本文主要是介绍慢调用链诊断利器-ARMS 代码热点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:铖朴、义泊
可观测技术背景
从最早的 Google 发表的一篇名为《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》的论文开始,到后来以:Metrics(指标)、Tracing(链路追踪)以及 Logging(日志)三大方向互为补充的可观测解决方案逐渐被业界所接受并成为事实标准。
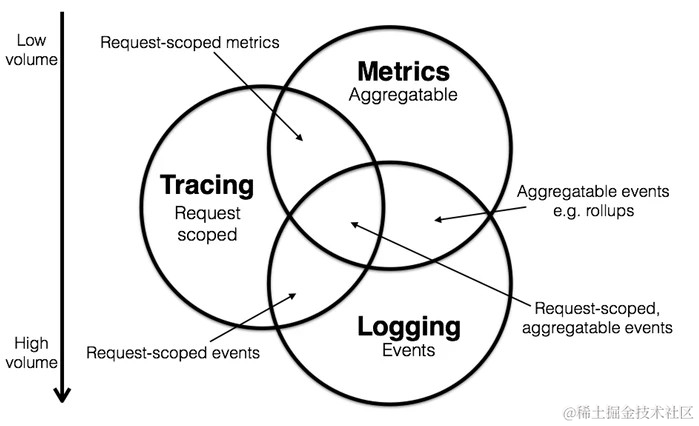
基于上述全栈可观测方案技术,诊断一个问题从之前的无从下手或者仅单靠日志变成为如下步骤:
- 通过 Metrics/Logs 提供的各式各样预设报警发现应用异常信息确定异常模块
- 对异常模块以及关联日志(Logs)进行查询分析,找到核心的报错信息
- 通过详细的调用链数据(Tracing)定位到引起问题的代码片段。
基于上述一整套可观测解决方案,不仅可在问题发生后快速定位问题,及时减损,很多时候甚至可以在大故障发生前,就实现对问题的提前发现和解决修复。
监控盲区
是否基于上述一整套可观测解决方案就可以一劳永逸,解决线上任何的监控问题了呢?其实不然,特别是在 Tracing 方面,由于一般其都是基于 Java Agent/SDK 技术方案对主流如 HTTP 服务、RPC 服务、数据库、分布式消息 MQ 等软件开发框架进行埋点采集调用链监控数据,然后再通过后续的调用链数据还原处理逻辑将监控信息与具体的请求关联在一起,从而实现当请求发生异常时,通过采集的监控数据就能查看到相关调用信息。调用链除了可以提供一次请求经过的核心链路方法外,另外一个核心作用就是帮助排查一个调用链中的耗时慢位置帮助做代码优化。具体排查过程可通过类似如下图所示的调用链详细信息对调用链中的耗时瓶颈逻辑进行诊断:
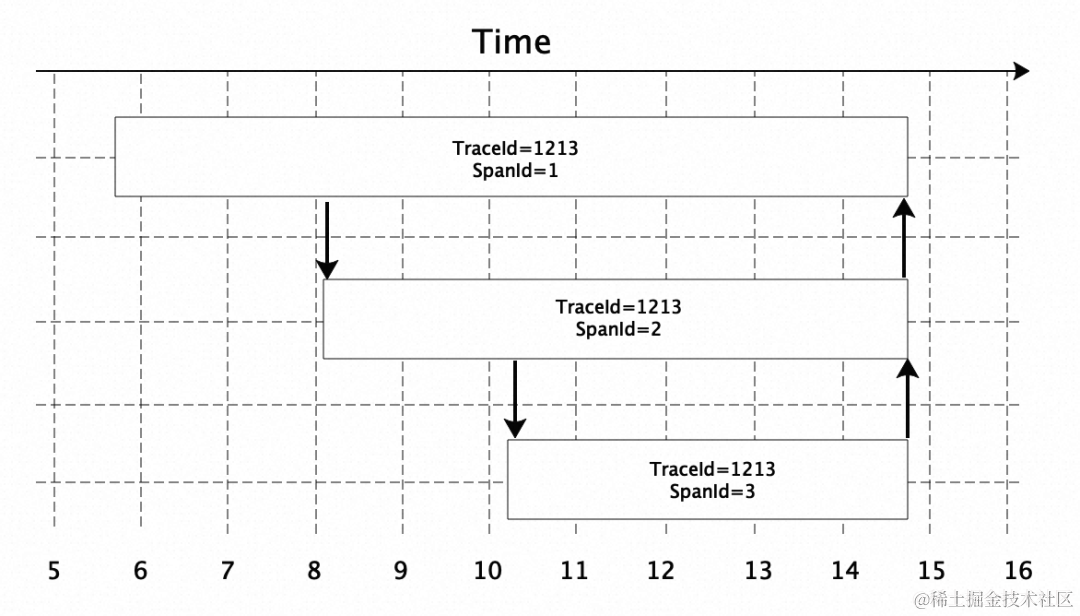
