本文主要是介绍论文阅读——Attention U-Net: Learning Where to Look for the Pancreas,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文阅读之Attention UNet
将注意力机制引入到UNet辅助进行医学图像分割
摘要
本文创新之处在于提出了Attention Gate注意门用于学习不同形状/大小的目标。通过注意门可以有选择性的学习输入图像中相互关联的区域,抑制不相关区域的显著性,这就避免在网络搭建过程中引入额外人为的监督。
另一方面注意门(AGs)可以作为一种即插即用的模块引入各种网络(如UNet)从而提升模型的敏感度和精度。
本文将Attention UNet在两个大型的腹腔CT数据集上进行了多类别分割测试。
# Section I Introduction
由于对医学图像进行手动标注等十分费时费力,因此自动化的医学图像分割一直是医学图像分析领域的热门研究内容。
在医学图像分割领域,FCN和UNet是两大主流框架;除此之外基于级联的网络也有研究人员深入研究,但容易造成冗余,十分消耗算力。
因此本文提出了基于注意门(AGs)的Attention UNet用来自主学习图像显著性特征,在测试时AGs会隐式生成一些推荐区域,高亮出显著性区域,除此之外AG的引入并没有额外增加太多的计算成本。
AG通过抑制不相关区域的激活值从而提升模型的敏感度和精度,这种注意力机制常见于NLP、自适应的特征聚类等。
本文将AG引入UNet网络用于腹部胰腺CT图像的分割。
# Section II Related work
Attention Gates:主要用于NLP、机器翻译、图像分类等领域。注意力机制可分为两类:硬注意力和软注意力。
Hard Attention:借助于迭代推荐区域,不断裁剪
Soft Attention:基于概率统计,利用反向传播完成,无需蒙特克罗采样。比如像SE-Net中的channel-wise attention以及self-attention mechanism.
本文的工作总结如下:
本文提出了基于自注意力门的Attention UNet用于完成分割网络的密集预测任务。
(1)通过设定注意力系数可以更加关注与局部区域
(2)本文首次实现了将软注意力机制应用到前馈卷积神经网络中用于医学图像分析任务,可用于替代硬注意力用于图像分类、器官定位等任务
(3)这种自注意力门有效地扩展了UNet系列架构,进一步提升了UNet的分割精度。
# Section III Methodology
FCN
FCN
卷积神经网络通过提取高维图像表征从而可以将每一个像素点按照其语义特征进行分类。
主要得益于:
(1)使用SGD随机梯度下降优化方法来学习图像特征
(2)filter的权值在所有像素点均是共享的
(3)卷积运算可以很好的学习医学图像的结构信息
一些经典框架如FCN,UNet,DeepMedic在医学图像分析任务(心室分割、脑肿瘤分割、腹部CT等)都取得了较好的性能及鲁棒性。
卷积层通过逐层处理局部信息提取逐渐高维的特征表述,通过高维语义特征完成像素点的分类任务。在这一连续过程中,网络通过从一定感受野提取到的特征完成预测,每一层输入会经过线性变换+非线性激活获得每一层的输出。随后通过交叉熵损失、SGD等优化损失函数进行学习。
Attention Gates:
在标准CNN网络中为了获得各种感受野不同层次的特征,每一层的采样网格逐渐减少,这样就可以提取从细粒度的空间特征到粗粒度的语义特征。但由于一些较小物体形状差异等使得假阳性分类错误率居高不下,为了解决这一问题,一些现有的框架依赖于额外的模型定位出特定位置有选择的进行分割,本文通过Attention Gate实现同样的功能。
AG会逐层抑制不相关背景区域的响应,而无需裁剪出ROI区域。
在AG中的关键参数是注意力系数alpha,它会识别出图像的显著区域,只保留对分割任务有用的特征响应。
即AG的输出是输入特征和注意力系数做element-wise multiplication的结果。
门控向量可以认为包含了上下文的语义信息,通过gating vector门控向量决定每个像素的重要程度,从而定位出施加注意力的区域,抑制不相关区域的特征响应。
具体计算如下:
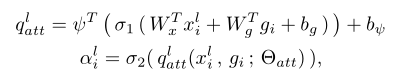
首先输入经过1x1conv线性变换转换到特定维度,完成X与G在每一点的相加,随后经过激活函数得到激活值,激活值再变换为标量经过sigmoid激活得到最终响应值。
为什么用sigmoid而不用softmax?是为了训练时有更好的收敛性,而softmax输出一般比较稀疏。
运算后得到的是每一层基于空间的注意力结果而不是全局的注意力图谱,因此AG使用在skip connection级联前用于聚合多尺度特征信息的。

AGs in UNet:
接下来讲如何在UNet中引入AG:在级联前使用AG,因此将skip connection中不相关信息以及噪声的激活响应抑制,只凸显相关信息的激活值。
而第一层skip connection中也没有使用AG,因为这一层并不表示高维信息的输入,在中间层做skip connection时使用AG,这样确保不同尺度的注意力单元能够借助更大范围内的相关性信息,而不仅仅依赖于局部信息进行密集预测。

Section IV Experiments
AG的好处就是可以移植到任意网络中进行应用,本文将AG用于UNet提出Attention UNet网络,用于腹部胰腺CT图像分割任务。这一任务的特殊之处在于,由于胰腺位置、形状的多变性使得边缘难以准确刻画。
Dataset:CT-150包含150张胃癌患者的腹部CT扫描图像;CT-82包含82张经对比度增强后的3D CT扫描图像
实验细节:
optimizer:Adam
data-agmentation:filp,random crop
分割结果:可视化了不同epoch中的attention map,详情见Fig4,可以看到最初对大部分区域施加一样的注意力,但随着训练的进行,注意力逐渐聚焦于更加精细的局部区域。
最终的分割性能对比见Table1-3.


 Section V Conclusion
Section V Conclusion
本文将自注意力模块用于医学图像分割,避免使用额外的网络辅助定位物体进行分割。而且对不同尺寸的组织、器官的定位能力都很出色未来还将探索更细粒度的输入,减少额外启发信息的加入。
这篇关于论文阅读——Attention U-Net: Learning Where to Look for the Pancreas的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







