本文主要是介绍reids的其他功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 慢查询
- 生命周期
- 两个配置
- slowlog-max-len
- slowlog-log-slower-than
- 配置方法
- 三个命令
- 运维经验
- pipeline
- 什么是流水线
- 如何使用客户端实现流水线
- 与原生的操作对比
- 使用建议
- 发布订阅
- 角色
- 模型
- API
- publish
- subscribe
- unsubscribe
- 其他API
- 消息队列
- 发布订阅和消息队列的对比
- Bitmap
- 位图
- 相关命令
- 独立用户统计
- HyperLogLog
- GEO
慢查询
生命周期
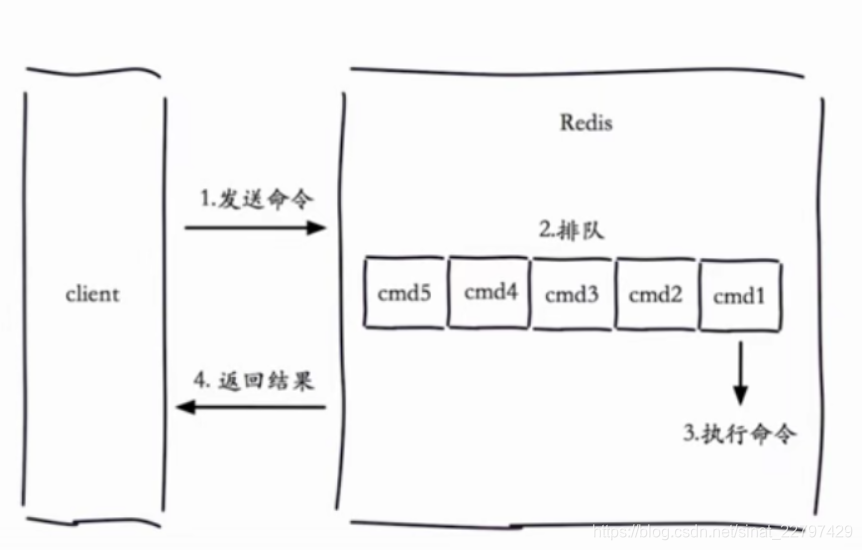
说明:
- 慢查询是发生在第3阶段
- 客户端超时不一定是慢查询、但慢查询是客户端超时的一个可能因素
两个配置
slowlog-max-len
- 慢查询是一个先进先出的队列
- 而且这个队列是一个固定长度的
- 保存在内存中(当redis重启之后就会消失了)
slowlog-log-slower-than
- 慢查询阈值(单位:微妙)
- slowlog-log-slower-than=0 ,记录所有命令
- slowlog-log-slower-than<0,不记录任何命令
配置方法
- 默认值
- config get slowlog-max-len=128