所上图所示,一次调用链作为一个 Trace,存在一个唯一的 TraceId,该 Trace 其中包含多个 Span,分别代表调用了下游的多个服务,其分别有一个对应的 SpanId 信息。通过上图,就可以知道一次请求所经过的多个服务(该处假设一个下游服务对应一个 Span,有的链路追踪系统可能会有差异)其所经历的耗时情况,从而对应用耗时瓶颈进行定位和做对应的性能优化。
但在分布式微服务领域,由于调用链路复杂,涉及跨机器甚至跨机房,由于一般的 Tracing 系统只能对主流开源软件框架中的核心方法进行埋点,当耗时位置出现在 Tracing 埋点缺失的用户业务逻辑时,在最终的调用链中会出现一段较长的耗时无法对应到具体的代码执行方法,从而导致无法对业务逻辑耗时进行准确的判断。
具体 Case 可见如下所示代码:
public String demo() throws SQLException {// 此处耗时1000ms,模拟其他业务耗时逻辑take1000ms(1000);// SQL 查询执行操作stmt = conn.createStatement();ResultSet rs = stmt.executeQuery("SELECT * FROM table");return "Hello ARMS!";
}private void take1000ms(long time) {try {Thread.sleep(time);} catch (InterruptedException e) {e.printStackTrace();}
}
在上述代码逻辑中,第 6~7 行为数据库连接相关的执行逻辑,这类逻辑一般主流的 Tracing 系统都会对其进行埋点覆盖,但第 4 行的具体客户业务耗时,一般都由缺失对应的监控埋点,导致其耗时最终都被统计在了上一层入口 Spring Boot 方法 demo 中。
其对应最终在 Tracing 调用链中展示形式可能类似于下图所示,通过 Tracing 调用链仅能知道第一层的外部接口耗时以及其中包含的知名软件框架执行逻辑耗时情况,其中灰色阴影部分为 Tracing 系统埋点未覆盖的用户业务逻辑代码部分,作为监控盲区,其实际耗时未知,对线上性能问题排查造成不少的阻碍:
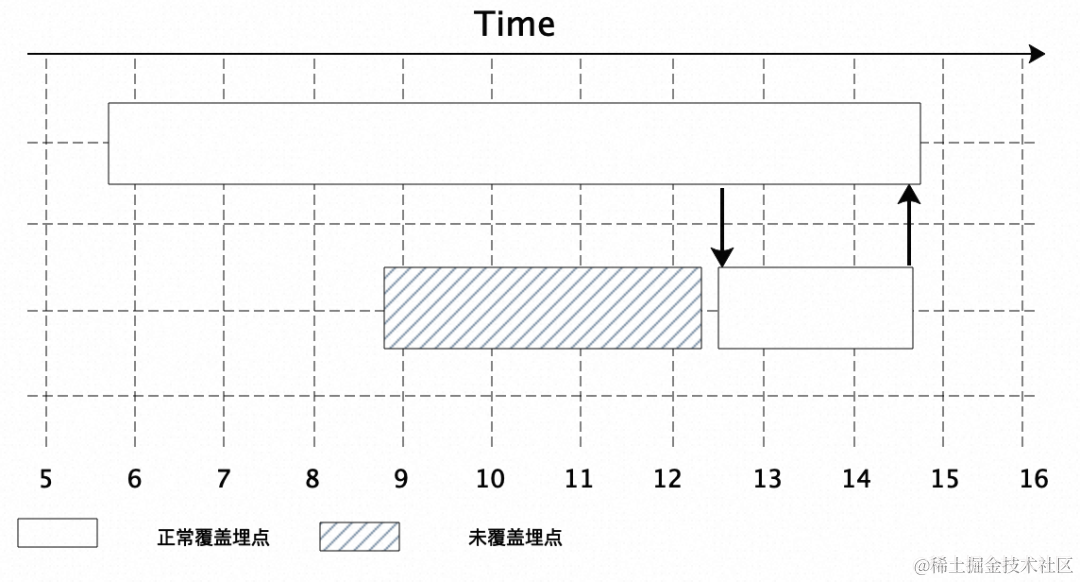
上述问题在企业用户中很常见,很多时候只能望其心叹,束手无策!
