本文主要是介绍使用元类手撸orm框架,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:vk
链接:https://0vk.top/zh-hans/article/details/55/
来源:爱尚购(0vk.top)
何为ORM
ORM全称是:Object Relational Mapping(对象关系映射),其主要作用是在编程中,把面向对象的概念跟数据库中表的概念对应起来。举例来说就是,我定义一个对象,那就对应着一张表,这个对象的实例,就对应着表中的一条记录。
这里模拟一段用来用户注册用的代码,sign_up函数的功能即为实现用户注册
views.py
from my_models import Userdef sign_up():u = User(id=1,name='vk', age=22)u.save()print('成功注册用户')sign_up()
先不用管内部是怎么实现的,可以看到表User中新建了一条id为1,name=vk,age=22,的数据。上面代码中u = User(id=1,name='vk', age=22) 只需要设置参数即可实现插入数。
这就成功实现了对象关系映射即orm。不需要手写一条sql语句即可非常简便的操作数据库
字段设计
数据库中有整型,字符串型,这个字段的值是否唯一等各种属性,那么orm中也应该设计出对应的字段。为了方便管理,我们新建一个py文件my_models 。在这个文件里定义我们需要设计的数据字段
my_models .py
import modelsclass User(models.Model):id = models.IntegerField('id')name = models.CharField('name')age = models.IntegerField('age')现在,这个类就和数据库完美对应起来了,类名=表名,类属性=字段名。还可以设置这个字段是属于整型还是字符串型。
新建一个叫fields.py的py文件,用来定义各种类型的字段。目前目录是这样的
C:.
│ fields.py
│ my_models.py
│ views.pyfields.py
class Field:def __init__(self, name: str, column_type):self.name = nameself.column_type = column_typeclass CharField(Field):def __init__(self, name):super(CharField, self).__init__(name, 'varchar')def check(self, value):if isinstance(value, str):return str(value)else:raise TypeError('a varchar type is required not ":%s"'%value)class IntegerField(Field):def __init__(self, name):super(IntegerField, self).__init__(name, 'int')def check(self, value):if isinstance(value, int):return int(value)else:raise TypeError('an int type is required not %s'%value)__all__ = ['CharField', 'IntegerField', 'Field']
逻辑解析
每个字段肯定有它的名字,类型。所以在父类Field中定义两个初始值name ,column_type 。各个具体的字段继承这个Field,为了检查输入值是否合法,给子类中加入check函数。这样就不会存在定义了一个IntegerField结果传入了一个字符串类型的值这种问题了。
最后一行__all__是为了优化使用者的体验,比如:from xxx import * ,如果在xxx里自定义 了__all__那么其他使用的人使用时只会导入all中定义的东西。
mro和super()
子类__init__中的super(CharField, self).__init__(name, 'varchar'),会根据mro机制寻找到上一个类的init参数。
所谓MRO即Method Resolution Order(方法解析顺序),即在调用方法时,会对当前类以及所有的基类进行一个搜索,以确定该方法之所在,而这个搜索的顺序就是MRO。Python 类是支持(多)继承的,一个类的方法和属性可能定义在当前类,也可能定义在基类。
针对这种情况,当调用类方法或类属性时,就需要对当前类以及它的基类进行搜索,以确定方法或属性的位置,而搜索的顺序就称为方法解析顺序。最近的版本中用的是c3算法,感兴趣的可以自己了解一下。
我们将CharField这个类的mro打印出来可以看到,CharField的mro中上一个就是Field。所以这句话就是找到父类的__init__并且传入了两个参数name,和'varchar'。这个name是变量我们在my_models.py设计字段时传入的参数。

