本文主要是介绍python模拟登录我爱我家网站,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
什么是模拟登陆?
模拟登陆:用脚本模拟用户行为实现账户登陆。
模拟登陆分类
暴力模拟登陆:忽略web设计原理,忽略登陆需求,硬性的将cookie取出加载爬虫当中进行登录。
原理分析模拟登陆: 根据网站源码和抓包请求,分析网站登录原理,用代码依照登录原理向服务器具体接口提交具体数据,实现模拟登录,技术含量最高,难度最大。
浏览器驱动模拟登陆:使用Python调用浏览器驱动,执行浏览器行为(发送数据,点击),进行模拟登陆,这种模拟登陆由于难度低,逐渐被一些项目认可,但是效率低。
正常浏览器模拟登陆
无头浏览器模拟登陆
Cookie原理
上面说的前两种模拟登陆都需要我们了解cookie是啥
Cookie(曲奇,小饼干):是服务器下发给浏览器用于识别用户身份的校验值。
举个例子:
西游记当中唐僧手中的通关文牒:
每到一个国家,唐僧需要提交通关文牒来证明自己身份,同时每个国家的国王需要下发自己的校验来提供给唐僧校验身 份。
Cookie是实现当前web身份识别的基础手段,具有一定的不安全性,因为:
cookie下发,浏览器可以拒收
cookie下发到浏览器本地,容易被重写伪装
我们来查看cookie的下发和提交
cookie的下发是在和http请求的response header当中
案例地址url = http://www.wangcai5188.com/auth/signin
Cookie的设置和下发
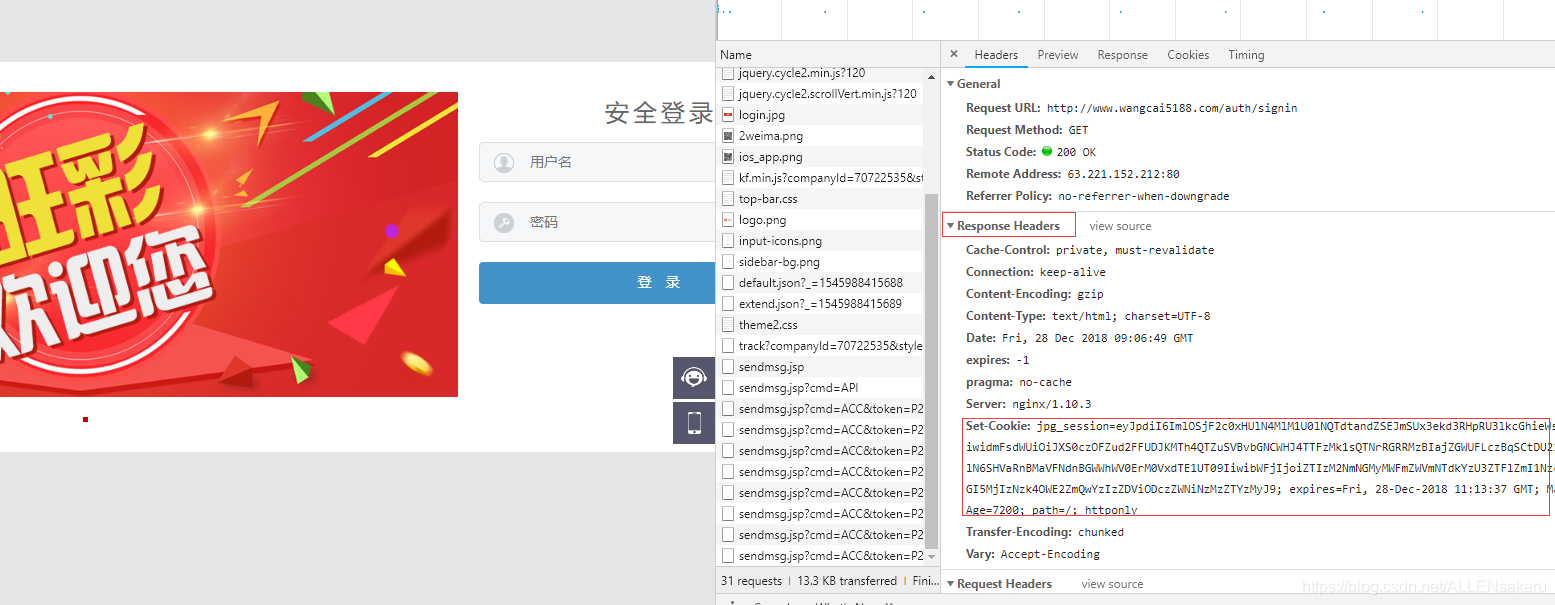
注意:
Set_cookie 也可以有多个
携带cookie在RequestHeader里面
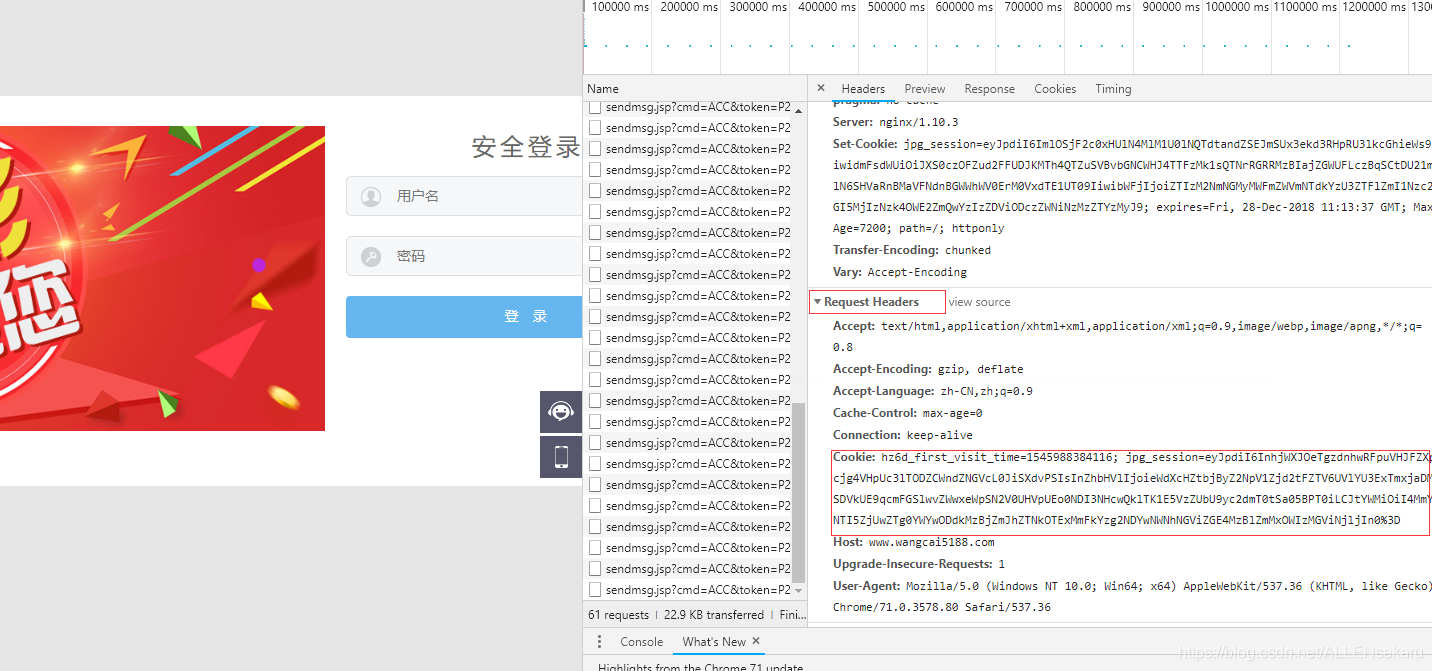
由上面得到我们在写爬虫的时候
需要关心cookie的下发,我们需要保存下发的cookie来维持自己的身份
需要关心提交的cookie