解决方案
针对上述 Tracing 系统埋点缺失情况下的慢调用链耗时诊断问题,据笔者了解到的,目前业界相关的解决方案很少,熟悉 Arthas 的同学可能会提到其中的 trace 命令 [ 1] ,确实其在一定程度上可以通过手工的方式在一些可以稳定复现的简单场景慢调用链中排查相关慢调用链具体耗时位置。但是其局限性也较为明显:
-
作用范围有限
仅支持稳定复现场景的慢调用诊断,对于有触发垃圾回收、资源争抢、网络问题等不易复现场景下的慢调用问题难以进行问题排查。
-
使用门槛高
在实际的生产场景中,调用链可能会很复杂,必须对业务代码非常熟悉的情况下,手动对特定的业务方法执行 trace 命令才能实现对请求耗时进行监控,如果对业务方法执行不熟悉或者是一些复杂的异步调用场景难以利用该工具进行问题排查。
-
排查成本高
针对单跳简单业务场景的慢调用使用该工具确实能进行相关问题排查,但是在跨应用多跳复杂业务场景下,排查过程就会变得很麻烦。不仅需要借助一些 APM 工具先定位具体慢调用所在的应用实例,而且对于业务调用方法栈很深的场景下,需要逐层逐层地执行相关命令,一步步监控才有可能找到问题源头。
综上所述, Arthas 的 trace 命令可以作用在一些简单的慢调用场景下,但对复杂场景下的慢调用链排查就显得心有余而力不足了!
为此,阿里云 ARMS 团队联合阿里巴巴 Dragonwell 团队通过持续剖析技术能够帮助用户较好地还原调用链方法栈信息从而较好地解决这类 Tracing 监控盲区问题。
ARMS 持续剖析能力
作为国内知名的 APM 工具,ARMS 除了提供了 Tracing 和 Metrics 以及 Logging 相关业务主流的可观测解决方案,另外也提供了开箱即用的持续剖析解决方案(Continuous Profiling,CP)。持续剖析是通过动态实时采集应用程序 CPU/ 内存等资源申请的堆栈信息,来帮助监测和定位应用程序的性能瓶颈。 ARMS 目前提供的持续剖析能力这个架构如下图所示:
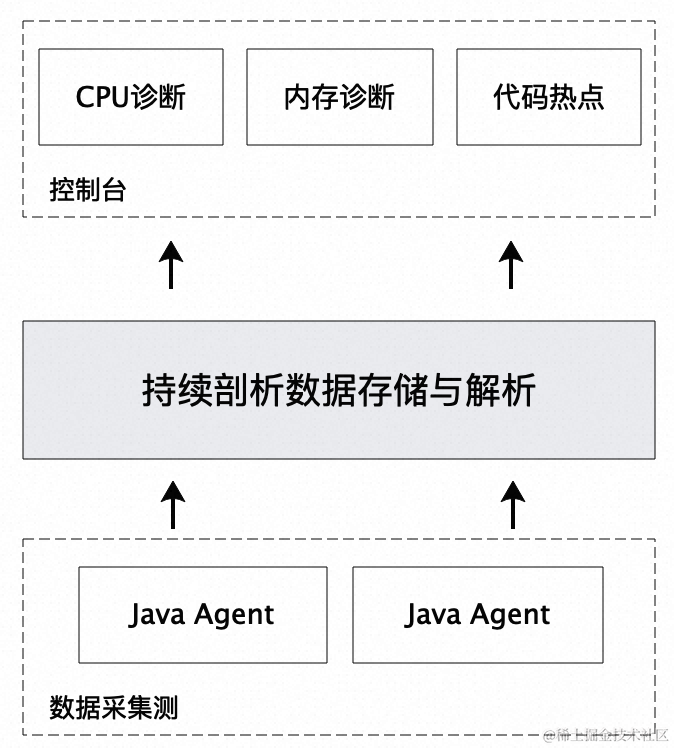
在端侧,通过 Java Agent 技术无侵入地在提供其他可观测能力的基础上,也提供了持续剖析数据采集能力。然后在服务端针对所采集的数据进行分析处理,最后在控制台中为用户提供了开箱即用包含:CPU 诊断、内存诊断以及代码热点功能。
CPU & 内存诊断
火焰图对于很多排查过应用性能问题的读者肯定不陌生,通过观察火焰图中是否有宽顶,来定位应用的性能问题。对很多研发人员来说,上述说的火焰图一般是指 CPU 热点火焰图。其表示的是一段时间内应用中执行了 CPU 的方法耗时情况。ARMS 提供的 CPU & 内存诊断功能在开源持续剖析 Async Profiler [ 2] 基础上支持在低开销条件下常态化采集应用 CPU & 内存申请方法栈信息,支持简单高效地常态化监控生产场景应用 CPU & 内存申请情况,告别利用开源工具难以常态化开启,容易错过不易复现问题场景的情况。

代码热点
