本文主要是介绍MyDLNote - Attention : Attention U-Net: Learning Where to Look for the Pancreas,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Attention U-Net: Learning Where to Look for the Pancreas
[paper] https://arxiv.org/abs/1804.03999
[pytorch] https://github.com/LeeJunHyun/Image_Segmentation
目录
Attention U-Net: Learning Where to Look for the Pancreas
Abstract
Introduction
1.1 Related Work
1.2 Contributions
Methodology
Fully Convolutional Network (FCN):
Attention Gates for Image Analysis:
Attention Gates in U-Net Model:
Abstract
We propose a novel attention gate (AG) model for medical imaging that automatically learns to focus on target structures of varying shapes and sizes.
做了什么
Models trained with AGs implicitly learn to suppress irrelevant regions in an input image while highlighting salient features useful for a specific task. This enables us to eliminate the necessity of using explicit external tissue/organ localisation modules of cascaded convolutional neural networks (CNNs). AGs can be easily integrated into standard CNN architectures such as the U-Net model with minimal computational overhead while increasing the model sensitivity and prediction accuracy.
AG 的三个优点:
使用AG进行训练的模型隐式学习抑制输入图像中不相关的区域,同时突出显示对特定任务有用的显着特征。
这使我们能够消除使用级联卷积神经网络(CNN)的显式外部组织/器官定位模块的必要性。
AG可以很容易地集成到标准的CNN体系结构中,如U-Net模型,同时提高模型灵敏度和预测精度,同时计算开销最小。
The proposed Attention U-Net architecture is evaluated on two large CT abdominal datasets for multi-class image segmentation. Experimental results show that AGs consistently improve the prediction performance of U-Net across different datasets and training sizes while preserving computational efficiency. The source code for the proposed architecture is publicly available.
实验结果
Introduction
High representation power, fast inference, and filter sharing properties have made CNNs the de facto standard for image segmentation. Fully convolutional networks (FCNs) and the U-Net are two commonly used architectures. Despite their good representational power, these architectures rely on multi-stage cascaded CNNs when the target organs show large inter-patient variation in terms of shape and size. Cascaded frameworks extract a region of interest (ROI) and make dense predictions on that particular ROI.
高表示能力,快速推理和过滤器共享属性使得 CNN 成为图像分割约定俗成的标准。
完全卷积网络(FCNs)和 U-Net 是两种常用的体系结构。尽管它们具有很好的代表性,但是当靶器官在形状和大小方面显示出大的患者间差异时,这些架构依赖于多级级联 CNN。
级联框架提取感兴趣区域(ROI)并对该特定ROI进行密集预测。
However, this approach leads to excessive and redundant use of computational resources and model parameters; for instance, similar low-level features are repeatedly extracted by all models within the cascade. To address this general problem, we propose a simple and yet effective solution, namely attention gates (AGs). CNN models with AGs can be trained from scratch in a standard way similar to the training of a FCN model, and AGs automatically learn to focus on target structures without additional supervision. At test time, these gates generate soft region proposals implicitly on-the-fly and highlight salient features useful for a specific task. Moreover, they do not introduce significant computational overhead and do not require a large number of model parameters as in the case of multi-model frameworks. In return, the proposed AGs improve model sensitivity and accuracy for dense label predictions by suppressing feature activations in irrelevant regions.
但是,这种方法会导致计算资源和模型参数的过度和多余的使用;例如,级联内的所有模型都会重复提取类似的低级特征。为了解决这个普遍问题,我们提出了一个简单而有效的解决方案,即注意门(AG)。
与 AGs 的 CNN 模型可以以类似于 FCN 模型的培训的标准方式从头开始进行培训,并且 AGs 自动学习专注于目标。
在测试时,这些门会即时生成软区域建议,并突出对特定任务有用的突出特性。
此外,它们不会引入大量的计算开销,也不像多模型框架那样需要大量的模型参数。
反过来,提出的AGs通过抑制不相关区域的特征激活,提高了模型对稠密标签预测的敏感性和准确性。
1.1 Related Work
Attention Gates:
Initial work has explored attention-maps by interpreting gradient of output class scores with respect to the input image. Trainable attention, on the other hand, is enforced by design and categorised as hard- and soft-attention.
