本文主要是介绍论文阅读——RS DINO,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RS DINO: A Novel Panoptic Segmentation Algorithm for High Resolution Remote Sensing Images
基于MASKDINO模型,加了两个模块:
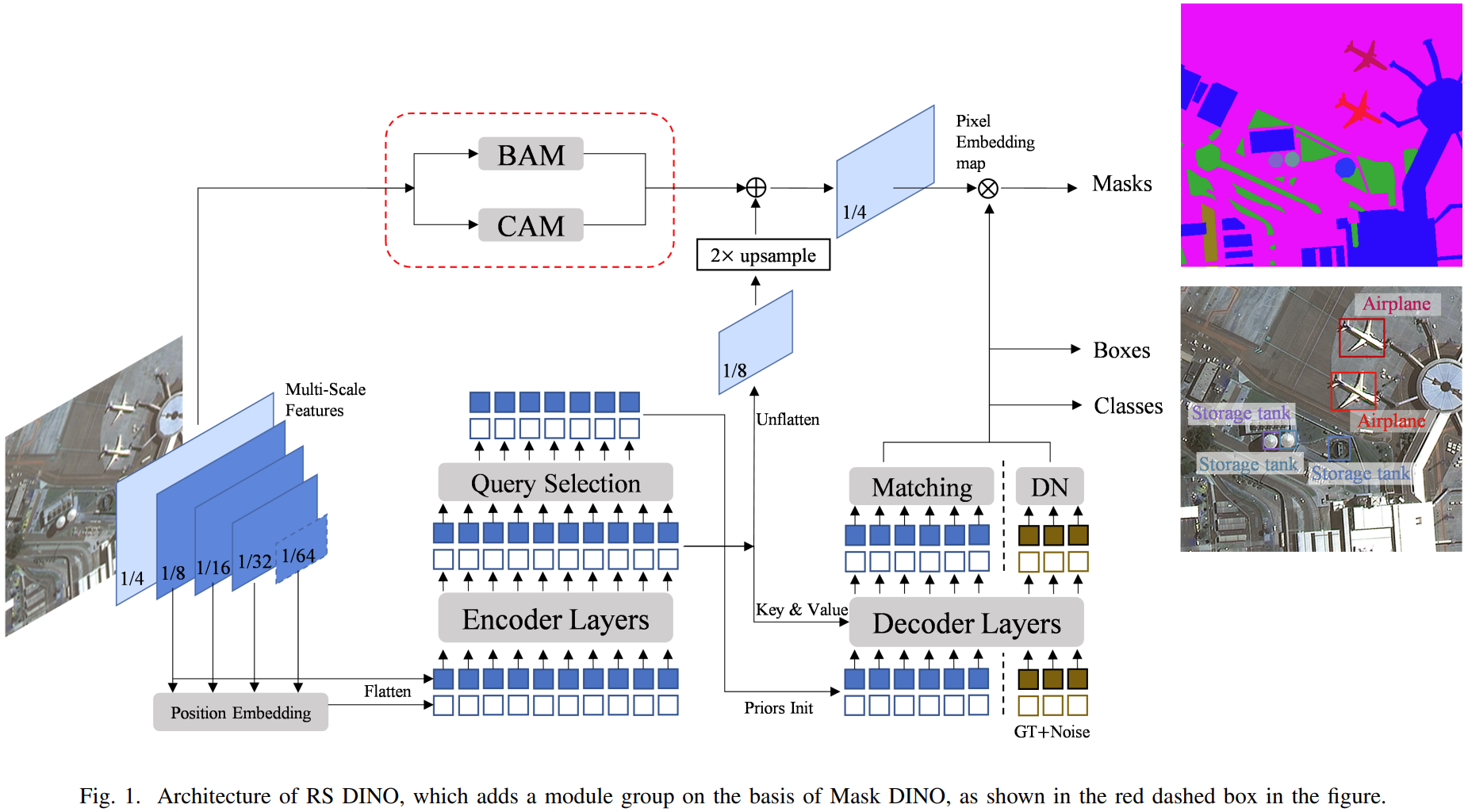
BAM:Batch Attention Module
遥感图像切分的时候把一个建筑物整体比如飞机场切分到不同图片中,这样就切分成几块了,这样会使图片特征产生一些裁剪损失。
所以,提出通过计算不同图片patch之间的注意力提取长距离上下文信息,来减小这种损失。
