本文主要是介绍JDBC常见的几种连接池使用(C3PO、Druid、HikariCP 、DBCP),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
✨前言✨
本篇作为主要在于介绍jdbc数据库连接池,以及多种连接池的用法
🍒欢迎点赞 👍 收藏 ⭐留言评论 📝私信必回哟😁
🍒博主将持续更新学习记录收获,友友们有任何问题可以在评论区留言
文章目录
- 一,JDBC数据库连接池的必要性
- 二,数据库连接池技术
- 三,多种开源的数据库连接池
- 1,C3P0数据库连接池
- 2,Druid (德鲁伊) 数据库连接池
- 3,HikariCP数据库连接池
- 4,DBCP数据库连接池
一,JDBC数据库连接池的必要性
1,在使用开发基于数据库的web程序时,传统的模式基本步骤:
- 在主程序(如servlet、beans)中建立数据库连接
- 进行sql操作
- 断开数据库连接
2,这种模式开发,存在的问题:
-
普通的JDBC数据库连接使用 DriverManager 来获取,每次向数据库建立连接的时候都要将
Connection加载到内存中,再验证用户名和密码(得花费0.05s~1s的时间)。需要数据库连接的时候,就向数据库要求一个,执行完成后再断开连接。这样的方式将 会消耗大量的资源和时间 。数据库的连接资源并没有得到很好的重复利用。若同时有几百人甚至几千人在线,频繁的进行数据库连接操作将占用很多的系统资源,严重的甚至会造成服务器的崩溃。 -
对于每一次数据库连接,使用完后都得断开 。否则,如果程序出现异常而未能关闭,将会导致数据库系统中的内存泄漏,最终将导致重启数据库。(回忆:何为Java的内存泄漏?)
-
这种开发 不能控制被创建的连接对象数 ,系统资源会被毫无顾及的分配出去,如连接过多,也可能导致内存泄漏,服务器崩溃。
二,数据库连接池技术
为解决传统开发中的数据库连接问题,可以采用数据库连接池技术。
1、数据库连接池的基本思想:
-
就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
-
数据库连接池负责 分配、管理 和 释放 数据库连接,它 允许应用程序重复使用一个现有的数据库连接,而不是重新建立一个。
-
数据库连接池在初始化时将创建一定数量的数据库连接放到连接池中,这些 数据库连接的数量是由最小数据库连接数来设定的。无论这些数据库连接是否被使用,连接池都将一直保证至少拥有这么多的连接数量。连接池的 最大数据库连接数量限定了这个连接池能占有的最大连接数,当应用程序向连接池请求的连接数超过最大连接数量时,这些请求将被加入到等待队列中。
2、数据库连接池的工作原理:
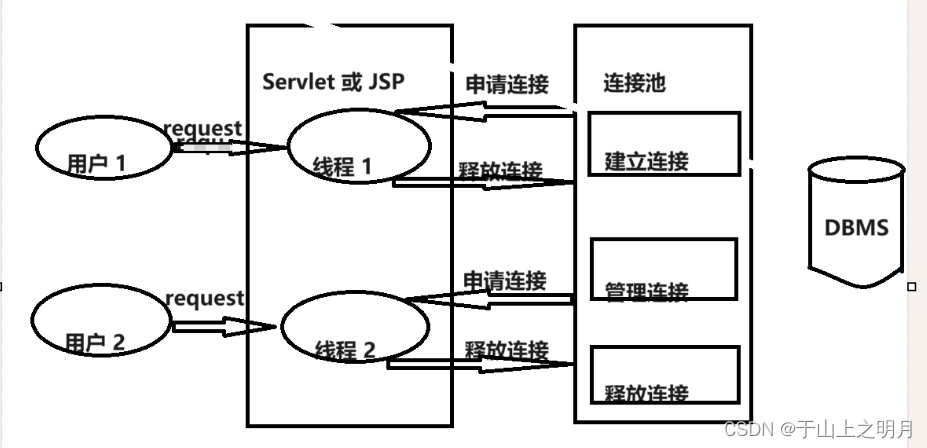
3、数据库连接池技术的优点:
(1)资源重用
由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
(2)更快的系统反应速度
数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池中备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接,避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间
(3)新的资源分配手段
对于多应用共享同一数据库的系统而言,可在应用层通过数据库连接池的配置,实现某一应用最大可用数据库连接数的限制,避免某一应用独占所有的数据库资源
(4)统一的连接管理,避免数据库连接泄漏
在较为完善的数据库连接池实现中,可根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露
三,多种开源的数据库连接池
1、JDBC 的数据库连接池使用 javax.sql.DataSource 来表示,DataSource 只是一个接口,该接口通常由服务器(Weblogic, WebSphere, Tomcat)提供实现,也有一些开源组织提供实现:
- DBCP是Apache提供的数据库连接池。tomcat服务器自带dbcp数据库连接池。速度相对c3p0较快,但因自身存在BUG,Hibernate3已不再提供支持。
- C3P0 是一个开源组织提供的一个数据库连接池,速度相对较慢,稳定性还可以,hibernate官方推荐使用。
- Proxool 是sourceforge下的一个开源项目数据库连接池,有监控连接池状态的功能,稳定性较c3p0差一点.
