本文主要是介绍关于Python里xlwings库对Excel表格的操作(十八),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
这篇小笔记主要记录如何【设置单元格数据的对齐方式】。
前面的小笔记已整理成目录,可点链接去目录寻找所需更方便。
【目录部分内容如下】【点击此处可进入目录】
(1)如何安装导入xlwings库;
(2)如何在Wps下使用xlwings中使用WPS对表格操作;
(3)如何安装导入xlwings库、如何用xlwings打开要操作的Excel表格;
(4)如何使用xlwings对Excel表格数据进行读取操作;
(5)如何使用xlwings对Excel表格进行“保存”或“另存为”操作;
(6) 如何使用xlwings对Excel表格进行写入数据操作;
(7)如何使用xlwings向Excel表格中写入Excel公式;
(8)如何使用xlwings库中的“name"函数和“replace”函数对工作表进行改名;
。。。。。。等等
【行列合并单元格的方式】
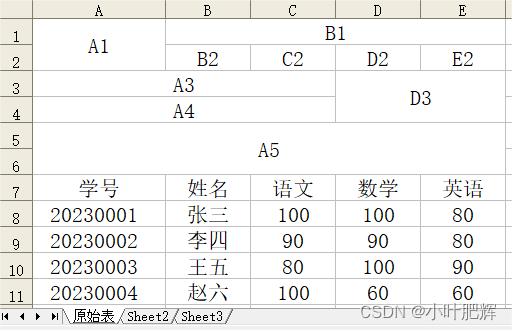
(1)Work_Sheet.range('A1:A2').merge()
#Work_Sheet是指当前激活的工作表;
#用“range”函数中的“.merge”方法合并单元格“A1:A2”区域,无指定合并方向则按单元格走向合并,这里是按列合并第A列第1、2行的两单元格;因为从单元格“A1”开始至“A2”,所以合并后的单元格位置名称也为“A1”且包含原“A1”数据,当然原来的“A2”及其数据都不存在了,下一个直接是“A3”;
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并。因此,上述语句与“Work_Sheet.range('A1:A2').merge(across=False)”结果一样
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格。
(2)Work_Sheet.range('B1:E1').merge()
#Work_Sheet是指当前激活的工作表;
#用“range”函数中的“.merge”方法合并单元格“B1:E1”区域,无指定合并方向则按单元格走向合并,这里是按行合并第1行的第B至E列的单元格;因为从单元格“B1”开始至“E1”,所以合并后的单元格位置名称也为“B1”且包含原“B1”数据,当然原来的“C1至E1”及其数据都不存在了,下一个直接是“F1”;
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并。因此,上述语句与“Work_Sheet.range('B1:E1').merge(across=True)”结果一样
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格。
【区域合并单元格的方式】
(3)Work_Sheet.range('A3:C4').merge(across=True)
#用“range”函数中的“.merge”方法合并单元格“A3:C4”区域,这里指定按行,所以合并后有第3、4两行,且这两行位置名称分别为“A3”和“A4”;
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并,
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格。
(4)Work_Sheet.range('D3:E4').merge(across=False)
#用“range”函数中的“.merge”方法合并单元格“D3:E4”区域,这里只能合并为一个大矩形单元格位置名称为“D3”
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并,
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格。
(5)Work_Sheet.range('A5:E6').merge()
#用“range”函数中的“.merge”方法合并单元格“A5:E6”区域,这里只能合并为一个大矩形单元格位置名称为“A5”
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并,
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格。
【用例子说说更直观】
'''
【合并单元格行、列、区域】
一、合并单元格的行:用“range”函数中的“.merge(across=True)”参数(方法)合并单元格的行;
二、合并单元格的列:用“range”函数中的“.merge(across=False)”参数(方法)合并单元格的列;
最后保存操作。
'''
import xlwings as xw
app=xw.App(visible=False,add_book=False)
app.display_alerts=False #关闭各种提示信息,可以提高运行速度
File_Name='E:/素材/学生成绩表.xls'
#打开要处理的Excel文件名
Work_Book=app.books.open(File_Name)
#打开要处理的Excel文件中的工作簿
Work_Sheet=Work_Book.sheets[0]
#打开要处理的Excel工作簿中的工作表;
#“[0]”是指定打开最靠前的第1份工作表,也可以把“0”写成要打开的指定要打开的“工作表的名称”;
#现在只打开这一个工作表也相当于激活这工作表,后面没有打开激活另一工作表,则所有操作只对现这工作表起作用。Work_Sheet.range('A1:A2').merge()
#用“range”函数中的“.merge”方法合并单元格“A1:A2”区域,无指定合并方向则按单元格走向合并,这里是按列合并第A列第1、2行的两单元格;
#因为从单元格“A1”开始至“A2”,所以合并后的单元格位置名称也为“A1”且包含原“A1”数据,当然原来的“A2”及其数据都不存在了,下一个直接是“A3”;
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并;
#因此,上述语句与“Work_Sheet.range('A1:A2').merge(across=False)”结果一样
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。
#<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格
Work_Sheet.range('B1:E1').merge()
#用“range”函数中的“.merge”方法合并单元格“B1:E1”区域,无指定合并方向则按单元格走向合并,这里是按行合并第1行的第B至E列的单元格;
#因为从单元格“B1”开始至“E1”,所以合并后的单元格位置名称也为“B1”且包含原“B1”数据,当然原来的“C1至E1”及其数据都不存在了,下一个直接是“F1”;
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并;
#因此,上述语句与“Work_Sheet.range('B1:E1').merge(across=True)”结果一样
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。
#<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格
Work_Sheet.range('A3:C4').merge(across=True)
#用“range”函数中的“.merge”方法合并单元格“A3:C4”区域,这里指定按行,所以合并后有第3、4两行,且这两行位置名称分别为“A3”和“A4”;
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并,
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。
#<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格
Work_Sheet.range('D3:E4').merge(across=False)
#用“range”函数中的“.merge”方法合并单元格“D3:E4”区域,这里只能合并为一个大矩形单元格位置名称为“D3”
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并,
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。
#<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格
Work_Sheet.range('A5:E6').merge()
#用“range”函数中的“.merge”方法合并单元格“A5:E6”区域,这里只能合并为一个大矩形单元格位置名称为“A5”
#“merge”有个参数“across”是设置方式,“across=True”按行合并(这也是默认值),“across=False”是按列合并,
#注意:<1>在合并单元格之前,请确保所选范围内没有数据,否则这些数据可能会被删除或移位。
#<2>既跨行又跨列的合并区域只有按行合并或大区域合并两种方式,若没有指定按行合并(即“across=True”)或指定为按列合并(即“across=False”),都并为(行X列)一个大矩形的单元格Work_Book.save()
#保存改动的工作簿。若无保存,则上述操作会随着工作簿的关闭而作废不保存。
Work_Book.close()
#关闭工作簿。
app.quit()
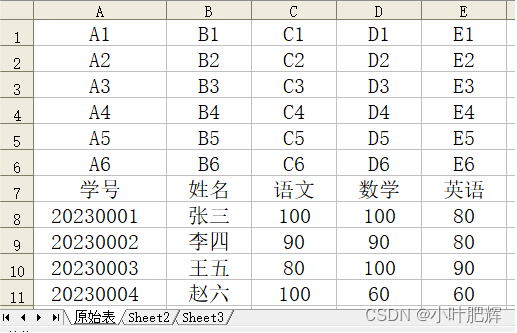
#退出Office软件,不驻留后台。【运行前的表格】
【运行后的表格】
这篇关于关于Python里xlwings库对Excel表格的操作(十八)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






