本文主要是介绍Linux shell编程学习笔记37:readarray命令和mapfile命令,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

目录
- 0 前言
- 1 readarray命令的格式和功能
-
- 1.1 命令格式
- 1.2 命令功能
- 1.3 注意事项
- 2 命令应用实例
-
- 2.1 从标准输入读取数据时不指定数组名,则数据会保存到MAPFILE数组中
- 2.2 从标准输入读取数据并存储到指定的数组
- 2.3 使用 -O 选项指定起始下标
- 2.4 用-n指定有效行数
- 2.5 用-s来路过部分数据
- 2.6 用-c和-C选项使用回调程序
- 2.7 使用输出重定向和-t选项从磁盘文件中读取数据
- 3 mapfile命令
0 前言
在交互式编程中,数组元素的值有时是需要从程序外部输入的。比如由用户通过键盘输入的,这时我们可以使用read -a命令来实现,但需要重复输入的数据比较多时,用read -a命令就不太方便,效率也不够高。而且对于有些经常使用的固定数据,我们可以把这些数据存放在一个文件里,然后在使用这些数据的时候,再从文件里把数据读出来。
为此,Linux专门提供了 readarray命令。
1 readarray命令的格式和功能
我们 可以使用命令 help readarray 来查看 readarray 命令的帮助信息。
purleEndurer @ bash ~ $ help readarray
readarray: readarray [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]
Read lines from a file into an array variable.
A synonym for `mapfile'.purleEndurer @ bash ~ $ readarray --help
bash: readarray: --: invalid option
readarray: usage: readarray [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]
purleEndurer @ bash ~ $

可惜help readarray命令 显示的帮助信息不多。我们 又尝试 readarray --help 命令,但是readarray 命令不支持 --help 选项。
1.1 命令格式
readarray [-n 最大行数] [-O 起始下标] [-s 跳过行数] [-t] [u 文件描述符] [-C 回调程序] [-c 行数] [数组名]
| 选项 | 说明 | 备注 |
|---|---|---|
| -c 行数 | 每读取指定行数就调用一次"-C 回调程序"选项指定的回调程序 默认为每5000行调用一次回调程序 | count |
| -C 回调程序 | 每读取"-c 行数"选项指定的行数就执行一次回调程序 | callback |
| -n 最大行数 | 最多只拷贝指定的最大行数的数据到数组中 默认为0,即拷贝所有行。 | number |
| -O 起始下标 | 指定从哪个下标开始存储数据,默认为0。 对于二维数组来说,指定的是起始行数。 | origin |
| -s 跳过行数 | 忽略指定的跳过行数中的数据,从跳过行数之后开始 | skip |
| -t | 移除尾随行分隔符,默认是换行符 主要配合 -u选项使用 | trim |
| -u 文件描述符 | 指定从文件描述符而非标准输入中读取数据 | use |
1.2 命令功能
从标准输入或指定文件读取数据并存储到指定的数组中。
1.3 注意事项
- 在标准输入数据时,按Enter键换行,输完所有数据后,要按Ctrl+D来结束输入(Ctrl+D在屏幕上无显示)。
- 如果指定的数组变量原来已储存有数值,在使用readarray命令时没有-O选项,那么数组变量中原有的数据会先被清空,然后再存储新读取的数据。
- 如果不指定数组名,则数据会保存到MAPFILE数组中。
2 命令应用实例
2.1 从标准输入读取数据时不指定数组名,则数据会保存到MAPFILE数组中
例 2.1
purpleEndurer @ bash ~ $ readarray
1 1 1
2 2 2
purpleEndurer @ bash ~ $ echo $REPLYpurpleEndurer @ bash ~ $ echo $MAPFILE
1 1 1