其实在类内部的话可以直接将super(CharField, self).__init__()写为super().__init__(),python会帮我们自动找到。
super()不是函数,也不是一个python内置方法,它是一个类
不光是在类里面继承时用super().__init()这种,你可以在任何地方使用它,因为使用它的过程无非就是实例化一个类罢了。
字段设计已经成功实现,现在最主要的来了,如何实现sql语句与相应方法的对应。我们拿插入举例
元类实现models
新建一个叫models.py的py文件,里面用来存放实现具体的sql语句,并且在db.sqlite3新建一个叫user的表,因为我们演示的是插入,其他功能暂未实现
import sqlite3conn = sqlite3.connect('db.sqlite3')## 创建一个表 - User
conn.execute('''CREATE TABLE company(ID INT PRIMARY KEY NOT NULL,NAME TEXT NOT NULL,AGE INT NOT NULL);''')conn.close()现在的的目录是这样的
C:.
│ db.sqlite3
│ fields.py
│ models.py
│ my_models.py
│ views.py完整代码
先上代码然后再一步一步解析其中的逻辑
models.py
from fields import __all__ as fields_all
from fields import *import sqlite3conn = sqlite3.connect('db.sqlite3')# ## 创建一个表 - User
# conn.execute('''CREATE TABLE company
# (ID INT PRIMARY KEY NOT NULL,
# NAME TEXT NOT NULL,
# AGE INT NOT NULL);''')
#class ModelMetaclass(type):def __new__(cls, name, bases, attrs):mapping = {}for k, v in attrs.items():if isinstance(v, Field):mapping[k] = vfor k in mapping.keys():attrs.pop(k)attrs['__mapping__'] = mappingattrs['__table__'] = namereturn type.__new__(cls, name, bases, attrs)class Model(metaclass=ModelMetaclass):def __init__(self, **kw):print(self.__mapping__)self.args = kwsuper(Model, self).__init__()def __getattr__(self, key):raise AttributeError(r"'Model' object has no attribute '%s'" % key)def save(self):fields = []args = []for k, v in self.__mapping__.items():fields.append(k)value = v.check(self.args[k])args.append(value)for i in range(len(args)):if isinstance(args[i],str):args[i]="'"+args[i]+"'"else:args[i]=str(args[i])conn.execute(f"insert into {self.__table__} ({ ','.join(fields)}) values ({','.join(args)})")conn.commit()conn.close()__all__ = fields_all + ['Model']元类
首先来看python中如何定义一个类:
class A:pass这样我们就可以静态的定义一个最简单的类A了,除此之外,还可以动态的定义一个类A,使用type来生产一个新的A
A=type("A",(),{})我们最常用的type方法是源码 注释中的第二种,返回object's type。

a='1'
print(type(a))
<class 'str'>如果有一天,我们不喜欢这个type生产出来的类了,想要自定义一种生产方式,用函数v生产。
想象一下面向对象中想要有一个类的功能而且还要自定义一部分该怎么做?
没错,继承!只需要将这个类V继承type,就可以既有它的功能又可以拓展了
class V(type):pass
A=V("A",(),{})上面这个是动态生成类A的写法,静态生成是这么写的:
class V(type):pass
class A(metaclass=V):pass所以,有啥用呢?
我们知道,__new__这个魔法方法是在__init__之前执行的,在object被创造出来之前就执行了,这么说,其实是可以通过new来充当A生命周期的钩子,类似于vue中的beforeCreate等钩子函数
class V(type):def __new__(cls, name, bases, attrs):print(cls,name,bases,attrs)return type.__new__(cls, name, bases, attrs)class A(metaclass=V):def do():pass
A()
#结果
<class '__main__.V'> A () {'__module__': '__main__', '__qualname__': 'A', 'do': <function A.do at 0x0000017E6E5F7D00>}可以看到,在A被创建之前,我们是可以通过元类获取到它的一些信息的,比如类名,类属性等。这样就可以进行相应的操作了,比如:我想让我的v这个元类生成出来的类中的函数名字不包含数字,只需要判断attrs函数名字就行,包含数字主动raise 一个错误。
class V(type):def __new__(cls, name, bases, attrs):for i in attrs.keys():print(i)if i.isalnum():raise TypeError('类型错误')return type.__new__(cls, name, bases, attrs)class A(metaclass=V):def do1():pass
A()
需要用元类的场景
一个比较常见的场景就是,当继承无法简单解决问题的时候需要用元类,而继承无法解决问题的很多时候就是你写一个框架给别人用的时候,而你都到写自己框架并且继承无法解决的时候了,那么这时候你肯定是个大佬。
所以Tim Peters说
Metaclasses are deeper magic than 99% of users should ever worry about. If you wonder whether you need them, you don’t (the people who actually need them know with certainty that they need them, and don’t need an explanation about why). - Tim Peters
元类是更深的魔法比99的用户应该担心过。如果你想知道是否你需要他们,你不(真正需要的人肯定地知道,他们需要他们,不需要解释为什么)。--彼特斯
这个Tim Peters就是写python之禅 的人。还是相当牛逼的人物

元类实现ORM
回到我们的orm框架,在my_models.py这里

继承了models,我们想在user类生成的时候知道id = models.IntegerField('id'),这里引用的字段是什么类型。显然它用继承完成不了。但是可以在元类里__new__中的参数获取了