所有的Python爬虫模块默认都不携带cookie
Post 模拟登陆
模拟登陆分析技巧
结构分析
Form表单提交分析

在HTML的form标签当中,我们要关注两个参数
Method: 请求的方式,不写或者为空代表采用默认值 get,表单提交通常是post
Action: 提交的路由,指向处理提交数据的地址
由上面的分析和规律我们得到
我爱我家网站的请求方法是:post
密码和账号提交的位置:https://passport.5i5j.com/passport/sigin?city=bj
Form表单提交数据分析
上面的分析,我们看着很完美,其实不然,我们现在不知道我们提交了多少参数,我们从HTML界面上看有:用户名、密码两项,但是注意,为了防止最简单的爬虫
在网站设计的思路上:
有一个隐性的form元素hidden
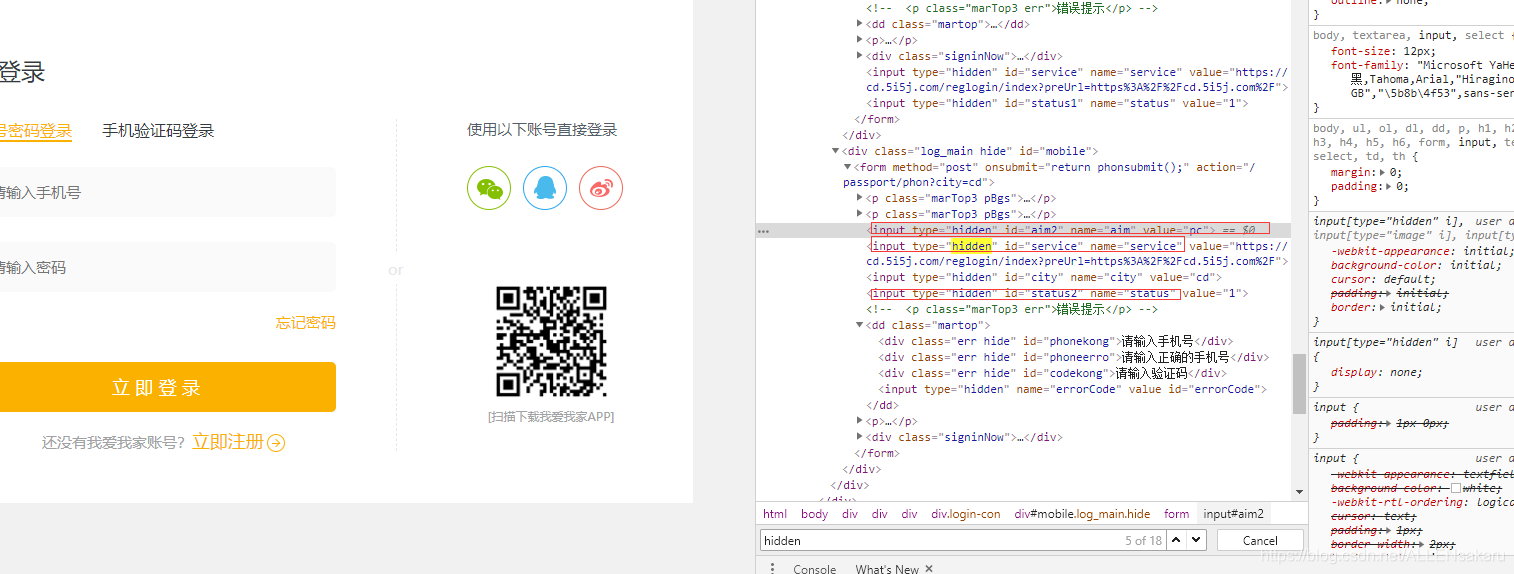