purpleEndurer @ bash ~ $ echo ${MAPFILE[*]}
1 1 1 2 2 2
purpleEndurer @ bash ~ $ echo ${MAPFILE[0]}
1 1 1
purpleEndurer @ bash ~ $ echo ${MAPFILE[1]}
2 2 2
purpleEndurer @ bash ~ $
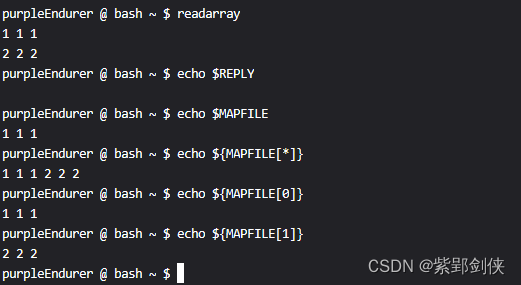
我们输入了1 1 1和2 2 2两行数据后,按Ctrl+D结束输入。
对于read命令,如果不指定用来存储数据的变量名,数据将保存在变量REPLY中。
但对于readarray命令,如果不指定用来存储数据的数组变量名,数据将保存到存储到MAPFILE数组中。
2.2 从标准输入读取数据并存储到指定的数组
例2.2 从标准输入读取两行数据并存储到指定的数组变量a
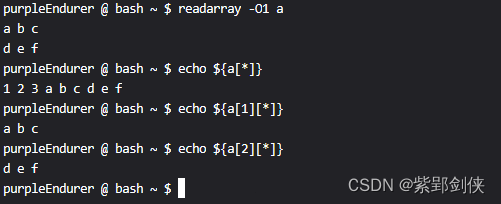
purpleEndurer @ bash ~ $ readarray a
1 2 3
4 5 6
purpleEndurer @ bash ~ $ echo $a
1 2 3
purpleEndurer @ bash ~ $ echo ${a[*]}
1 2 3 4 5 6
purpleEndurer @ bash ~ $ echo ${a[0][*]}
1 2 3purpleEndurer @ bash ~ $ echo ${a[1][*]}
4 5 6
purpleEndurer @ bash ~ $

我们输入了 1 2 3和4 5 6两行数据,可以看到数据存储到数组变量a中。
系统默认从数组下标0开始存储,所以命令执行的结果如下:
a[0][0]=1 a[0][1]=2 a[0][2]=3
a[1][0]=4 a[1][1]=5 a[1][2]=6
2.3 使用 -O 选项指定起始下标
例 2.3.1 在例2.2的基础上,我们继续从标准输入读取两行数据并存储到指定的数组a,起始下标为1
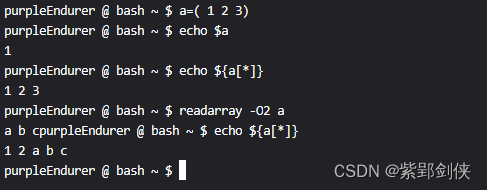
purpleEndurer @ bash ~ $ readarray -O1 a
a b c
d e f
purpleEndurer @ bash ~ $ echo ${a[*]}
1 2 3 a b c d e f
purpleEndurer @ bash ~ $ echo ${a[1][*]}
a b c
purpleEndurer @ bash ~ $ echo ${a[2][*]}
d e f
purpleEndurer @ bash ~ $
我们输入了a b c和d e f 两行数据。由于我们指定从下标1开始,
所以二维数组a的第一行数据没有变化
二维数组a的第二行数据变成 [a b c]
[d e f]则变成了二维数组a的第三行的数据。
这时的二维数组a的值为:
a[0][0]=1 a[0][1]=2 a[0][2]=3
a[1][0]=a a[1][1]=b a[1][2]=c
a[2][0]=d a[2][1]=e a[2][2]=f
可见,对于二维数组来说,-O指定的是起始行数。
那么,对于一维数组呢?-O指定的是什么呢?
我们通过下面的例子来看一下。
例2.3.2 先定义一维数组a并初始化其值为1 2 3,然后用readarray命令读取数据 a b c,并指定从数组a的下标2开始存储。
purpleEndurer @ bash ~ $ a=( 1 2 3)
purpleEndurer @ bash ~ $ echo $a
1
purpleEndurer @ bash ~ $ echo ${a[*]}
1 2 3
purpleEndurer @ bash ~ $ readarray -O2 a
a b cpurpleEndurer @ bash ~ $ echo ${a[*]}
1 2 a b c
purpleEndurer @ bash ~ $
注意:
在输入a b c后要按Ctrl+D两次,这样可以让数组a保持为一维数组。
如果按下了Enter键,数组a将变成二维数组。
可以看到,对于一维数组来说,-O选项指定的是元素的下标。
例2.3.3 不使用-O选项,指定数组名中原有数据会先被清空
purpleEndurer @ bash ~ $ readarray a
1
2
3
4purpleEndurer @ bash ~ $ echo ${a[*]}
1 2 3 4
purpleEndurer @ bash ~ $ readarray a
a
b