- config get slowlog-log-slower-than = 10000
- 修改配置文件重启
- 动态配置
- config set slowlog-max-len 1000
- config set slowlog-log-slower-than 1000
三个命令
- slowlog get[n] : 获取慢查询队列,n是可选参数,比如n=10条,就是获取10条慢查询
- slowlog len: 获取慢查询队列的长度
- slowlog reset: 清空慢查询队列
运维经验
- slowlog-max-len :不要设置过大,默认10ms,通常设置1ms(根据你的QPS来决定你的阈值的大小)
- slowlog-log-slower-than: 队列的长度不要设置的过小,通常设置1000左右。
- 理解命令生命周期
- 定期持久化慢查询(可以定期的存在如MySQL中,就可以查看慢查询的执行了,这样对于分析问题是非常有帮助的)
pipeline
什么是流水线
1次时间 = 1次网络时间 + 1次命令时间(命令时间往往比较快的,通常是)
1次pipeline(n条命令) = 1次网络时间 + n次命令时间(这就是流水线)
注意:
- Redis的命令时间是微妙级别的
- pipeline每次条数要控制(网络)
如何使用客户端实现流水线
首先引入java包:
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>2.9.0</version><type>jar</type><scope>compile</scope>
</dependency>
与原生的操作对比
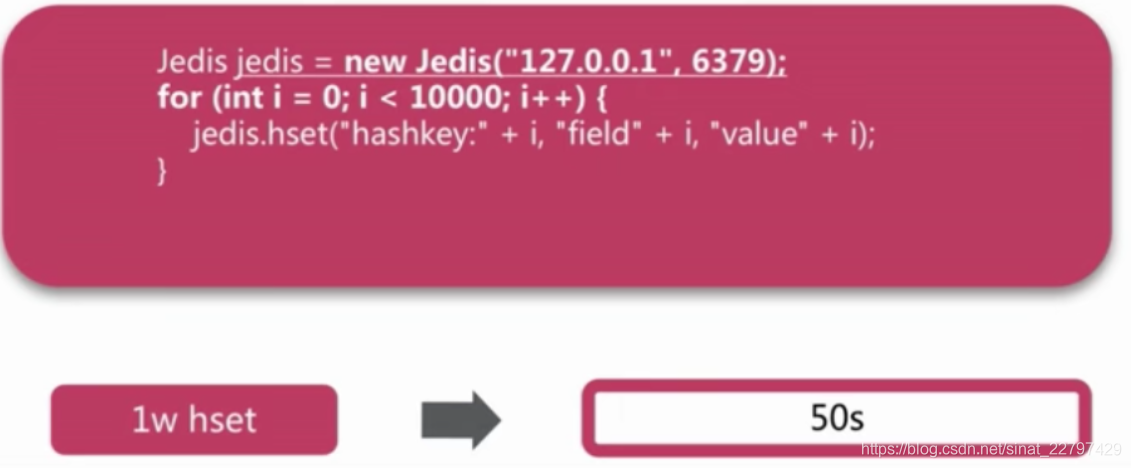
- 没有使用pipeline
由于它的key值不一样,所以不能简单的使用mset操作,在单纯的使用原生的hset操作情况下,执行10000次命令需要50s
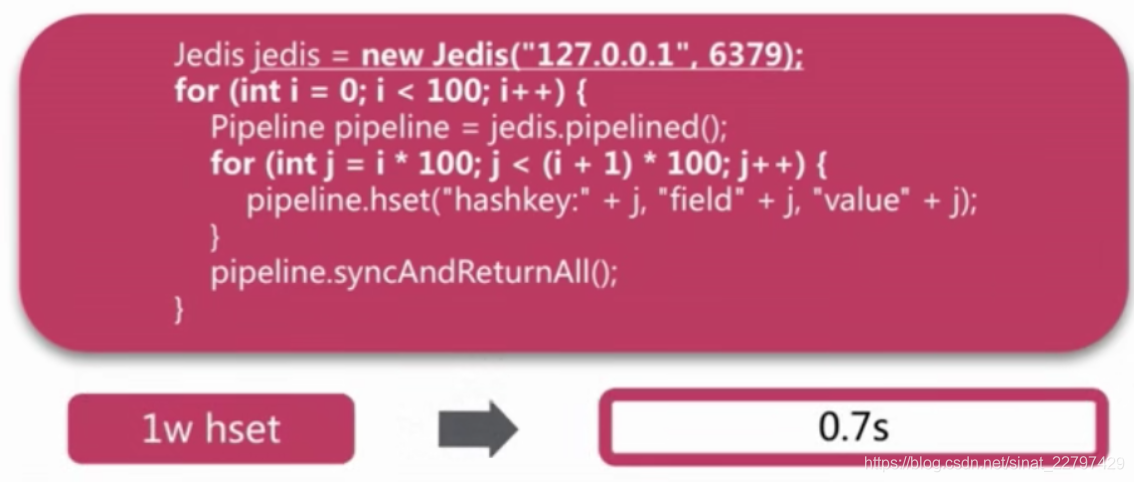
- 使用了pipeline
如果我们使用了pipeline进行拆分,一次pipeline执行100条命令,可以将我们之前10000次命令降为100次,因此我们只需要100次网络时延,只需要0.7秒。
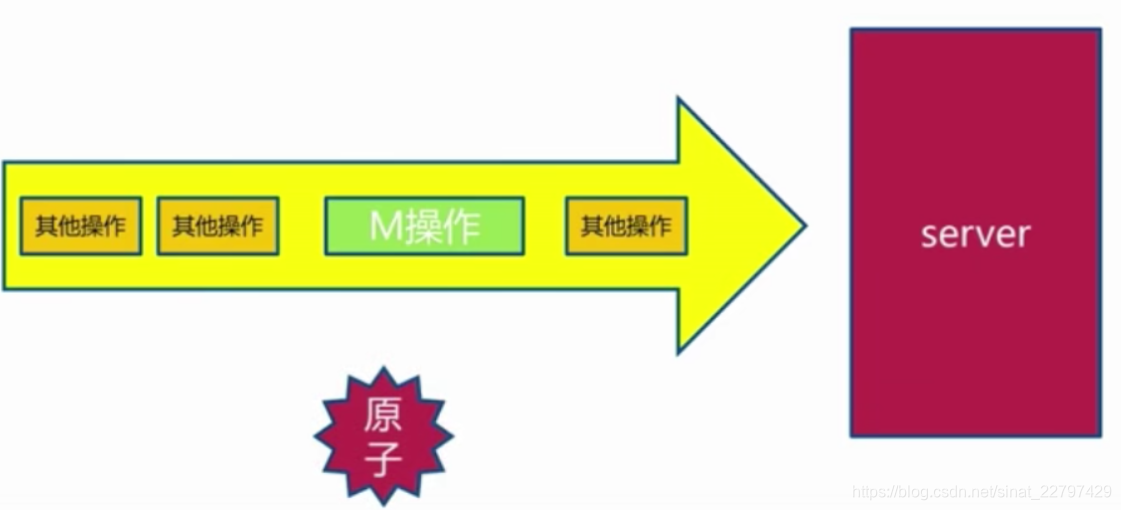
pipeline与原生M操作对比
m操作属于原子操作,而pipeline是非原子操作,但是它的返回是按之前顺序的,如下图:
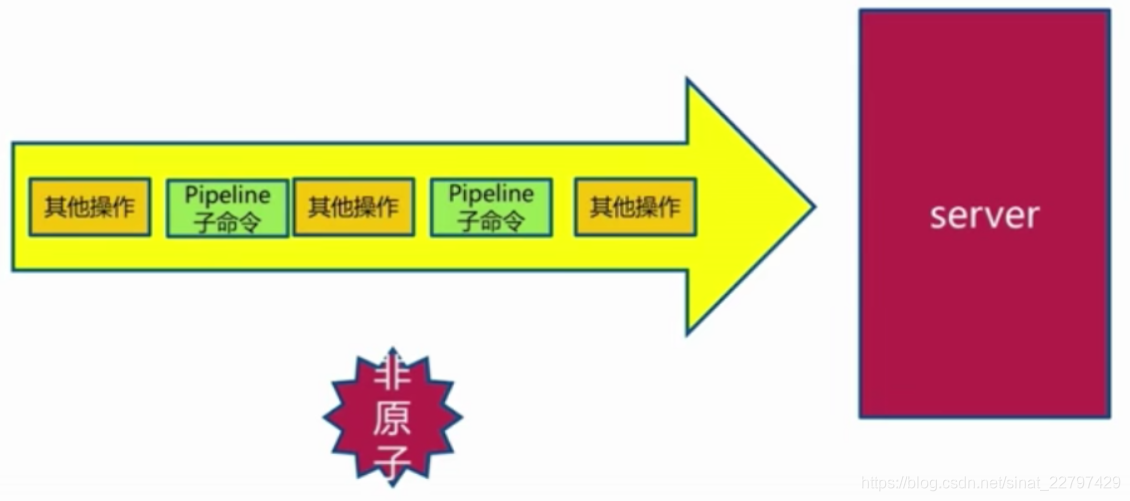
使用建议
- pipeline可以提高我们的并发效率,但是并不能无节制的去使用,因此需要注意每次pipeline携带的数据量(数据量大我们可以执行批量操作,例如10000条,我们拆分为每次100条,执行100次)
- pipeline只能作用于一个redis节点上(pipeline是不允许使用在多个redis节点上的)
- 需要清楚M操作和pipeline的区别
发布订阅
角色