Hidden也可以像普通的form元素一样向后台以name= value的形式进行数据提交,但是在页面上不做显示。Hidden通常是不变的,我们在请求的时候,携带数据就可以,但是有部分网站的hidden的值来源于后台算法生成,所以是变化的,所以我们在爬虫请求登录的时候,要先从页面上抓取当前请求对应的hidden值。
抓包分析
上面结构分析,也可以说是静态分析,我们接下来是抓包分析,也是动态分析,
抓取登录页面的包
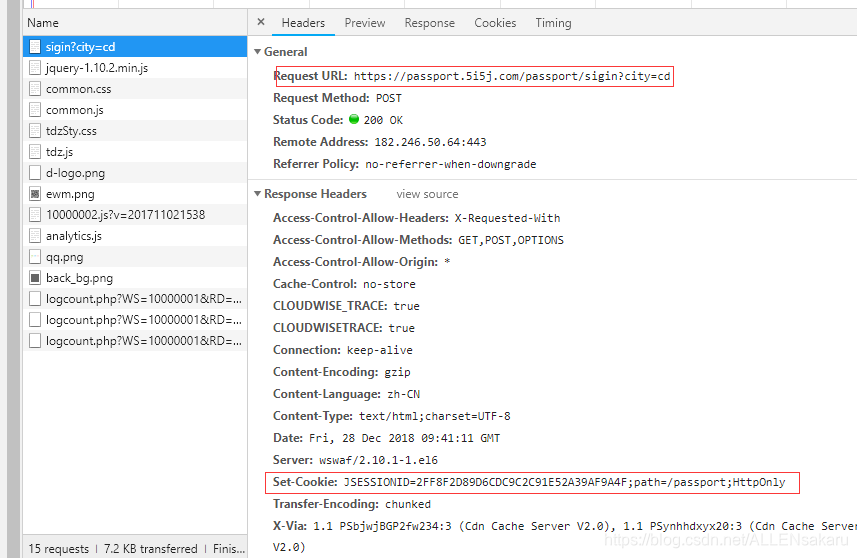
请求登录的包
我们需要故意输错密码,防止页面跳转的同时,抓取到登录的包

首先发现请求没有问题
请求登录接口会有cookie下载
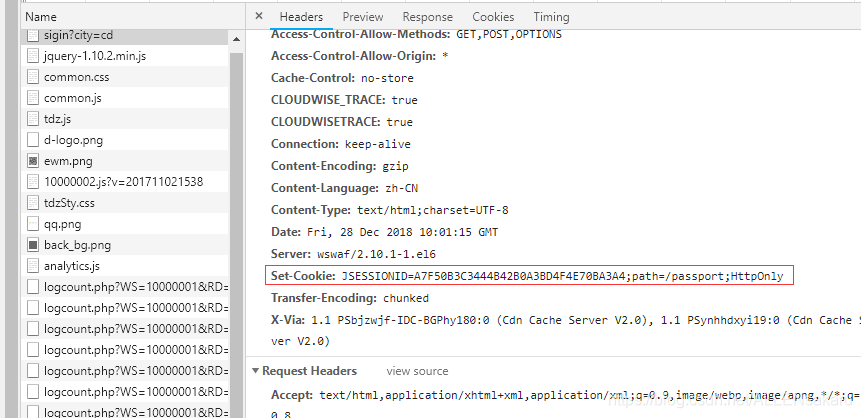
请求头部发现,我们在请求的时候
- 需要携带cookie
- 需要携带请求来源
- 浏览器的版本
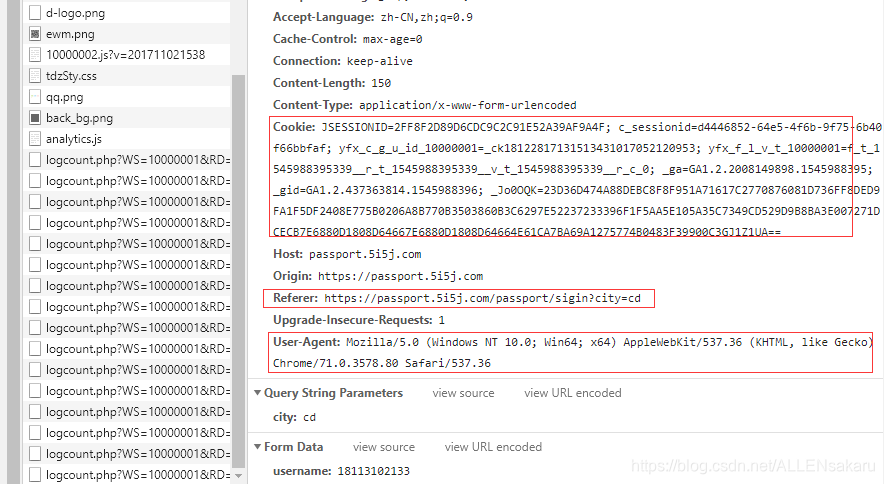
我们发现了请求携带的数据,比较结构分析,发现数据需求一致,而且是明文的!!!
