本文主要是介绍reed solomon编码实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果大家对于raid原理有所了解的话,对于这个reed solomon(里德-所罗门码)编码就不陌生。下简单介绍原理
第一步先通过Vandermonde 矩阵编码,如下
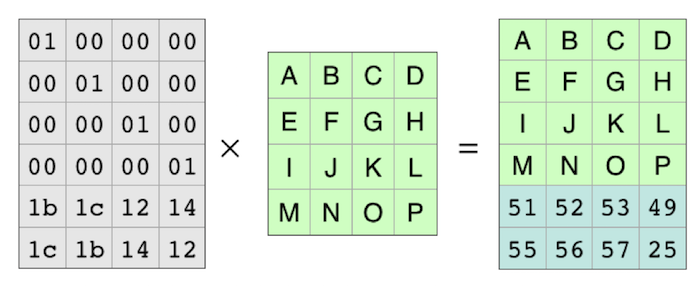
这样原始的ABCD-MNOP的数据就被编码了。此时选用的parity格式是2,那么允许丢失2行数据,如下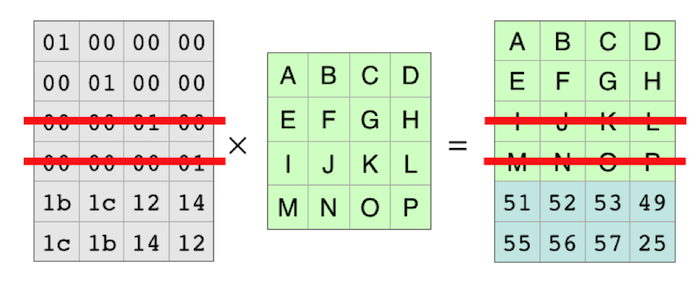
现在通过对Vandermonde矩阵的逆矩阵相乘得到原始的数据,如下: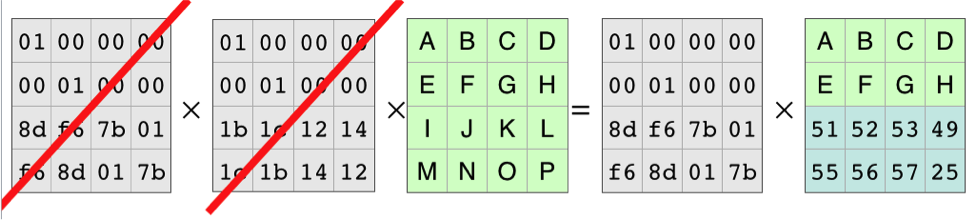
这个就是演示了一个数据恢复的原理了。
说完原理还是code实践一下吧,这个编码已经有大神实现了,拿来主义。reed-solomon
先看怎么编码:
func main() {// Parse command line parameters.flag.Parse()args := flag.Args()if len(args) != 1 {fmt.Fprintf(os.Stderr, "Error: No input filename given\n")flag.Usage()os.Exit(1)}if *dataShards > 257 {fmt.Fprintf(os.Stderr, "Error: Too many data shards\n")os.Exit(1)}fname := args[0]// Create encoding matrix.enc, err := reedsolomon.NewStream(*dataShards, *parShards)checkErr(err)fmt.Println("Opening", fname)f, err := os.Open(fname)checkErr(err)instat, err := f.Stat()checkErr(err)shards := *dataShards + *parShardsout := make([]*os.File, shards)// Create the resulting files.dir, file := filepath.Split(fname)if *outDir != "" {dir = *outDir}for i := range out {outfn := fmt.Sprintf("%s.%d", file, i)fmt.Println("Creating", outfn)out[i], err = os.Create(filepath.Join(dir, outfn))checkErr(err)}// Split into files.data := make([]io.Writer, *dataShards)for i := range data {data[i] = out[i]}// Do the spliterr = enc.Split(f, data, instat.Size())checkErr(err)// Close and re-open the files.input := make([]io.Reader, *dataShards)for i := range data {out[i].Close()f, err := os.Open(out[i].Name())checkErr(err)input[i] = fdefer f.Close()}// Create parity output writersparity := make([]io.Writer, *parShards)for i := range parity {parity[i] = out[*dataShards+i]defer out[*dataShards+i].Close()}// Encode parityerr = enc.Encode(input, parity)checkErr(err)fmt.Printf("File split into %d data + %d parity shards.\n", *dataShards, *parShards)}先是打开原始文件,对数据进行分配,先enc.Split做数据切片,然后编码parity通过enc.Encode。我这里面制定4个分片和3个parity,结果如下:
Opening /mnt/download/kubernetes.tar.gz
Creating kubernetes.tar.gz.0
Creating kubernetes.tar.gz.1
Creating kubernetes.tar.gz.2
Creating kubernetes.tar.gz.3
Creating kubernetes.tar.gz.4
Creating kubernetes.tar.gz.5
Creating kubernetes.tar.gz.6
File split into 4 data + 3 parity shards.当然删除任何3个都是可以恢复的
下面是decode代码
func main() {// Parse flagsflag.Parse()args := flag.Args()if len(args) != 1 {fmt.Fprintf(os.Stderr, "Error: No filenames given\n")flag.Usage()os.Exit(1)}fname := args[0]// Create matrixenc, err := reedsolomon.NewStream(*dataShards, *parShards)checkErr(err)// Open the inputsshards, size, err := openInput(*dataShards, *parShards, fname)checkErr(err)// Verify the shardsok, err := enc.Verify(shards)if ok {fmt.Println("No reconstruction needed")} else {fmt.Println("Verification failed. Reconstructing data")shards, size, err = openInput(*dataShards, *parShards, fname)checkErr(err)// Create out destination writersout := make([]io.Writer, len(shards))for i := range out {if shards[i] == nil {//dir, _ := filepath.Split(fname)outfn := fmt.Sprintf("%s.%d", fname, i)fmt.Println("Creating", outfn)out[i], err = os.Create(outfn)checkErr(err)}}fmt.Println("reconstruct")err = enc.Reconstruct(shards, out)if err != nil {fmt.Println("Reconstruct failed -", err)os.Exit(1)}// Close output.for i := range out {if out[i] != nil {err := out[i].