另外dataloader并没有打乱顺序,而是设定为一个预定好的顺序放到dataloader中。
具体如下:
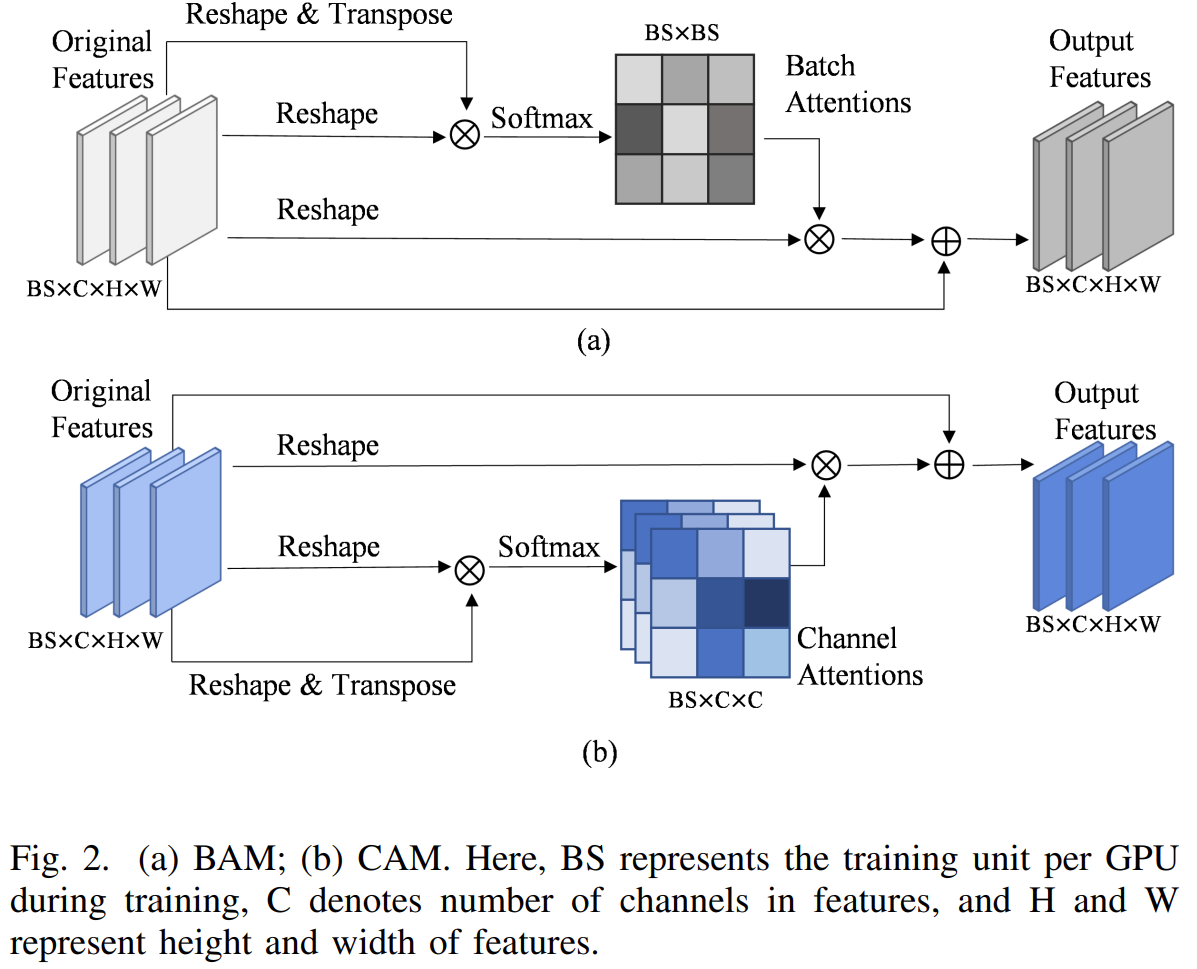
操作起来就是,把一个batch的特征打成一个向量,然后不同batch之间计算注意力,然后再reshape回去。
CAM:Channel Attention Module
一个特征图在通道级别上做注意力,得到注意力分数后和原来的特征图相乘,然后再加上原始特征图,相当于一个残差连接。
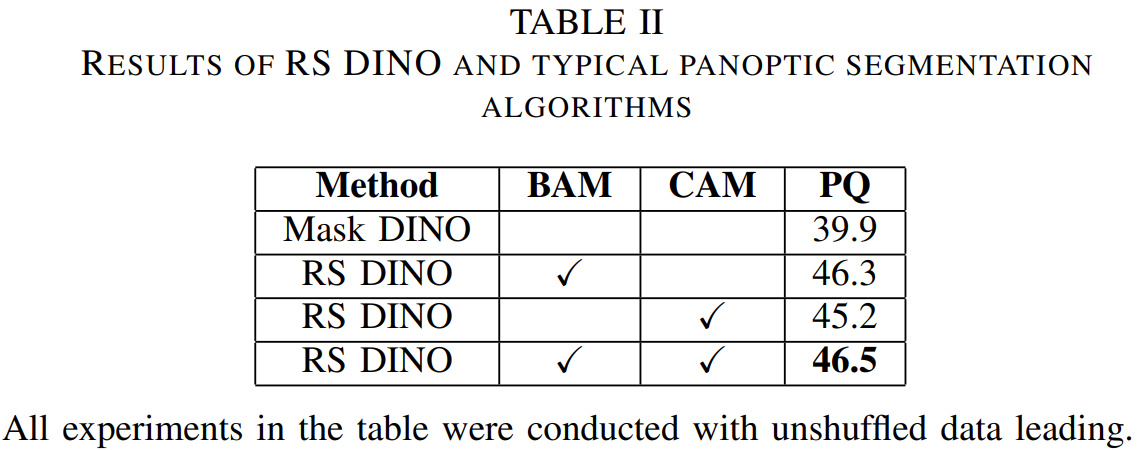
实验结果:

这篇关于论文阅读——RS DINO的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)