说完 CPU & 内存诊断,有的读者可能会问,是不是利用 CPU 诊断对应的方法栈火焰图就可以帮助解决 Tracing 系统监控盲区问题帮助排查慢调用链呢?答案是否定的!因为 CPU诊断是通过定时抓取在 CPU 执行的执行线程的方法栈信息然后转换为火焰图。
而软件程序中线程的状态除了在 CPU 上执行的 Running 状态(也叫做 On-CPU),还有 Blocked、Waiting 等其他状态(统称为 Off-CPU),而一个慢调用链往往是多种线程状态叠加导致最终呈现出来的耗时长。因此 CPU 火焰图针对慢调用链场景作用比较有限。
那有没有一种火焰图技术不仅可以用来描述 On-CPU,还能包含 Off-CPU 内容呢?那就不得不提到墙钟火焰图(Wallclock)了。其实现原理并不复杂,就是以固定频率在应用所有线程中选一组线程采集其当前时刻的方法栈信息,通过聚合处理绘制出对应的火焰图。像 Async Profiler 也提供了相关能力。
本文的主角代码热点即是在开源 Async Profiler 墙钟能力的基础上,通过关联调用链中的 TraceId & SpanId 信息提供了调用链级别的 On & Off-CPU 火焰图, 可有效对 Tracing 的监控盲区细节进行还原,帮助用户诊断各类常见的慢调用链问题。具体过程如下图所示,通过在线程创建 Span 开始时刻和结束时刻进行 TraceId & SpanId 信息关联或关联取消,让最终产生的墙钟方法栈快照 Sample 中包含相关信息,然后通过对最终的持续剖析数据进行处理和分析,还原出对应调用链有关的墙钟火焰图来帮助定位慢调用链问题:
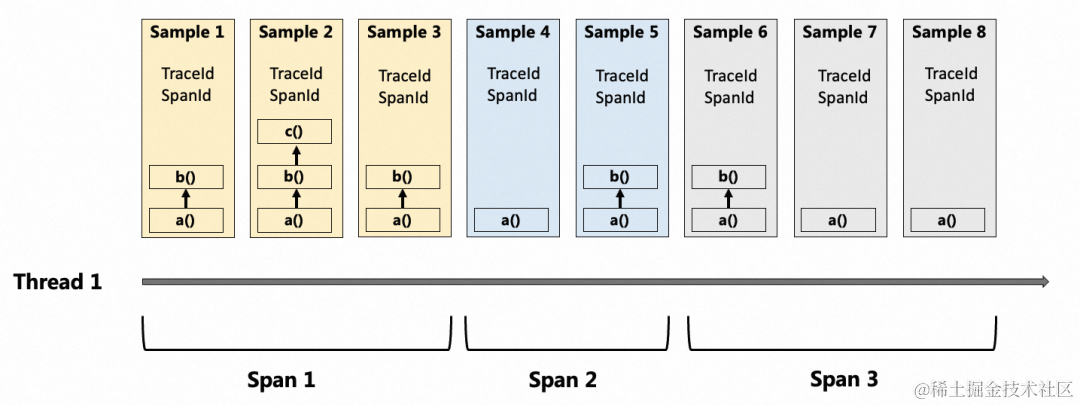
核心特点
当前 ARMS 提供的持续剖析能力相比于其他的慢调用链诊断工具或者开源持续剖析工具具有以下特点:
-
开销低
通过基于 Trace 过程的自动采样、关联采样率进行墙钟剖析等措施,目前 ARMS 提供的持续剖析产品能力 CPU 开销在 5%,堆外内存开销 50M 左右,GC 额外开销不明显,能在生产环境常态化开启。
-
粒度细
除了应用级的 CPU &内存热点外,还通过关联 TraceId & SpanId 信息提供针对调用链级的方法栈信息,可有效帮助诊断慢调用链问题。
-
安全可靠,简单高效
开源的一些持续剖析技术,比如利用 Arthas 生成 CPU火焰图(底层也是依赖 Async Profiler),由于一般都是即用即开,用完关闭,就算有技术风险,也不容易发现。在产品研发过程中,我们还是发现了很多开源技术比如 Async Profiler 持续剖析过程使用的风险问题。比如内存剖析可能引起应用 Crash #694 [ 3] ,墙钟火焰图可能造成线程长时间阻塞 #769 [ 4] 等。通过修复这些问题让我们产品能力更加安全可靠。除了安全,ARMS 提供的持续剖析能力常态化开启后数据自动保存7天,让用户不错过每一次慢调用链的诊断现场。
利用代码热点排查慢调用链
开启代码热点