purpleEndurer @ bash ~ $ echo ${a[*]}
a b
purpleEndurer @ bash ~ $
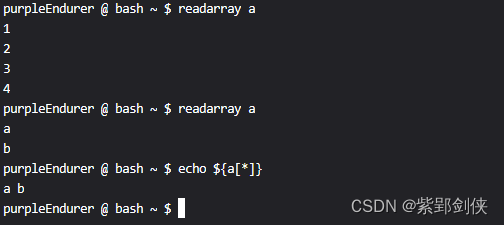
在第一次执行 readarray a 命令时,我们输入的数据1、2、3、4被存储到数据变量a中。
在第二次执行 readarray a 命令时,我们输入的数据a、b被存储到数据变量a中,原来的数据1、2、3、4被清空了。
2.4 用-n指定有效行数
例 2.4 从标准输入读取2行数据,储存到数组变量a。
purpleEndurer @ bash ~ $ echo $a
purpleEndurer @ bash ~ $ readarray -n 2 a
1 1 1
2 2 2
purpleEndurer @ bash ~ $ echo ${a[*]}
1 1 1 2 2 2
purpleEndurer @ bash ~ $ echo ${a[1]}
2 2 2
purpleEndurer @ bash ~ $ echo ${a[0]}
1 1 1
purpleEndurer @ bash ~ $


可以看到,我们输入两行数据后,readarray命令就自动停止输入,并将我们输入的数据存储到数组变量a中。
2.5 用-s来路过部分数据
例 2.5 跳过标准输入中的前2行数据,将后续的数据存储到数组变量a中。
purpleEndurer @ bash ~ $ echo $a
purpleEndurer @ bash ~ $ readarray -s 2 a
1 1 1
2 2 2
3 3 3
4 4 4
purpleEndurer @ bash ~ $ echo ${a[*]}
3 3 3 4 4 4
purpleEndurer @ bash ~ $ echo ${a[1]}
4 4 4
purpleEndurer @ bash ~ $ echo ${a[0]}
3 3 3
purpleEndurer @ bash ~ $

我们输入了1 1 1 、2 2 2、3 3 3、4 4 4四行数据,由于-s 2 选项,前两行数据1 1 1 、2 2 2被跳过,数组变量a存储的数据是3 3 3、4 4 4,即:
a[0][0]=3 a[0][1]=3 a[0][2]=3
a[1][0]=4 a[1][1]=4 a[1][2]=4
2.6 用-c和-C选项使用回调程序
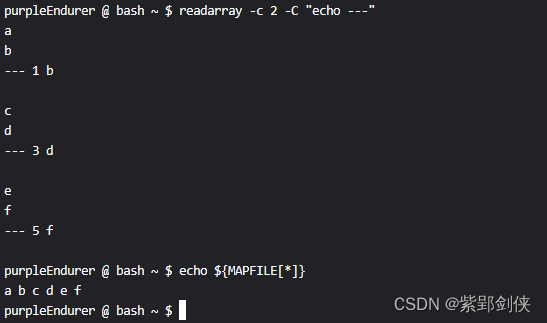
例 2.6 从标准输入读取数据,每读入2行数据就调用echo命令显示字符串---
purpleEndurer @ bash ~ $ readarray -c 2 -C "echo ---"
a
b
--- 1 bc
d
--- 3 de
f
--- 5 fpurpleEndurer @ bash ~ $ echo ${MAPFILE[*]}
a b c d e f
purpleEndurer @ bash ~ $
2.7 使用输出重定向和-t选项从磁盘文件中读取数据
例2.7.1 利用seq命令创建数据文件d.txt,然后利用readarray和输入重定向将数据文件d.txt的内容存储到数组变量a
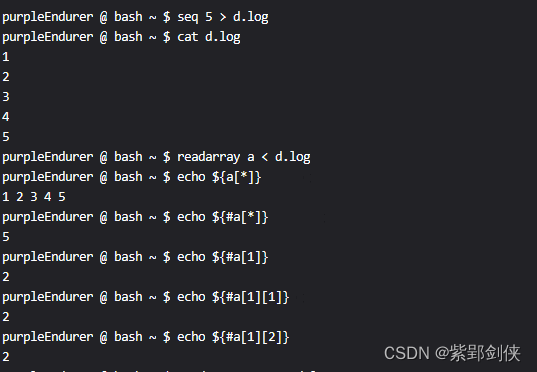
purpleEndurer @ bash ~ $ seq 5 > d.log
purpleEndurer @ bash ~ $ cat d.log
1
2
3
4
5
purpleEndurer @ bash ~ $ readarray a < d.log
purpleEndurer @ bash ~ $ echo ${a[*]}
1 2 3 4 5
purpleEndurer @ bash ~ $ echo ${#a[*]}
5
purpleEndurer @ bash ~ $ echo ${#a[1]}
2
purpleEndurer @ bash ~ $ echo ${#a[1][1]}
2
purpleEndurer @ bash ~ $ echo ${#a[1][2]}
2
例2.7.2 在使用输入重定向和readarray -t 命令从例2.7.1创建的d.txt文件读取数据存储到数组变量a
purpleEndurer @ bash ~ $ readarray -t a < d.log
purpleEndurer @ bash ~ $ echo ${a[*]}
1 2 3 4 5
purpleEndurer @ bash ~ $ echo ${#a[*]}
5