最初的工作是通过解释输出类分数相对于输入图像的梯度来挖掘注意力图。而可训练的注意力是通过设计来执行的,可分为 Hard 注意力和 Soft 注意力。
Hard attention [Recurrent models of visual attention], e.g. iterative region proposal and cropping, is often non-differentiable and relies on reinforcement learning for parameter updates, which makes model training more difficult.
硬注意(视觉注意的递归模型),例如迭代区域建议和裁剪,通常是不可微的,并且依赖于参数更新的强化学习,这使得模型训练更加困难。
Contrarily, soft attention is probabilistic and utilises standard back-propagation without need for Monte Carlo sampling.
相反,软注意是概率的,使用标准的反向传播,不需要蒙特卡罗抽样。
In [10], channel-wise attention is used to highlight important feature dimensions, which was the top-performer in the ILSVRC 2017 image classification challenge.
在[10]中,使用了通道方向的注意力来突出重要的特征维度,这在ILSVRC 2017图像分类挑战中是表现最好的
Self-attention techniques have been proposed to remove the dependency on external gating information. For instance, non-local self attention is used in [Non-local neural networks] to capture long range dependencies. In [Residual attention network for image classification; Learn to pay attention] self-attention is used to perform class-specific pooling, which results in more accurate and robust image classification performance.
已经有人提出自我注意技术来消除对外部门控信息的依赖。例如,在 [Non-local neural networks] 中使用非本地的自我关注来捕获远程依赖项。在 [Residual attention network for image classification ; Learn to pay attention] 中,使用了 self-attention 来执行 class-specific pooling,这使得图像的分类更加准确和稳健。
1.2 Contributions
In this paper, we propose a novel self-attention gating module that can be utilised in CNN based standard image analysis models for dense label predictions. Moreover, we explore the benefit of AGs to medical image analysis, in particular, in the context of image segmentation. The contributions of this work can be summarised as follows:
在这篇论文中,我们提出了一个新颖的自我注意门控模块,它可以用于基于CNN的标准图像分析模型,用于稠密标签预测。此外,我们探讨了AGs对医学图像分析的好处,特别是在图像分割的背景下。这项工作的贡献可概括如下:
• We take the attention approach proposed in [11] a step further by proposing grid-based gating that allows attention coefficients to be more specific to local regions. This improves performance compared to gating based on a global feature vector. Moreover, our approach can be used for dense predictions since we do not perform adaptive pooling.
我们进一步采用了 [Learn to pay attention] 中提出的注意方法,提出了基于网格的门控,允许注意系数更具体到局部区域。与基于全局特征向量的门控相比,这改善了性能。此外,我们的方法可以用于密集预测,因为我们不执行自适应池。
• We propose one of the first use cases of soft-attention technique in a feed-forward CNN model applied to a medical imaging task. The proposed attention gates can replace hard-attention approaches used in image classification and external organ localisation models in image segmentation frameworks.
我们提出了软注意技术在前馈CNN模型应用于医学成像任务的第一个用例之一。提出的注意门可以替代图像分类中使用的硬注意方法和图像分割框架中使用的外部器官定位模型。
• An extension to the standard U-Net model is proposed to improve model sensitivity to foreground pixels without requiring complicated heuristics. Accuracy improvements over U-Net are experimentally observed to be consistent across different imaging datasets.
对标准U-Net模型进行了扩展,提高了模型对前景像素的敏感性,而不需要复杂的启发式算法。对U-Net的精度改进在不同的成像数据集上被实验观察到是一致的。
Methodology
Fully Convolutional Network (FCN):
Convolutional neural networks (CNNs) outperform traditional approaches in medical image analysis on public benchmark datasets while being an order of magnitude faster than, e.g., graph-cut and multi-atlas segmentation techniques. This is mainly attributed to the fact that
(I) domain specific image features are learnt using stochastic gradient descent (SGD) optimisation,
(II) learnt kernels are shared across all pixels, and
(III) image convolution operations exploit the structural information in medical images well.