- BoneCP 是一个开源组织提供的数据库连接池,速度快。
- Druid 是阿里提供的数据库连接池,据说是集DBCP 、C3P0,Proxool优点于一身的数据库连接池,但是速度不确定是否有BoneCP快。
2、DataSource 通常被称为数据源,它包含连接池和连接池管理两个部分,习惯上也经常把 DataSource 称为连接池
3、DataSource用来取代DriverManager来获取Connection,获取速度快,同时可以大幅度提高数据库访问速度。
特别注意:
-
数据源和数据库连接不同,数据源无需创建多个,它是产生数据库连接的工厂,因此整个应用只需要一个数据源即可。
-
当数据库访问结束后,程序还是像以前一样关闭数据库连接:conn.close();
但conn.close()并没有关闭数据库的物理连接,它仅仅把数据库连接释放,归还给了数据库连接池。
1,C3P0数据库连接池
jar包资源获取 链接:
https://pan.baidu.com/s/1i2I_KacKLyMyZPvJLseMoQ?pwd=0101
解压之后把下面两个jar包添加到库,新版需要添加这两个到库中,如下
添加xml配置文件,文件名c3p0-config.xml固定的可复制,上面资源包中也有
<c3p0-config><!--使用默认的配置读取数据库连接池对象 --><default-config><!-- 连接参数 --><property name="driverClass">com.mysql.cj.jdbc.Driver</property><!-- 连接数据库参数 --><property name="jdbcUrl">jdbc:mysql://localhost:3306/sciencedb</property><!-- 用户 --><property name="user">root</property><!-- 密码 --><property name="password">root</property><!-- 连接池参数 --><!--初始化申请的连接数量--><property name="initialPoolSize">5</property><!--最大的连接数量--><property name="maxPoolSize">10</property><!--超时时间--><property name="checkoutTimeout">3000</property></default-config><!-- <named-config name="otherc3p0">--><!-- <!– 连接参数 –>--><!-- <property name="driverClass">com.mysql.jdbc.Driver</property>--><!-- <property name="jdbcUrl">jdbc:mysql://localhost:3306/hs_test?serverTimezone=Asia/Shanghai</property>--><!-- <property name="user">root</property>--><!-- <property name="password">root</property>--><!-- <!– 连接池参数 –>--><!-- <property name="initialPoolSize">5</property>--><!-- <property name="maxPoolSize">8</property>--><!-- <property name="checkoutTimeout">1000</property>--><!-- </named-config>-->
</c3p0-config>
连接测试:
@Testpublic void Test_1() throws Exception{//获取到c3p0中默认的数据源ComboPooledDataSource comboPooledDataSource =new ComboPooledDataSource();//传入参数使用指定的c3p0连接池//ComboPooledDataSource comboPooledDataSource =// new ComboPooledDataSource("otherc3p0");//创建连接数据库Connection conn = comboPooledDataSource.getConnection();System.out.println(conn);conn.close();}
输出显示:

