本文主要是介绍SQL实践篇(一):使用WebSQL在H5中存储一个本地数据库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 简介
- 本地存储都有哪些?
- 如何使用WebSQL
- 打开数据库
- 事务操作
- SQL执行
- 在浏览器端做一个英雄的查询页面
- 如何删除本地存储
- 参考文献
简介
WebSQL是一种操作本地数据库的网页API接口,通过它,我们可以操作客户端的本地存储。
WebSQL曾经是H5里很重要的一种技术,但是后来被废弃了,有的浏览器可能仍旧可以正常使用,但是已经不推荐了,而且大多数浏览器,如Chrome,已经直接禁用了WebSQL了,目前流行的替代品,应该是IndexedDB。
所以本节就是兴趣了解下就行。
主要包括以下内容:
- 本地存储都有哪些?什么是WebSQL?
- 使用WebSQL的三个核心方法是什么?
- 使用WebSQL在本地浏览器里创建一个数据库,并对其进行查询和呈现。
本地存储都有哪些?
本地存储是一个很大的概念,其包括了Cookies、Local Storage、Session Storage、WebSQL、IndexedDB。
Cookies是最早的本地存储,是浏览器端提供,并且对服务器和JS开放,不过可以存储的数据总量只有4KB,如果超过了这个限制就会忽略,没法进行保存,所以一般用来记录一些登陆有关的信息之类的。
Local Storage与Session Storage都属于Web Storage。Web Storage跟Cookies类似,区别在于它有更大容量的存储。Local Storage是持久化的本地存储,除非我们主动删除数据,否则会一直保存在本地。Session Storage只存在于Session会话中,就是说只有在同一个Session页面才能使用。当Session会话结束时,数据也会自动释放。
Web SQL与IndexedDB都是最新的HTML5本地缓存技术,相比前面三种来说,其存储功能更强,支持的数据类型也更多,比如说图片、视频等。
Web SQL,准确的说是Web SQL DB API,它其实是一种操作客户端本地数据库的一类API接口,通过它我们可以很方便的实现基于SQL对本地数据库的增删改查。对浏览器来讲,所谓的本地数据库,一般是指SQLite,比如Chrome和Safari会用SQLite实现本地存储。
如果说WebSQL方便我们对RDBMS进行操作,那么IndexedDB就是一种NoSQL,它存储的是key-value型数据,通常可以超过250M,且支持事务。
可以看到,本地存储是包含了多种存储方式,它可以很方便的将数据存储在客户端中,从而避免重复调用服务器资源。
而WebSQL,其实并不属于是H5规范的一部分,是一个单独的规范,只是浏览器端同时接受了它跟H5规范。当年,主流的浏览器(Chrome、Safari和Firefox)基本都支持WebSQL,可以在js里通过WebSQL来对客户端数据库进行操作。
2023-11-9 14:15:17 不过我查了下,目前多数浏览器基本都关闭了WebSQL。
如何使用WebSQL
怎么检测你的浏览器是否支持WebSQL?
在你的浏览器里,F12打开命令行,执行以下代码:
if (!window.openDatabase) {alert('浏览器不支持WebSQL');
}
或者是打开以下html:
<!DOCTYPE HTML>
<html><head><meta charset="UTF-8"><title>SQL必知必会</title> <script type="text/javascript"> if (!window.openDatabase) {alert('浏览器不支持WebSQL');} </script> </head><body><div id="status" name="status">WebSQL Test</div></body>
</html>
如果浏览器不支持WebSQL,会弹窗提示"浏览器不支持WebSQL",否则不会有弹窗提示。试了一下,连chrome现在都禁用WebSQL了。
不过出于兴趣,接下来还是简单介绍下WebSQL的使用吧。
打开数据库
如果数据库存在,则会直接打开,返回一个数据库句柄,不存在则会创建。
var db = window.openDatabase(dbname, version, dbdesc, dbsize,function() {});
5个参数分别是数据库名、版本号、描述、数据库大小、创建回调。
比如说我们想要创建一个名为wucai的数据库,版本号为1.0,大小是1024*1024,单位应该是KB:
var db = openDatabase('wucai', '1.0', '王者荣耀数据库', 1024 * 1024);
事务操作
开启事务执行提交或者回滚操作,如下:
transaction(callback, errorCallback, successCallback);
参数分别是:
- 处理事务的回调函数。一般在里面写SQL语句,会用到ExecuteSQL方法;
- 执行失败时的回调函数。可缺省;
- 执行成功时的回调函数,可缺省。
比如说我们开启一个事务,来创建一个heros数据表,并插入一条数据:
db.transaction(function (tx) {tx.executeSql('CREATE TABLE IF NOT EXISTS heros (id unique, name, hp_max, mp_max, role_main)');tx.executeSql('INSERT INTO heros (id, name, hp_max, mp_max, role_main) VALUES (10000, "夏侯惇", 7350, 1746, "坦克")');
});
SQL执行
使用ExecuteSQL来执行SQL语句,即增删改查。