通过上述分析得到以下结论:
当前我们的爬虫请求需要分为两个步骤
- 请求登录页面:
- 获取三项校验数据
- 获取登录页面下发的cookie
2、在得到请求的三项校验数据和cookie之后,我们发起对登录接口的请求
Urllib 系列的模拟登陆
模拟登陆目标:
我爱我家
https://passport.5i5j.com/passport/login?service=https%3A%2F%2Fcd.5i5j.com%2Freglogin%2Findex%3FpreUrl%3Dhttps%253A%252F%252Fcd.5i5j.com%252F&status=1&city=cdurllib模拟登录知识点
- urllib.requests.urlopen方法可以请求服务器,但是不保存cookie
- urllib需要结合cookielib进行模拟登录
Python2当中: cookielib
Python3当中: http.cookiejar
开始模拟登录的代码:
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author : ALLEN
# @Time : 2018/12/28 17:08
# @File : woaiwojia_spider.py
# @Software: PyCharmfrom lxml import etree
from urllib import parse
from urllib import request
import http.cookiejar as cookieliblogin_page_url = "https://passport.5i5j.com/passport/login?service=https%3A%2F%2Fcd.5i5j.com%2Freglogin%2Findex%3FpreUrl%3Dhttps%253A%252F%252Fcd.5i5j.com%252F&status=1&city=cd"login_page_header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"
}
#创建登录请求
req = request.Request(url = login_page_url,headers = login_page_header)#声明一个cookie容器
cookie = cookielib.MozillaCookieJar("1.txt")#创建cookie处理器
handler = request.HTTPCookieProcessor(cookie)#设置代理ip (无妄之灾)
#proxy = request.ProxyHandler({"http": "222.221.11.119:3128"})#创建自己的请求器(urlopen),我们自己定义的请求器是会保存服务器下发的cookie