在公共基准数据集的医学图像分析中,卷积神经网络(CNNs)的表现优于传统方法,但其速度比图形切割和多地图集分割等技术快一个数量级。这主要是由于
(I) 利用随机梯度下降 (SGD) 优化学习领域特定的图像特征,
(II) 学习的核在所有像素之间共享,
(III) 图像卷积操作能够很好地利用医学图像中的结构信息。
In particular, fully convolutional networks (FCN) such as U-Net, DeepMedic and holistically nested networks have been shown to achieve robust and accurate performance in various tasks including cardiac MR, brain tumours and abdominal CT image segmentation tasks.
特别是,全卷积网络(FCN),如U-Net、DeepMedic和整体嵌套网络,已被证明在各种任务(包括心脏MR、脑肿瘤和腹部CT图像分割任务)中具有稳健和准确的性能。
Convolutional layers progressively extract higher dimensional image representations () by processing local information layer by layer. Eventually, this separates pixels in a high dimensional space according to their semantics.
卷积层通过逐层处理局部信息逐步提取高维图像表示 ()。最后,它根据语义在高维空间中分离像素。
Through this sequential process, model predictions are conditioned on information collected from a large receptive field. Hence, feature-map is obtained at the output of layer
by sequentially applying a linear transformation followed by a non-linear
activation function. It is often chosen as rectified linear unit: where
and
denote spatial and channel dimensions respectively.
通过这个连续的过程,模型预测以从一个大的接受域收集的信息为条件。因此,特征映射 是在层l的输出处
,依次应用线性变换和非线性变换得到的激活功能。常选择作为 rectified 线性单元:
在这里,
和
分别表示空间维度和通道维度 (ReLU)。
Feature activations can be formulated as: where
denotes the convolution operation, and the spatial subscript (
) is omitted in the formulation for notational clarity. The function
applied in convolution layer
is characterised by trainable kernel parameters
. The parameters are learnt by minimising a training objective, e.g. cross-entropy loss, using stochastic gradient descent (SGD).
特征激活可以表示为: 其中
表示卷积运算,为了符号清晰,在公式中省略空间下标 (
)。卷积层
中应用的函数
通过可训练的核参数
表征。这些参数是通过最小化一个训练目标来学习的,例如使用随机梯度下降(SGD)来减少交叉熵损失。
In this paper, we build our attention model on top of a standard U-Net architecture. U-Nets are commonly used for image segmentation tasks because of their good performance and efficient use of GPU memory. The latter advantage is mainly linked to extraction of image features at multiple image scales. Coarse feature-maps capture contextual information and highlight the category and location of foreground objects. Feature-maps extracted at multiple scales are later merged through skip connections to combine coarse- and fine-level dense predictions as shown in Figure 1.
在本文中,我们将注意力模型建立在一个标准的 U-Net 架构之上。由于其良好的性能和对GPU内存的有效利用,U-Nets 通常被用于图像分割任务。后者的优点主要是在多个图像尺度下提取图像特征。粗糙的特征映射捕获上下文信息并突出显示前景对象的类别和位置。在多个尺度上提取的特征图随后通过跳过连接进行合并,以结合粗级和细级的稠密预测,如图1所示。

Figure 1: A block diagram of the proposed Attention U-Net segmentation model. Input image is progressively filtered and downsampled by factor of 2 at each scale in the encoding part of the network (e.g.
). Nc denotes the number of classes. Attention gates (AGs) filter the features propagated through the skip connections. Schematic of the AGs is shown in Figure 2. Feature selectivity in AGs is achieved by use of contextual information (gating) extracted in coarser scales.
Attention Gates for Image Analysis:
To capture a sufficiently large receptive field and thus, semantic contextual information, the feature-map grid is gradually downsampled in standard CNN architectures. In this way, features on the coarse spatial grid level model location and relationship between tissues at global scale. However, it remains difficult to reduce false-positive predictions for small objects that show large shape variability.
