本文主要是介绍笔记:Attention U-Net:Learning Where to Look for the Pancreas,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文:https://arxiv.org/pdf/1804.03999.pdf
引用:https://bbs.cvmart.net/articles/3258
提出了一种新的attention gate(AG)模型的医学成像自动学习聚焦在不同形状和大小的目标结构。经过AGs训练的模型隐式学习抑制输入图像中的无关区域,同时突出对特定任务有用的显著特征。
这使我们能够消除使用级联卷积神经网络(CNNs)的显式外部组织/器官定位模块的必要性。
AGs可以很容易地集成到标准的CNN架构中,如U-Net模型,以最小的计算开销,同时提高模型的灵敏度和预测精度。
提出的Attention U-Net架构在两个大型CT腹部数据集上进行了评价,用于多类图像分割。
实验结果表明,AGs在保持计算效率的同时,不断提高U-Net在不同数据集和训练规模上的预测性能。
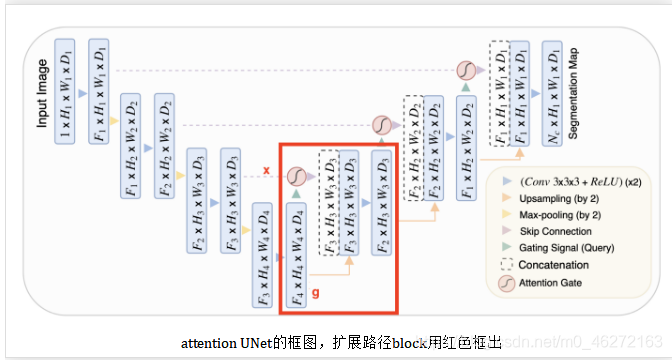
在本文中,我们在一个标准的U-Net架构之上建立了我们的注意力模型。
U-Nets由于其良好的性能和对GPU内存的有效利用而被广泛用于图像分割任务。
后者的优势主要与图像多尺度特征提取有关。
粗糙的特征地图捕获上下文信息,并突出前景对象的类别和位置。
多尺度提取的特征图通过跳跃连接进行合并,将粗层次和细层次的密集预测结合起来,如图1所示。
把来自前一个block的输入称为g,以及来自扩展路径的skip链接称为x。下面的式子描述了这个模块是如何工作的。

upsample块非常简单,而ConvBlock只是由两个(convolution + batch norm + ReLU)块组成的序列。唯一需要解释的是注意力。
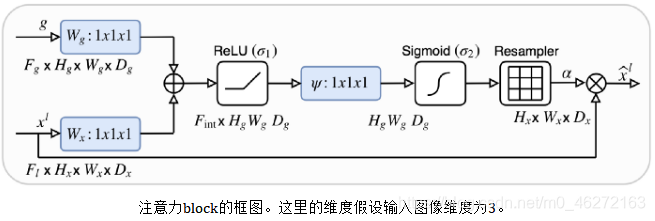
- _x_和_g_都被送入到1x1卷积中,将它们变为相同数量的通道数,而不改变大小
- 在上采样操作后(有相同的大小),他们被累加并通过ReLU
- 通过另一个1x1的卷积和一个sigmoid,得到一个0到1的重要性分数,分配给特征图的每个部分
- 然后用这个注意力图乘以skip输入,产生这个注意力块的最终输出
在UNet中,可将收缩路径视为编码器,而将扩展路径视为解码器。UNet的有趣之处在于,跳跃连接允许在解码器期间直接使用由编码器提取的特征。这样,在“重建”图像的掩模时,网络就学会了使用这些特征,因为收缩路径的特征与扩展路径的特征是连接在一起的。在此连接之前应用一个注意力块,可以让网络对跳转连接相关的特征施加更多的权重。它允许直接连接专注于输入的特定部分,而不是输入每个特征。将注意力分布乘上跳转连接特征图,只保留重要的部分。这种注意力分布是从所谓的query(输入)和value(跳跃连接)中提取出来的。注意力操作允许有选择地选择包含在值中的信息。此选择基于query。总结:输入和跳跃连接用于决定要关注跳跃连接的哪些部分。然后,我们使用skip连接的这个子集,以及标准展开路径中的输入。
class Attention_block(nn.Module):"""Attention Block"""def __init__(self, F_g, F_l, F_int):super(Attention_block, self).__init__()self.W_g = nn.Sequential(nn.Conv2d(F_l, F_int, kernel_size=1, stride=1, padding=0, bias=True),nn.BatchNorm2d(F_int))self.W_x = nn.Sequential(nn.Conv2d(F_g, F_int, kernel_size=1, stride=1, padding=0, bias=True),nn.BatchNorm2d(F_int))self.psi = nn.Sequential(nn.Conv2d(F_int, 1, kernel_size=1, stride=1, padding=0, bias=True),nn.BatchNorm2d(1),nn.Sigmoid())self.relu = nn.ReLU(inplace=True)def forward(self, g, x):g1 = self.W_g(g)x1 = self.W_x(x)psi = self.relu(g1 + x1)psi = self.psi(psi)out = x * psireturn out