opener = request.build_opener(handler)#发起请求 request.urlopen(req)
response = opener.open(req)#保存cookie
cookie.save(ignore_discard = True,ignore_expires = True) #参数是用来第一cookie过期和覆盖的设置content= response.read().decode()#获取三项校验数据
html = etree.HTML(content)
aim = html.xpath('//input[@id="aim1"]')[0].attrib["value"]
service = html.xpath('//input[@id="service"]')[0].attrib["value"]
status = html.xpath('//input[@id="status1"]')[0].attrib["value"]send_dict = {"username": "账号",#这里请填写自己的账号"password": "密码",#这里请填写自己的密码"aim": aim,"service": service,"status": status
}login_url = "https://passport.5i5j.com/passport/sigin?city=cd"login_headers = {"Referer": login_page_url,"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"
}
#封装发送数据
send_data = parse.urlencode(send_dict).encode() #Python3 要进行字节编码#构建登录请求
login_req = request.Request(url = login_url,headers = login_headers,data = send_data)#发起登录请求
login_respone = opener.open(login_req)#保存cookie
cookie.save(ignore_discard = True,ignore_expires = True) #参数是用来第一cookie过期和覆盖的设置content = login_respone.read().decode()print(content)
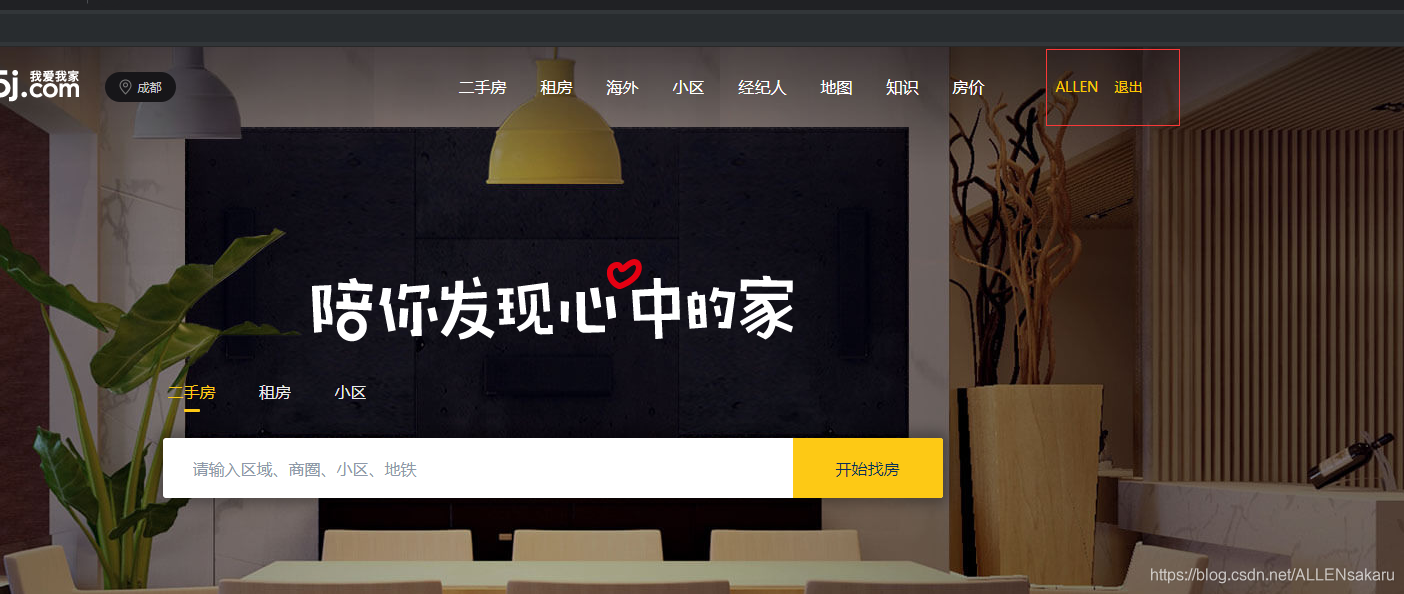
效果如下:
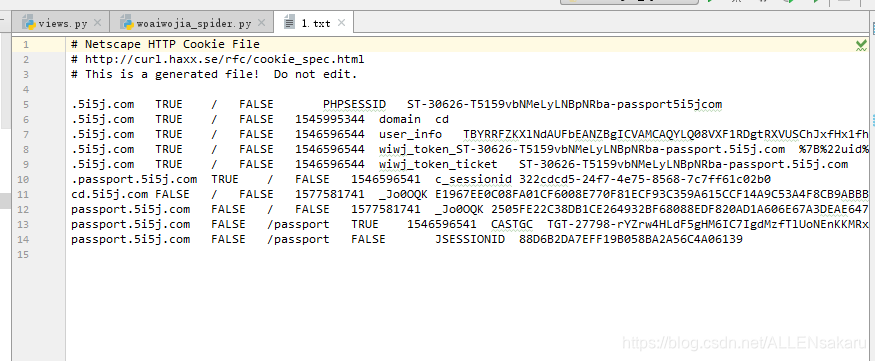
接下来我会更新如何模拟登陆 http://www.wangcai5188.com/auth/signin