tx.executeSql(sql, [], callback, errorCallback);
有4个参数,分别是:
- 要执行的SQL语句;
- SQL语句中的占位符(?)所对应的参数;
- 执行SQL成功时的回调函数;
- 执行SQL失败时的回调函数。
因此,我们创建heros数据表的时候,使用如下命令:
tx.executeSql('CREATE TABLE IF NOT EXISTS heros (id unique, name, hp_max, mp_max, role_main)');
在浏览器端做一个英雄的查询页面
具体步骤如下:
- 初始化数据。在 HTML 中设置一个 id 为 datatable 的 table 表格,然后在 JavaScript 中创建 init() 函数,获取 id 为 datatable 的元素。
- 创建showData方法。用来展示我们查询出来的一行数据。
- 使用openDatabase打开数据库。
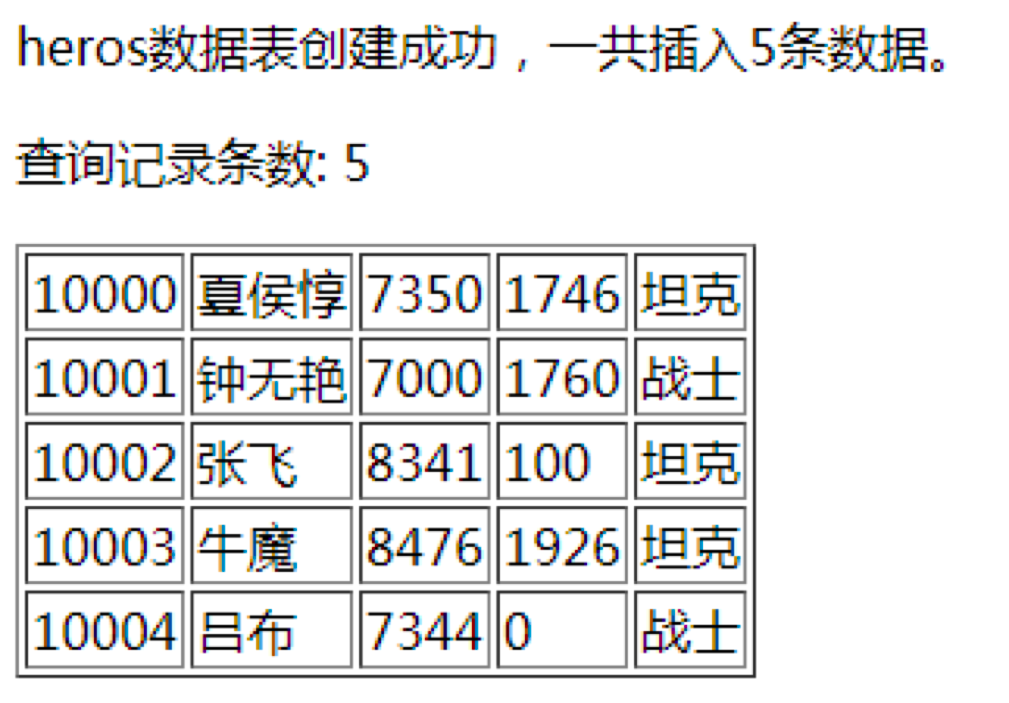
- 使用transaction执行两个事务。一个是创建heros数据表,并插入5条数据。另一个是对heros表进行查询,并将查询出的结果使用showData进行展示。
完整代码如下,我直接从教程里复制过来了:
<!DOCTYPE HTML>
<html><head><meta charset="UTF-8"><title>SQL必知必会</title> <script type="text/javascript">// 初始化function init() {datatable = document.getElementById("datatable");}// 显示每个英雄的数据function showData(row){var tr = document.createElement("tr");var td1 = document.createElement("td");var td2 = document.createElement("td");var td3 = document.createElement("td");var td4 = document.createElement("td");var td5 = document.createElement("td"); td1.innerHTML = row.id;td2.innerHTML = row.name;td3.innerHTML = row.hp_max;td4.innerHTML = row.mp_max;td5.innerHTML = row.role_main;tr.appendChild(td1);tr.appendChild(td2);tr.appendChild(td3);tr.appendChild(td4);tr.appendChild(td5);datatable.appendChild(tr); }// 设置数据库信息var db = openDatabase('wucai', '1.0', '王者荣耀英雄数据', 1024 * 1024);var msg;// 插入数据db.transaction(function (tx) {tx.executeSql('CREATE TABLE IF NOT EXISTS heros (id unique, name, hp_max, mp_max, role_main)');tx.executeSql('INSERT INTO heros (id, name, hp_max, mp_max, role_main) VALUES (10000, "夏侯惇", 7350, 1746, "坦克")');tx.executeSql('INSERT INTO heros (id, name, hp_max, mp_max, role_main) VALUES (10001, "钟无艳", 7000, 1760, "战士")');tx.executeSql('INSERT INTO heros (id, name, hp_max, mp_max, role_main) VALUES (10002, "张飞", 8341, 100, "坦克")');tx.executeSql('INSERT INTO heros (id, name, hp_max, mp_max, role_main) VALUES (10003, "牛魔", 8476, 1926, "坦克")');tx.executeSql('INSERT INTO heros (id, name, hp_max, mp_max, role_main) VALUES (10004, "吕布", 7344, 0, "战士")');msg = '<p>heros数据表创建成功,一共插入5条数据。</p>';document.querySelector('#status').innerHTML = msg;});// 查询数据db.transaction(function (tx) {tx.executeSql('SELECT * FROM heros', [], function (tx, data) {var len = data.rows.length;msg = "<p>查询记录条数: " + len + "</p>";document.querySelector('#status').innerHTML += msg;// 将查询的英雄数据放到 datatable中for (i = 0; i < len; i++){showData(data.rows.item(i));}});});</script></head> <body><div id="status" name="status">状态信息</div><table border="1" id="datatable"></table></body>
</html>
演示结果如下:
如何删除本地存储
那如何删除本地存储呢?
