本文主要是介绍[论文阅读]Attention U-Net: Learning Where to Look for the Pancreas,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Attention Gate for Image Analysis
粗粒度的特征映射可以捕获上下文信息,突出显示前景对象的类别和位置
UNet:在多个尺度上提取的特征图随后通过跳过连接进行合并,以结合粗和细级别的密集预测
标准CNN通过不断堆叠卷积层和池化层,使得特征图捕获足够大的感受野和语义上下文信息,然而,仍然难以减少对于形状变化较大的小物体的假阳性预测, 为了提高准确性,当前的分割框架依赖于额外的先前对象定位模型,以将任务简化为单独的定位和后续分割步骤。我们证明了在一个标准的CNN模型中集成注意力门(AGs)可以达到同样的目标。这并不需要训练多个模型和大量额外的模型参数。与多阶段CNNs的局部化模型相比,AGs逐步抑制无关背景区域的特征响应,不需要在网络间裁剪ROI。
AG(additive attention gate)示意图

Attention coefficients 识别突出的图像区域并删除特征响应,只保留与特定任务相关的激活
计算原理:
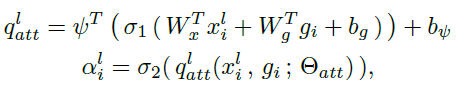
输入: :编码器第l层第i个空间位置对应的特征向量,
:与编码器第l层对应的解码器上采样特征图第i个空间位置对应的特征向量
AG的参数:
![]()
![]()
对和
每一个空间位置向量进行线性变换后得到长度相等的向量进行元素加,再送入
激活函数进行非线性变换得到响应值向量,响应值向量再进行线性变换为标量,之后再送入
激活函数得到标量响应值。
具体实现:1*1*1的same卷积
:Conv3d(F_l,Fint,kernel_size=1,stride=1,padding=0,bias=True)
:Conv3d(F_g,Fint,kernel_size=1,stride=1,padding=0,bias=True)
:Conv3d(F_int,1,kernel_size=1,stride=1,padding=0,bias=True)
2D源码:
class Attention_block(nn.Module):def __init__(self,F_g,F_l,F_int):super(Attention_block,self).__init__()self.W_g = nn.Sequential(nn.Conv2d(F_g, F_int, kernel_size=1,stride=1,padding=0,bias=True),nn.BatchNorm2d(F_int))self.W_x = nn.Sequential(nn.Conv2d(F_l, F_int, kernel_size=1,stride=1,padding=0,bias=True),nn.BatchNorm2d(F_int))self.psi = nn.Sequential(nn.Conv2d(F_int, 1, kernel_size=1,stride=1,padding=0,bias=True),nn.BatchNorm2d(1),nn.Sigmoid())self.relu = nn.ReLU(inplace=True)def forward(self,g,x):g1 = self.W_g(g)x1 = self.W_x(x)psi = self.relu(g1+x1)psi = self.psi(psi)return x*psiclass U_Net(nn.Module):def __init__(self,img_ch=3,output_ch=1):super(U_Net,self).__init__()self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2)self.Conv1 = conv_block(ch_in=img_ch,ch_out=64)self.Conv2 = conv_block(ch_in=64,ch_out=128)self.Conv3 = conv_block(ch_in=128,ch_out=256)self.Conv4 = conv_block(ch_in=256,ch_out=512)self.Conv5 = conv_block(ch_in=512,ch_out=1024)self.Up5 = up_conv(ch_in=1024,ch_out=512)self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)self.Up4 = up_conv(ch_in=512,ch_out=256)self.Up_conv4 = conv_block(ch_in=512, ch_out=256)self.Up3 = up_conv(ch_in=256,ch_out=128)self.Up_conv3 = conv_block(ch_in=256, ch_out=128)self.Up2 = up_conv(ch_in=128,ch_out=64)self.Up_conv2 = conv_block(ch_in=128, ch_out=64)self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0)def forward(self,x):# encoding pathx1 = self.Conv1(x)x2 = self.Maxpool(x1)x2 = self.Conv2(x2)x3 = self.Maxpool(x2)x3 = self.Conv3(x3)x4 = self.Maxpool(x3)x4 = self.Conv4(x4)x5 = self.Maxpool(x4)x5 = self.Conv5(x5)# decoding + concat pathd5 = self.Up5(x5)d5 = torch.cat((x4,d5),dim=1)d5 = self.Up_conv5(d5)d4 = self.Up4(d5)d4 = torch.cat((x3,d4),dim=1)d4 = self.Up_conv4(d4)d3 = self.Up3(d4)d3 = torch.cat((x2,d3),dim=1)d3 = self.Up_conv3(d3)d2 = self.Up2(d3)d2 = torch.cat((x1,d2),dim=1)d2 = self.Up_conv2(d2)d1 = self.Conv_1x1(d2)return d1提出的AG被合并到标准U-Net架构中,从粗略提取的信息用于门控以消除不相关和嘈杂的歧义在跳过连接中的响应,以突出通过跳过连接传递的显着特征。
在对 encoder 每个分辨率上的特征与 decoder 中对应特征进行拼接之前,使用了一个AGs,重新调整了encoder的输出特征。该模块生成一个门控信号,用来控制不同空间位置处特征的重要性。
门控信号g不是用于所有图像像素的全局单个矢量,而是用于图像空间信息的网格信号。 更重要的是,每个跳跃连接的门控信号聚合来自多个成像尺度的信息

这篇关于[论文阅读]Attention U-Net: Learning Where to Look for the Pancreas的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