Here, we demonstrate that the same objective can be achieved by integrating attention gates (AGs) in a standard CNN model. This does not require the training of multiple models and a large number of extra model parameters. In contrast to the localisation model in multi-stage CNNs, AGs progressively suppress feature responses in irrelevant background regions without the requirement to crop a ROI between networks.
为了捕获足够大的接受域,从而获得语义上下文信息,特征图网格在标准CNN架构中逐渐向下采样。这样,特征在粗网格水平上的模型位置和组织之间的关系在全球范围内。然而,对于表现出大的形状变异性的小物体,仍然很难减少 false-positive 预测。
在这里,我们证明了同样的目标可以通过将注意力门 (AGs) 集成到一个标准的 CNN 模型中来实现。这并不需要训练多个模型和大量额外的模型参数。与多阶段 CNNs 的局部化模型相比,AGs 逐步抑制不相关背景区域的特征响应,不需要在网络间裁剪 ROI。
Attention coefficients, , identify salient image regions and prune feature responses to preserve only the activations relevant to the specific task as shown in Figure 3a. The output of AGs is the element-wise multiplication of input feature-maps and attention coefficients:
. In a default setting, a single scalar attention value is computed for each pixel vector
, where
corresponds to the number of feature-maps in layer
. In case of multiple semantic classes, we propose to learn multi-dimensional attention coefficients. This is inspired by [Disan: Directional self-attention network for rnn/cnn-free language understanding], where multidimensional attention coefficients are used to learn sentence embeddings. Thus, each AG learns to focus on a subset of target structures. As shown in Figure 2, a gating vector
is used for each pixel
to determine focus regions. The gating vector contains contextual information to prune lower-level feature responses, which uses AGs for natural image classification. We use additive attention to obtain the gating coefficient. Although this is computationally more expensive, it has experimentally shown to achieve higher accuracy than multiplicative attention. Additive attention is formulated as follows:
where correspond to sigmoid activation function. AG is characterised by a set of parameters
containing: linear transformations
,
,
and bias terms
,
.
注意系数, , 可以识别显著的图像区域和修剪特征响应,只保留与特定任务相关的激活,如图3a所示。AGs 的输出是输入特征图与注意系数的逐项相乘:
。在默认设置中,计算每个像素向量的单个标量注意值
,
对应于层
中的特征映射的数量。针对多语义类的情况,本文提出了多维注意系数的学习方法。这是受 [Disan: Directional self-attention network for rnn/cnn-free language understanding] 的启发,其中多维注意系数用于学习句子嵌入。这样,每个 AG 学会关注目标结构的子集。如图 2 所示,每个像素
使用一个门控向量
来确定聚焦区域。门控向量包含上下文信息来修剪较低层次的特征响应,它使用 AGs 进行自然图像分类。我们使用加法注意来获得门系数。虽然这是计算上更昂贵,但实验表明,它比乘法注意的精度更高。附加注意的表述如下:
其中 对应 sigmoid 激活函数。AG 通过一组参数
表征,包括:线性变换
,
,
和偏置项
,
。

Figure 2: Schematic of the proposed additive attention gate (AG). Input features (
) are scaled with attention coefficients (
) computed in AG. Spatial regions are selected by analysing both the activations and contextual information provided by the gating signal (
) which is collected from a coarser scale. Grid resampling of attention coefficients is done using trilinear interpolation.
The linear transformations are computed using channel-wise 1x1x1 convolutions for the input tensors. In other contexts, this is referred to as vector concatenation-based attention, where the concatenated features and
are linearly mapped to a
dimensional intermediate space. Sequential use of softmax yields sparser activations at the output. For this reason, we choose a sigmoid activation function. This results experimentally in better training convergence for the AG parameters. In contrast to [Learn to pay attention] we propose a grid-attention technique.
In this case, gating signal is not a global single vector for all image pixels but a grid signal conditioned to image spatial information.
More importantly, the gating signal for each skip connection aggregates information from multiple imaging scales, as shown in Figure 1, which increases the grid-resolution of the query signal and achieve better performance.
Lastly, we would like to note that AG parameters can be trained with the standard back-propagation updates without a need for sampling based update methods used in hard-attention.