主要分为三种:
- 发布者(publisher)
- 订阅者(subscriber)
- 频道(channel)
模型
发布订阅模型:
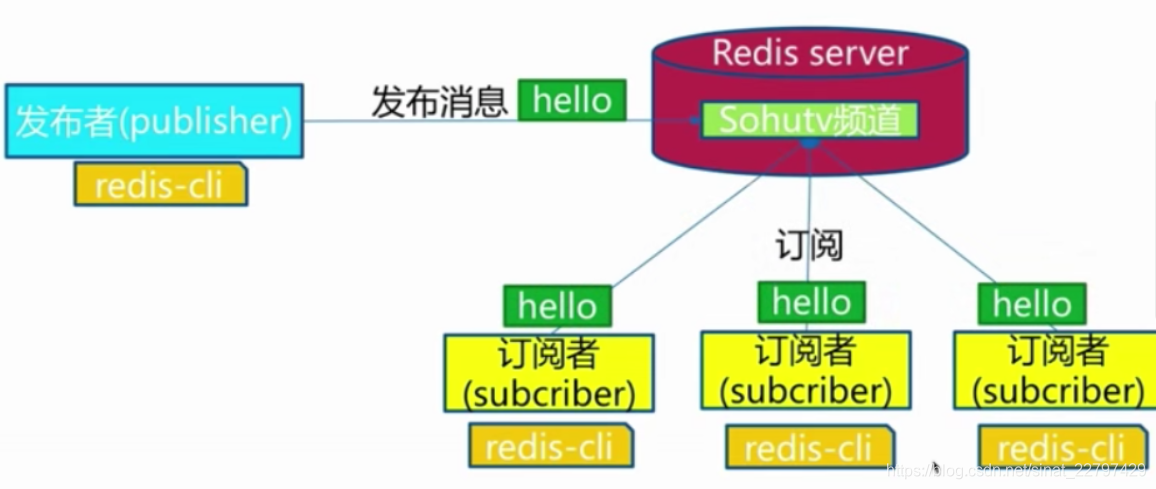
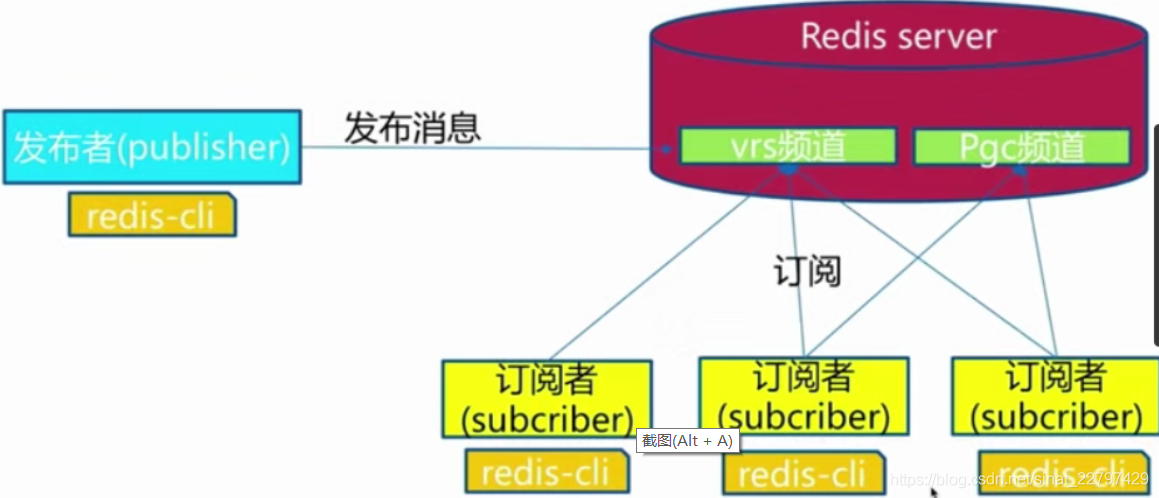
注意:
假如一个发布者发布一条消息到频道了,但是我一个新的订阅者去订阅这个频道,它是收不到之前的消息的,这个需要注意一下,无法去做一个消息的堆积。
API
对应的API主要为publish、subscribe、unsubscribe、其他功能
publish
publish channel message
例如:publish sohu:tv “hello world”
(integer) 3 #订阅者数
publish sohu:auto “taxi”
(integer)
subscribe
subscribe [channel] 一个或者多个
unsubscribe
unsubscribe [channel] 一个或多个
unsubscribe sohu:tv
其他API
- psubscribe [pattern…] 订阅模式
- punsubscribe [pattern…] 退订指定的模式
- pubsub channels 列出至少有一个订阅者的模式
- pubsub numsub [channel…] 列出给定频道的订阅者数量
消息队列
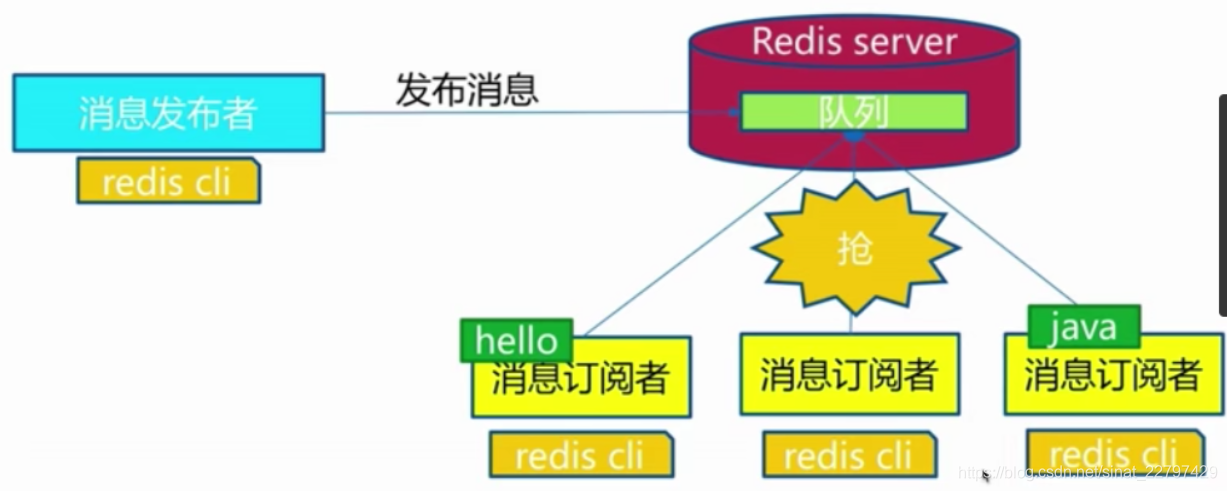