c3p0需要配置log4j日志不然的话控制台会输出很多日志信息
https://blog.csdn.net/sjs52406/article/details/134472475?spm=1001.2014.3001.5502
https://blog.csdn.net/weixin_50552284/article/details/115732145
配置文件log4j.properties
#日志打印的级别及目的地 debug>info>warn>error>fatal
#stdout控制台 logfile日志文件
log4j.rootLogger=warn , stdout,logfile# Console output...打印到控制台
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %F %p %m%n#日志文件打印设置
log4j.appender.logfile=org.apache.log4j.FileAppender
#日志的文件地址
log4j.appender.logfile.File=gdLog.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %F %p %m%n2,Druid (德鲁伊) 数据库连接池
jar包资源获取 链接:
https://pan.baidu.com/s/1n992-5zlNGN8ZvglS6yFZA?pwd=0101
同样需要添加在项目中,如下:

添加配置文件文件名不固定
#驱动名称(连接MySQL)
driverClassName = com.mysql.cj.jdbc.Driver
# 参数 ? rewiteBatchedStatments = true 表示支持批处理机制
url = jdbc:mysql://localhost:3306/chenzhoudianyin
# 用户名
username = root
# 密码
password = root
# 初始化连接数量
initialSize = 10
# 最小连接数量
minIdle = 5
# 最大连接数量
maxActive = 500
# 超时5000ms (在等待队列的最长等待时间,诺超时,放弃此次连接)
maxWait = 5000
连接测试:
@Test
public void Test1() throws Exception {//加载配置文件Properties properties = new Properties();properties.load(new FileInputStream("src\\jdbc.properties"));//在工厂中 创建一个数据库, 数据源的连接信息来源于,properties配置文件中DataSource dataSource = DruidDataSourceFactory.createDataSource(properties);Connection conn = dataSource.getConnection();System.out.println(conn);conn.close();}
输出显示:

3,HikariCP数据库连接池
jar包资源获取 链接:
https://pan.baidu.com/s/1z4TBBhONEwZQ6-eayvyb8w?pwd=0101
HikariCP 也需要配置log4j日志,如下

添加配置文件:
# 数据库连接URL
jdbcUrl=jdbc:mysql://localhost:3306/chenzhoudianyin
# 数据库用户名
username=myusername
# 数据库密码
password=mypassword
# 连接池名称
poolName=MyConnectionPool
# 连接池大小
maximumPoolSize=10
# 最小空闲连接数
minimumIdle=5
# 连接超时时间(毫秒)
connectionTimeout=30000
# 空闲连接超时时间(毫秒)
idleTimeout=600000
# 最大生存时间(毫秒)
maxLifetime=1800000
连接测试:
@Testpublic void TextHiaki() throws Exception{//1,配置连接池HikariConfig hikariConfig = new HikariConfig();hikariConfig.setJdbcUrl("jdbc:mysql://localhost:3306");hikariConfig.setDriverClassName("com.mysql.cj.jdbc.Driver");hikariConfig.setUsername("root");hikariConfig.setPassword("root");hikariConfig.setMaximumPoolSize(30);//最大连接数hikariConfig.setMinimumIdle(10); //最小连接数//连接超时时间从连接池中获取一个连接最大等待多久时间,单位毫秒hikariConfig.setConnectionTimeout(3000);//2.通过配置类生成HikariCP连接池对象HikariDataSource dataSource = new HikariDataSource(hikariConfig);System.out.println(dataSource.getConnection());}
输出显示

4,DBCP数据库连接池
jar包资源获取 链接:
https://pan.baidu.com/s/1x4gKgfGL07-J3zTe9Ph17w?pwd=0101
同样需要添加在项目中,如下:

添加配置文件:
url=jdbc:mysql://localhost:3306/sciencedb
driverClassName=com.mysql.cj.jdbc.Driver
username=root
password=root
initialSize=10
maxActive=30
maxWait=3000
连接测试
@Testpublic void testDBCP() throws Exception{// 创建一个Properties对象Properties properties = new Properties();// 创建一个FileInputStream对象,用于读取src\\dbcp.properties文件FileInputStream fileInputStream= new FileInputStream("src\\dbcp.properties");// 使用FileInputStream对象读取文件,并将文件内容加载到properties对象中properties.load(fileInputStream);// 使用properties对象创建一个BasicDataSource对象BasicDataSource dataSource = BasicDataSourceFactory.createDataSource(properties);// 打印dataSource对象创建的连接System.out.println(dataSource.getConnection());}
输出显示

✨最后✨
总结不易,希望uu们不要吝啬你们的👍哟(^U^)ノ~YO!!
如有问题,欢迎评论区批评指正😁
这篇关于JDBC常见的几种连接池使用(C3PO、Druid、HikariCP 、DBCP)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