大家也可以试着尝试登陆一下
代码如下:
#! /usr/bin/env python3
# -*- coding: utf-8 -*-
# @Author : ALLEN
# @Software: PyCharmimport requests
from lxml import etree
# 实例化一个保存cookie的请求器
session = requests.session()
# 发起对登录页面的请求
response = session.get("http://www.wangcai5188.com/auth/signin")
content = response.content.decode()
# 进行数据过滤,获取token和random的值
html = etree.HTML(content)
token, = html.xpath('//input[@name="_token"]/@value')
random, = html.xpath('//input[@name="_random"]/@value')
send_dict = {"username":"账号","password":"密码","_token":token,"_random":random
}
# 向服务器发起请求
url = "http://www.wangcai5188.com/auth/signin"
headers = {"Referer":"http://www.wangcai5188.com/auth/signin","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36"}
login_response = session.post(url = url,headers = headers,data = send_dict)
login_content = login_response.content.decode()
print("==========================================================")
print(login_response.status_code)
print("==========================================================")
print(login_content)效果如下:
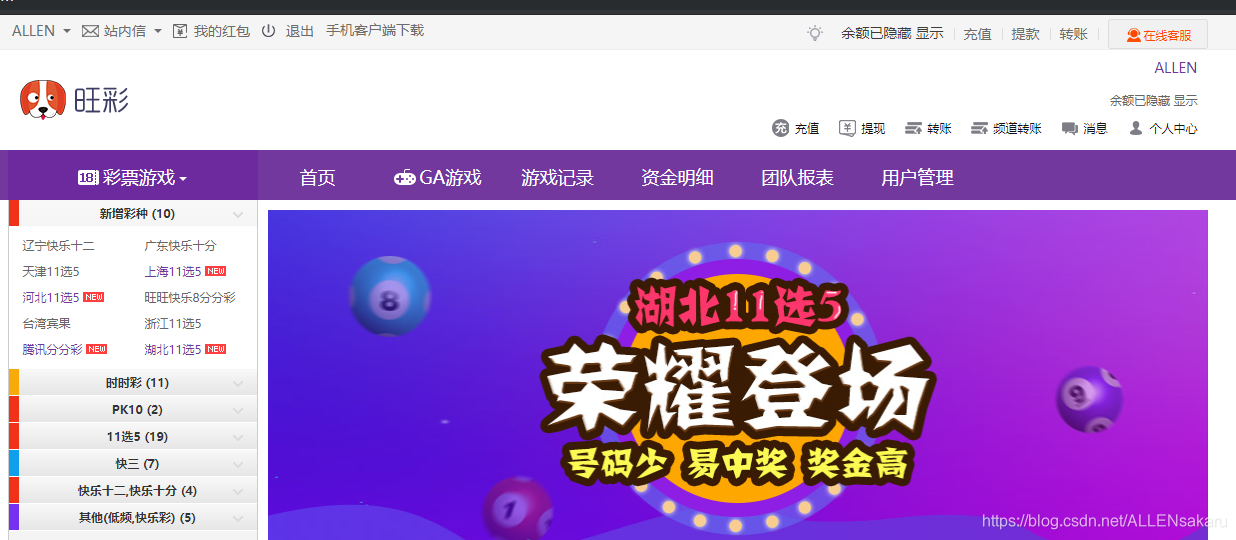
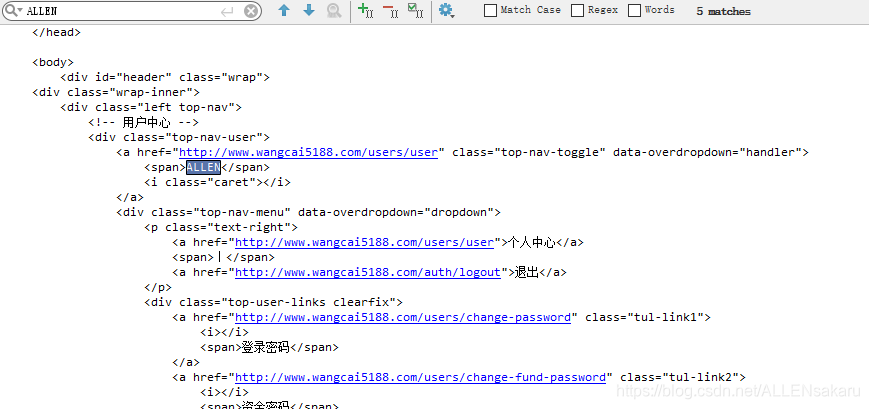
这篇关于python模拟登录我爱我家网站的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