- 登录 ARMS 控制台,在左侧导航栏选择应用监控 > 应用列表。
- 在应用列表页面顶部选择目标地域,然后单击目标应用名称。
- 在左侧导航栏中单击应用设置,然后单击自定义配置页签。
- 开启 CPU & 内存热点总开关后,开启代码热点开关并配置所需开启的应用实例的IP地址或者一组实例所属的网段地址。
- 在页面底部单击保存。
通过接口调用查看代码热点数据
- 登录 ARMS 控制台,在左侧导航栏选择应用监控 > 应用列表。
- 在应用列表页面顶部选择目标地域,然后单击目标应用名称。
- 在左侧导航栏中单击接口调用,并在页面右侧选择目标接口,然后单击调用链查询页签。
- 在调用链查询页签上单击目标 TraceId 链接。
- 在详情列中单击放大镜图标,首先,可以单击方法栈页签,看一下使用 Tracing 工具所展示的方法栈信息,可以看到其中仅包含了 MariaDB 相关的执行逻辑,而其前部的业务耗时并没有被记录。

- 接着,单击代码热点页签,可以在右侧的火焰图中看到除了 MariaDB 相关方法栈(对应下图右侧火焰图中的最右测较尖的火苗),还包含了 java.lang.Thread.sleep() 相关的 990ms 耗时(由于持续剖析基于采样方式获取线程方法栈,可能会存在些许偏差)。
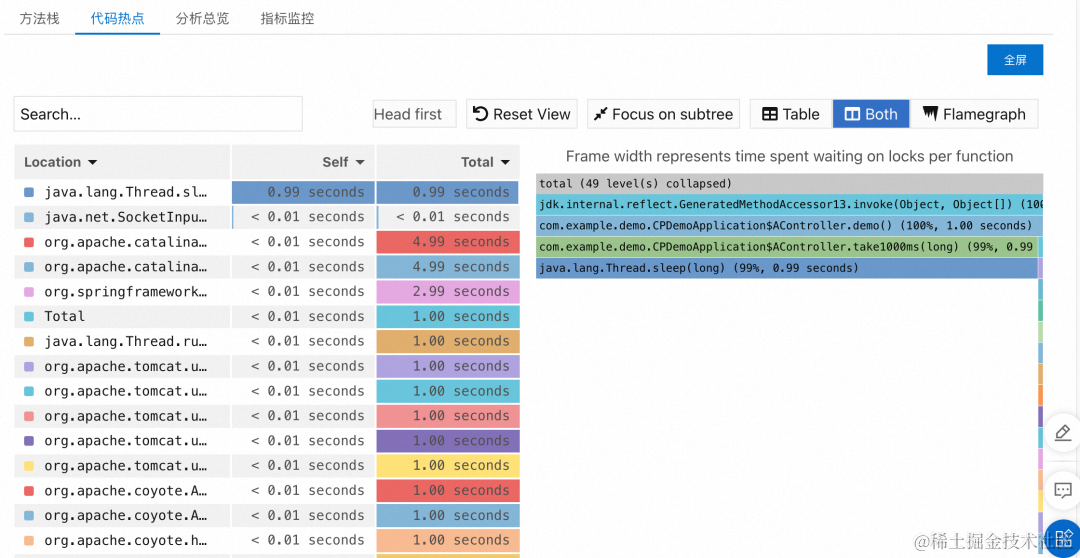
图中左侧为本次调用中所涉及的所有方法所耗时情况列表,右侧为对应方法所有方法栈信息所绘制的火焰图。其中,Self 列展示了方法自身耗时。作为排查具体的热点代码逻辑,可以通过重点关注 Self 这一列或者直接看右侧火焰图中底部的较宽火苗从中定位到高耗时的业务方法,较宽火苗其是引发上层耗时高的根源,一般是系统性能的瓶颈所在,例如上图中的 java.lang.Thread.sleep() 方法。其他更多使用细节可以参考该功能相关用户文档 [ 5] 。
相关链接:
[1] trace 命令
https://arthas.aliyun.com/en/doc/trace.html
[2] Async Profiler
https://github.com/async-profiler/async-profiler
[3] #694
https://github.com/async-profiler/async-profiler/issues/694
[4] #769
https://github.com/async-profiler/async-profiler/issues/769
[5] 用户文档
https://help.aliyun.com/zh/arms/application-monitoring/user-guide/use-code-hotspots-to-diagnose-code-level-problems?spm=a2c4g.11186623.0.i3
这篇关于慢调用链诊断利器-ARMS 代码热点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