class AttU_Net(nn.Module):"""Attention Unet implementationPaper: https://arxiv.org/abs/1804.03999"""def __init__(self, img_ch=3, output_ch=1):super(AttU_Net, self).__init__()n1 = 64filters = [n1, n1 * 2, n1 * 4, n1 * 8, n1 * 16]self.Maxpool1 = nn.MaxPool2d(kernel_size=2, stride=2)self.Maxpool2 = nn.MaxPool2d(kernel_size=2, stride=2)self.Maxpool3 = nn.MaxPool2d(kernel_size=2, stride=2)self.Maxpool4 = nn.MaxPool2d(kernel_size=2, stride=2)self.Conv1 = conv_block(img_ch, filters[0])self.Conv2 = conv_block(filters[0], filters[1])self.Conv3 = conv_block(filters[1], filters[2])self.Conv4 = conv_block(filters[2], filters[3])self.Conv5 = conv_block(filters[3], filters[4])self.Up5 = up_conv(filters[4], filters[3])self.Att5 = Attention_block(F_g=filters[3], F_l=filters[3], F_int=filters[2])self.Up_conv5 = conv_block(filters[4], filters[3])self.Up4 = up_conv(filters[3], filters[2])self.Att4 = Attention_block(F_g=filters[2], F_l=filters[2], F_int=filters[1])self.Up_conv4 = conv_block(filters[3], filters[2])self.Up3 = up_conv(filters[2], filters[1])self.Att3 = Attention_block(F_g=filters[1], F_l=filters[1], F_int=filters[0])self.Up_conv3 = conv_block(filters[2], filters[1])self.Up2 = up_conv(filters[1], filters[0])self.Att2 = Attention_block(F_g=filters[0], F_l=filters[0], F_int=32)self.Up_conv2 = conv_block(filters[1], filters[0])self.Conv = nn.Conv2d(filters[0], output_ch, kernel_size=1, stride=1, padding=0)#self.active = torch.nn.Sigmoid()def forward(self, x):e1 = self.Conv1(x)e2 = self.Maxpool1(e1)e2 = self.Conv2(e2)e3 = self.Maxpool2(e2)e3 = self.Conv3(e3)e4 = self.Maxpool3(e3)e4 = self.Conv4(e4)e5 = self.Maxpool4(e4)e5 = self.Conv5(e5)#print(x5.shape)d5 = self.Up5(e5)#print(d5.shape)x4 = self.Att5(g=d5, x=e4)d5 = torch.cat((x4, d5), dim=1)d5 = self.Up_conv5(d5)d4 = self.Up4(d5)x3 = self.Att4(g=d4, x=e3)d4 = torch.cat((x3, d4), dim=1)d4 = self.Up_conv4(d4)d3 = self.Up3(d4)x2 = self.Att3(g=d3, x=e2)d3 = torch.cat((x2, d3), dim=1)d3 = self.Up_conv3(d3)d2 = self.Up2(d3)x1 = self.Att2(g=d2, x=e1)d2 = torch.cat((x1, d2), dim=1)d2 = self.Up_conv2(d2)out = self.Conv(d2)# out = self.active(out)return out这篇关于笔记:Attention U-Net:Learning Where to Look for the Pancreas的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





