节字符的起始字节。因此,最高位为1的字节是多字节字符的开始,而最高位为0的字节是单字节字符或多字节字符的后续字节。
UTF-8和UTF-16的区别
UTF-8和UTF-16都是Unicode编码的实现方式,但它们有一些关键的区别:
-
编码方式:
UTF-8: 使用变长编码,一个字符可能由1到4个字节组成。对于常用的ASCII字符,只需要一个字节;对于其他字符,可能需要多个字节。
UTF-16: 使用固定长度编码,一个字符总是由2个字节或4个字节组成。基本多语言平面(BMP)中的字符使用两个字节,而辅助平面(Supplementary Planes)中的一些字符需要四个字节。 -
对ASCII的处理:
UTF-8: ASCII字符在UTF-8中使用一个字节表示,与ASCII编码兼容。
UTF-16: ASCII字符在UTF-16中使用两个字节表示,因为UTF-16以两个字节为单位进行编码。 -
空间效率:
UTF-8: 对于英文和其他主要使用ASCII字符的文本,UTF-8通常比UTF-16更节省空间,因为ASCII字符只需要一个字节。
UTF-16: 对于包含大量非ASCII字符的文本,UTF-16可能更节省空间,因为大多数字符只需要两个字节。 -
字节顺序:
UTF-8: 是无字节序的编码方案,每个字符都是独立的字节序列。
UTF-16: 可以具有两种字节序:大端序(Big-Endian)和小端序(Little-Endian)。UTF-16文件通常包含一个字节序标记(BOM),以指示使用的字节序。 -
适用范围:
UTF-8: 在互联网上广泛应用,特别适合处理以英文为主的文本和Web文档。
UTF-16: 在一些操作系统、编程语言和应用中使用,特别是在处理包含许多不同语言字符的环境中。
UTF-8适用于多语言文本和互联网传输,而UTF-16适用于需要处理广泛字符集的环境。
UTF-8和UTF-32的区别
UTF-8和UTF-32都是Unicode编码的实现方式,但它们在编码方式和存储上存在一些关键的区别:
-
编码方式:
UTF-8: 使用变长编码,一个字符可能由1到4个字节组成。对于常用的ASCII字符,只需要一个字节;对于其他字符,可能需要多个字节。
UTF-32: 使用固定长度编码,一个字符总是由4个字节组成。 -
对ASCII的处理:
UTF-8: ASCII字符在UTF-8中使用一个字节表示,与ASCII编码兼容。
UTF-32: ASCII字符在UTF-32中仍然使用四个字节表示,因为UTF-32是固定长度编码。 -
空间效率:
UTF-8: 对于英文和其他主要使用ASCII字符的文本,UTF-8通常更节省空间,因为ASCII字符只需要一个字节。
UTF-32: 对于所有字符,UTF-32占用的空间是固定的,每个字符都需要4个字节。这可能导致存储大量文本时浪费空间。 -
字节顺序:
UTF-8: 是无字节序的编码方案,每个字符都是独立的字节序列。
UTF-32: 可以具有两种字节序:大端序(Big-Endian)和小端序(Little-Endian)。UTF-32文件通常包含一个字节序标记(BOM),以指示使用的字节序。 -
适用范围:
UTF-8: 在互联网上广泛应用,特别适合处理以英文为主的文本和Web文档。
UTF-32: 用于处理需要大范围字符集的环境,特别是在内存中直接处理字符时,因为它提供了简单的固定长度编码。
UTF-8适用于多语言文本和互联网传输,而UTF-32适用于需要在内存中快速直接操作字符的情况,但可能会占用更多的空间。
这篇关于一文看懂所有字符编码标准的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