purpleEndurer @ bash ~ $ echo ${#a[1][1]}
1
purpleEndurer @ bash ~ $ echo ${#a[1][2]}
1purpleEndurer @ bash ~ $ echo ${#a[1]}
1
purpleEndurer @ bash ~ $
从 echo ${a[*]} 和 echo ${#a[*]} 的命令执行结果来看,readarray a < d.log 和 readarray -t a < d.log 执行的结果似乎是一样的。
但从echo ${#a[1]}、echo ${#a[1][1]}、echo ${#a[1][2]}命令的执行结果看,readarray a < d.log 和 readarray -t a < d.log 执行的结果是不一样的。
这是因为readarray a < d.log 没有过滤换行符。
3 mapfile命令
mapfile命令不仅在功能上和readarray命令相同,而且在命令格式上也和readarray命令相同。
但是mapfile命令的帮助信息比readarray命令要详细得多。
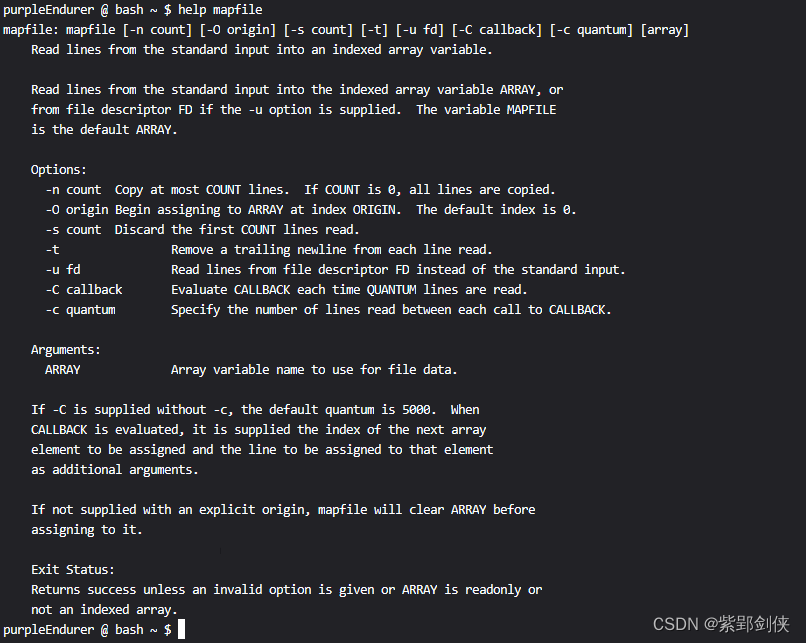
purpleEndurer @ bash ~ $ help mapfile
mapfile: mapfile [-n count] [-O origin] [-s count] [-t] [-u fd] [-C callback] [-c quantum] [array]
Read lines from the standard input into an indexed array variable.
Read lines from the standard input into the indexed array variable ARRAY, or
from file descriptor FD if the -u option is supplied. The variable MAPFILE
is the default ARRAY.
Options:
-n count Copy at most COUNT lines. If COUNT is 0, all lines are copied.
-O origin Begin assigning to ARRAY at index ORIGIN. The default index is 0.
-s count Discard the first COUNT lines read.
-t Remove a trailing newline from each line read.
-u fd Read lines from file descriptor FD instead of the standard input.
-C callback Evaluate CALLBACK each time QUANTUM lines are read.
-c quantum Specify the number of lines read between each call to CALLBACK.
Arguments:
ARRAY Array variable name to use for file data.
If -C is supplied without -c, the default quantum is 5000. When
CALLBACK is evaluated, it is supplied the index of the next array
element to be assigned and the line to be assigned to that element
as additional arguments.
If not supplied with an explicit origin, mapfile will clear ARRAY before
assigning to it.
Exit Status:
Returns success unless an invalid option is given or ARRAY is readonly or
not an indexed array.
purpleEndurer @ bash ~ $
这篇关于Linux shell编程学习笔记37:readarray命令和mapfile命令的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