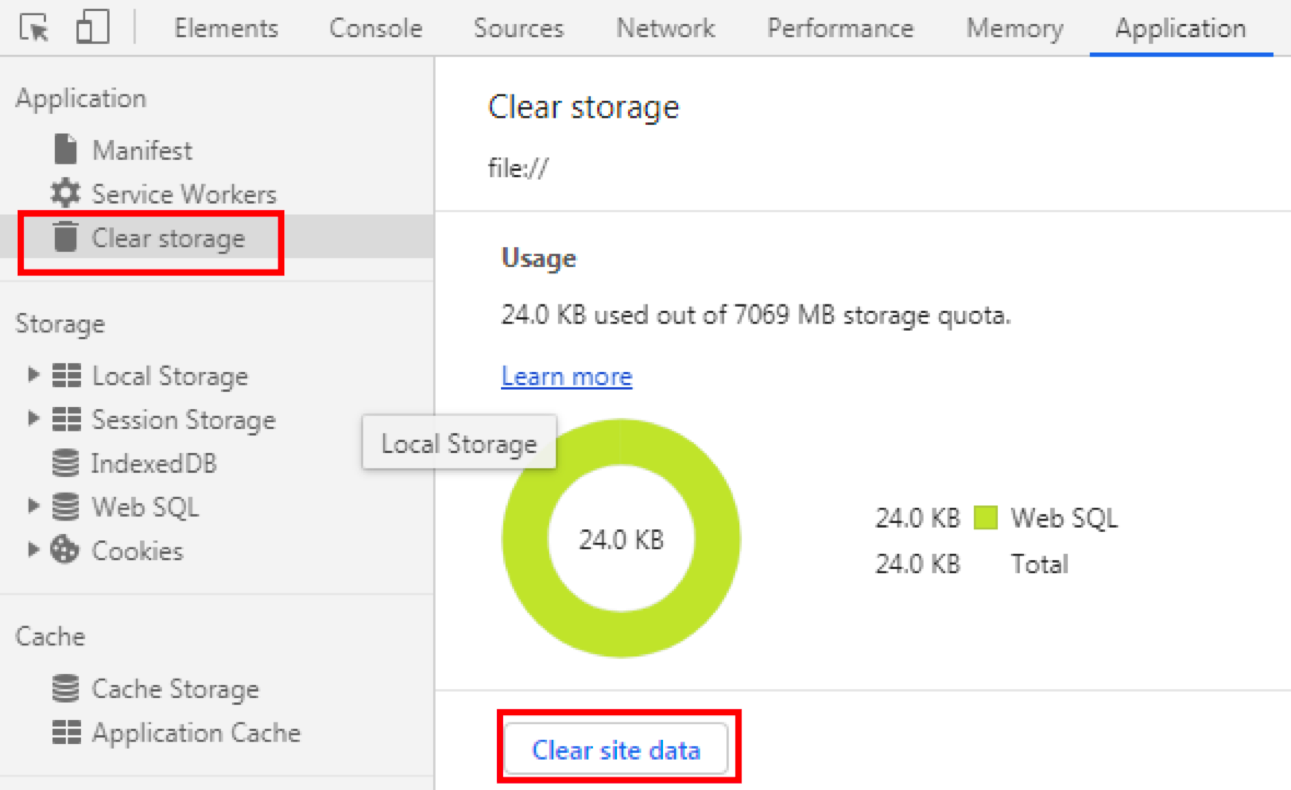
直接通过浏览器来删除就可以了,比如在 Chrome 浏览器中找到 Application 中的 Clear storage,然后使用 Clear site data 即可。
参考文献
- 39丨WebSQL:如何在H5中存储一个本地数据库?
这篇关于SQL实践篇(一):使用WebSQL在H5中存储一个本地数据库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