对输入张量使用沿通道的1x1x1卷积来计算线性变换。在其他上下文中,这被称为基于向量连接的注意,其中连接的特征 和
被线性映射到一个维度的中间空间。连续使用softmax会在输出时产生较少的激活。为此,我们选择了一个sigmoid激活函数。实验结果表明,该算法具有较好的收敛性。与 [Learn to pay attention] 相比,我们提出了一种网格注意技术。
在这种情况下,门控信号不是针对所有图像像素的全局单个向量,而是针对图像空间信息的网格信号。
更重要的是,每个跳过连接的门控信号都聚合了来自多个成像尺度的信息,如图1所示,这增加了查询信号的网格分辨率,并实现了更好的性能。
最后,我们想指出的是,AG参数可以通过标准的反向传播更新进行训练,而不像 hard-attention 需要使用基于抽样的更新方法。
Attention Gates in U-Net Model:
The proposed AGs are incorporated into the standard U-Net architecture to highlight salient features that are passed through the skip connections, see Figure 1. Information extracted from coarse scale is used in gating to disambiguate irrelevant and noisy responses in skip connections. This is performed right before the concatenation operation to merge only relevant activations. Additionally, AGs filter the neuron activations during the forward pass as well as during the backward pass. Gradients originating from background regions are down weighted during the backward pass. This allows model parameters in shallower layers to be updated mostly based on spatial regions that are relevant to a given task.
建议的AGs被合并到标准U-Net体系结构中,以突出通过跳过连接传递的突出特性,参见图1。从粗尺度中提取的信息用于门控,以消除跳过连接中不相关和有噪声的响应的歧义。这是在连接操作之前执行的,以便只合并相关的激活。此外,AGs过滤前向和后向传递过程中的神经元激活。来自背景区域的梯度在向后传递时向下加权。这使得浅层中的模型参数可以根据与给定任务相关的空间区域进行更新。
The update rule for convolution parameters in layer can be formulated as follows:
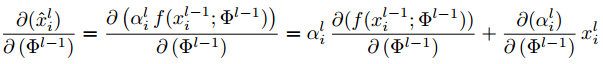
The first gradient term on the right-hand side is scaled with . In case of multi-dimensional AGs,
corresponds to a vector at each grid scale. In each sub-AG, complementary information is extracted and fused to define the output of skip connection. To reduce the number of trainable parameters and computational complexity of AGs, the linear transformations are performed without any spatial support (1x1x1 convolutions) and input feature-maps are downsampled to the resolution of gating signal, similar to non-local blocks. The corresponding linear transformations decouple the feature-maps and map them to lower dimensional space for the gating operation. As suggested in [Learn to pay attention], low-level feature-maps, i.e. the first skip connections, are not used in the gating function since they do not represent the input data in a high dimensional space. We use deep-supervision to force the intermediate feature-maps to be semantically discriminative at each image scale. This helps to ensure that attention units, at different scales, have an ability to influence the responses to a large range of image foreground content. We therefore prevent dense predictions from being reconstructed from small subsets of skip connections.
层中卷积参数的更新规则如下:
右边的第一个梯度项乘以 。对于多维的AGs,
对应于每个网格尺度上的一个向量。在每个子ag中,提取并融合互补信息来定义跳跃连接的输出。为了减少可训练参数的数量和AGs的计算复杂度,在不需要任何空间支持(1x1x1卷积)的情况下进行线性变换,将输入特征映射向下采样到门控信号的分辨率,类似于非局部块。相应的线性变换将特征映射解耦,并将它们映射到更低的空间来进行门控操作。正如[11]中所建议的,门控函数中没有使用低级特征映射,即第一个跳过连接,因为它们不代表高维空间中的输入数据。我们使用深度监督[16]来强制中间特征映射在每个图像尺度上具有语义区别。这有助于确保不同尺度的注意力单元能够影响对大量前景图像内容的响应。因此,我们可以防止从跳跃连接的小子集重构密集预测。
这篇关于MyDLNote - Attention : Attention U-Net: Learning Where to Look for the Pancreas的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