(*os.File).Close()checkErr(err)}}shards, size, err = openInput(*dataShards, *parShards, fname)ok, err = enc.Verify(shards)if !ok {fmt.Println("Verification failed after reconstruction, data likely corrupted:", err)os.Exit(1)}checkErr(err)}// Join the shards and write themoutfn := *outFileif outfn == "" {outfn = fname}fmt.Println("Writing data to", outfn)f, err := os.Create(outfn)checkErr(err)shards, size, err = openInput(*dataShards, *parShards, fname)checkErr(err)// We don't know the exact filesize.err = enc.Join(f, shards, int64(*dataShards)*size)checkErr(err)
}func openInput(dataShards, parShards int, fname string) (r []io.Reader, size int64, err error) {// Create shards and load the data.shards := make([]io.Reader, dataShards+parShards)for i := range shards {infn := fmt.Sprintf("%s.%d", fname, i)fmt.Println("Opening", infn)f, err := os.Open(infn)if err != nil {fmt.Println("Error reading file", err)shards[i] = nilcontinue} else {shards[i] = f}stat, err := f.Stat()checkErr(err)if stat.Size() > 0 {size = stat.Size()} else {shards[i] = nil}}return shards, size, nil
}这个里面获取到的分片,首先是检查Verify分片是否完整,如果不完整会重建Reconstruct。
下面是例子
rm -rf kubernetes.tar.gz.1
rm -rf kubernetes.tar.gz.3
rm -rf kubernetes.tar.gz.5Opening /mnt/download/kubernetes.tar.gz.0
Opening /mnt/download/kubernetes.tar.gz.1
Error reading file open /mnt/download/kubernetes.tar.gz.1: no such file or directory
Opening /mnt/download/kubernetes.tar.gz.2
Opening /mnt/download/kubernetes.tar.gz.3
Error reading file open /mnt/download/kubernetes.tar.gz.3: no such file or directory
Opening /mnt/download/kubernetes.tar.gz.4
Opening /mnt/download/kubernetes.tar.gz.5
Error reading file open /mnt/download/kubernetes.tar.gz.5: no such file or directory
Opening /mnt/download/kubernetes.tar.gz.6
Verification failed. Reconstructing data
Opening /mnt/download/kubernetes.tar.gz.0
Opening /mnt/download/kubernetes.tar.gz.1
Error reading file open /mnt/download/kubernetes.tar.gz.1: no such file or directory
Opening /mnt/download/kubernetes.tar.gz.2
Opening /mnt/download/kubernetes.tar.gz.3
Error reading file open /mnt/download/kubernetes.tar.gz.3: no such file or directory
Opening /mnt/download/kubernetes.tar.gz.4
Opening /mnt/download/kubernetes.tar.gz.5
Error reading file open /mnt/download/kubernetes.tar.gz.5: no such file or directory
Opening /mnt/download/kubernetes.tar.gz.6
Creating /mnt/download/kubernetes.tar.gz.1
Creating /mnt/download/kubernetes.tar.gz.3
Creating /mnt/download/kubernetes.tar.gz.5
reconstruct
Opening /mnt/download/kubernetes.tar.gz.0
Opening /mnt/download/kubernetes.tar.gz.1
Opening /mnt/download/kubernetes.tar.gz.2
Opening /mnt/download/kubernetes.tar.gz.3
Opening /mnt/download/kubernetes.tar.gz.4
Opening /mnt/download/kubernetes.tar.gz.5
Opening /mnt/download/kubernetes.tar.gz.6
Writing data to /mnt/download/kubernetes.tar.gz
Opening /mnt/download/kubernetes.tar.gz.0
Opening /mnt/download/kubernetes.tar.gz.1
Opening /mnt/download/kubernetes.tar.gz.2
Opening /mnt/download/kubernetes.tar.gz.3
Opening /mnt/download/kubernetes.tar.gz.4
Opening /mnt/download/kubernetes.tar.gz.5
Opening /mnt/download/kubernetes.tar.gz.6
当decode的时候回重建数据。之所以介绍这个编码,是为后续编写对象存储做理论基础。
这篇关于reed solomon编码实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