发布订阅和消息队列的对比
发布订阅特点: 发布消息之后,其他所有的订阅者都能收到信息
消息队列: 它是一个抢的功能,发送一个hello,只有一个消息订阅者可以收到,因为它是一个抢的功能,而且redis也没提供这样的功能,就是说它有一个东西叫做消息队列,它是使用list来实现,它是使用一个阻塞的这样去拉,然后大家去抢这样一个东西。
都收到用发布订阅模式,只有一个收到用消息队列。
Bitmap
bitmap实际上就是我们俗称的位图
位图
redis是可以直接操作位的
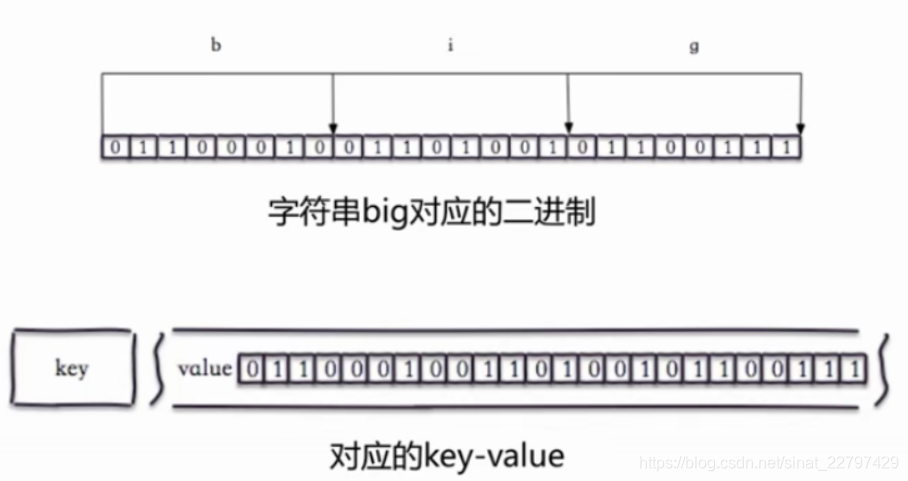
相关命令
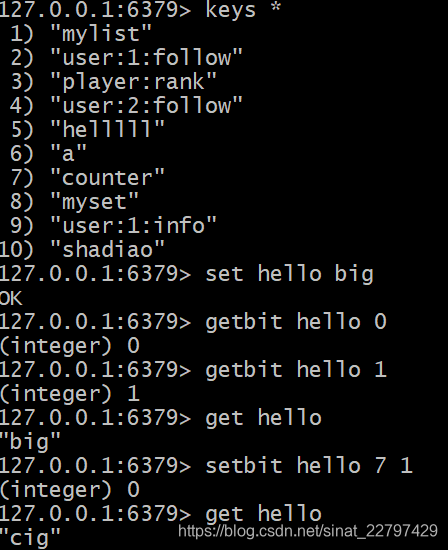
setbit
- setbit key offset vlaue: 给位图指定索引设置值
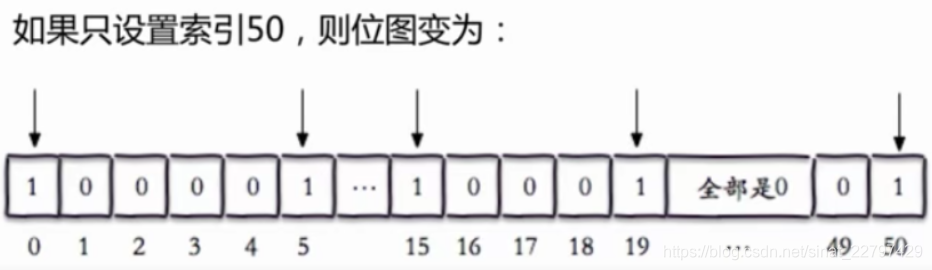
setbit的偏移量不要设置过大,这样设置会引起一些问题,如下,如果中间全部都是0,偏移量一下子跳到了50,可能会引起一些问题(redis是单线程的)
getbit - getbit key offset vlaue: 获取位图指定索引的值
bitcount - bitcount key [start end]: 获取位图指定范围(start到end,单位为字节,如果不指定就是获取全部)位值为1的个数
bittop - bittop op destkey key[key…]:
做多个Bitmap的and(交集)、or(并集)、not(非)、xor(异或)操作并将结果保存到destkey中
bitpos - bitpos key targetBit[start][end]
计算位图指定范围(start到end,单位为字节,如果不指定就是获取全部)第一个偏移量对应的值等于targetBit的位置
独立用户统计
问题: 某网站有1亿用户,每天有5千万独立用户去访问,使用set和Bitmap进行对比?
| 数据类型 | 每个userId占用的空间 | 需要存储的用户量 | 全部内存 |
|---|---|---|---|
| set | 32位(假设userId用的是整形,实际很多网站用的是长整形) | 50,0000,000 | 32位*50,0000,000=200MB |
| Bitmap | 1位 | 100,000,000 | 1位*100,000,000=12.5MB |
我们来看一下一年之后的对比:
| 数据类型 | 一天 | 一个月 | 一年 |
|---|---|---|---|
| set | 200MB | 6G | 72G |
| Bitmap | 12.5MB | 375M | 4.5G |
HyperLogLog
GEO
参考: https://github.com/nuptkwz/notes/tree/master/technology/redis
这篇关于reids的其他功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