可以清楚的看到字段的类型,name。还有类的名字也就是表的名字User。
接下来只需要给但凡是ModelMetaclass这个元类生成的类添加两个属性:mapping和table分别记录字段对应的类型和表名。
attrs['__mapping__'] = mappingattrs['__table__'] = name这个元类生成的类Model中,只需要常规的用获取属性值的方法self.__mapping__就可以获取到。字段对应的关系
属性解决了,传入的值(1,'vk,22)就好办了
u = User(id=1,name='vk', age=22)
在Model初始化的时候就传入参数即可

取出想要的值简单拼接一下即可生成想要的sql语句
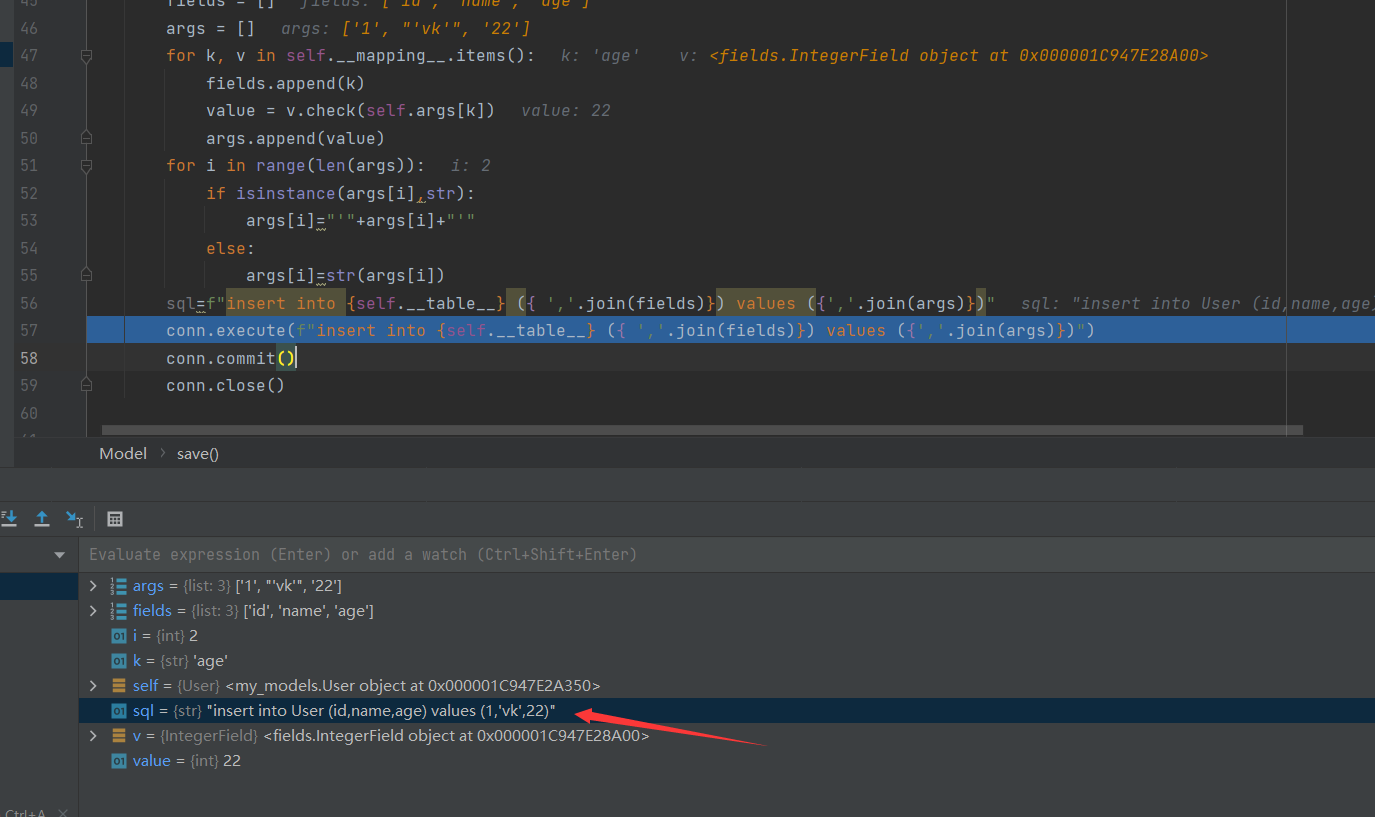
但是在真正使用的时候不要sql=xxx这种拼接,有可能会出现sql注入。
不了解的可以看这里:SQL注入
单词数:534字符数:6590
这篇关于使用元类手撸orm框架的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





