本文主要是介绍mysql 申花球队面试题_Mysql基础知识,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Mysql基础总结(部分参照燕十八老师的教学)
1. 什么是SQL(Structured Query Language)结构查询语句
SQL语句是一种what型语言【想要什么,给你】,语法相对简单易懂
SQL语言的划分
DDL(Data Definition Language)-数据库定义语言;用来定义数据库对象、数据表和列;使用DDL创建、删除、修改数据库的表和结构
DML(Data Manipulation Language)-数据库操作语言;操作数据库的相关数据,比如增加、删除、修改表中的数据
DCL(Data Control Language)-数据控制语言;用它来定义访问权限和安全等级
DQL(Data Query Language)-数据查询语言;数据查询语言,用来查询数据
SQL语句的执行顺序
select distinct player_id , player_name , count(*) as num # 顺序5
from player join team on player.team_id = team.team_id # 顺序1
where height > 1.80 # 顺序2
group by player.team_id # 顺序3
having num >2 # 顺序4
order by num desc # 顺序6
limit 2; # 顺序7
完整的顺序是
from子句组装数据(包括join)
where子句进行条件筛选
group by分组
使用聚集函数进行计算、数据映射
having筛选分组
计算所有的表达式
select的字段
order by排序
limit筛选
SQL语句的执行流程
?Mysql中的流程:SQL语句 → 缓存查询 → 解析器 → 优化器 → 执行器
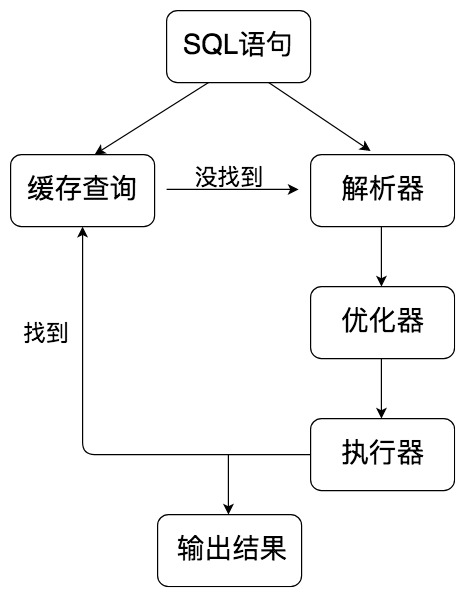
查询缓存:Server如何在查询缓存总发现了这条SQL语句,就会直接将结果返回给客户端;如果没有,就进入到解析器阶段。需要说明的是,因为查询缓存往往效率不高,所以在Mysql 8.0 之后就抛弃了这个功能。
解析器:在解析器中队SQL语句进行语法分析、语义分析
优化器:在优化器中会确定SQL语句的执行路径,比如是根据全表检索,还是根据索引来检验等
执行器:在执行之前需要判断改用户是否具备权限,如果具备权限就执行SQL查询并返回结果。在Mysql 8.0以下的版本,如果设置了查询缓存,这时会将查询结果进行缓存。
2. Mysql 架构
Mysql是Client/Server架构,体系架构图如下
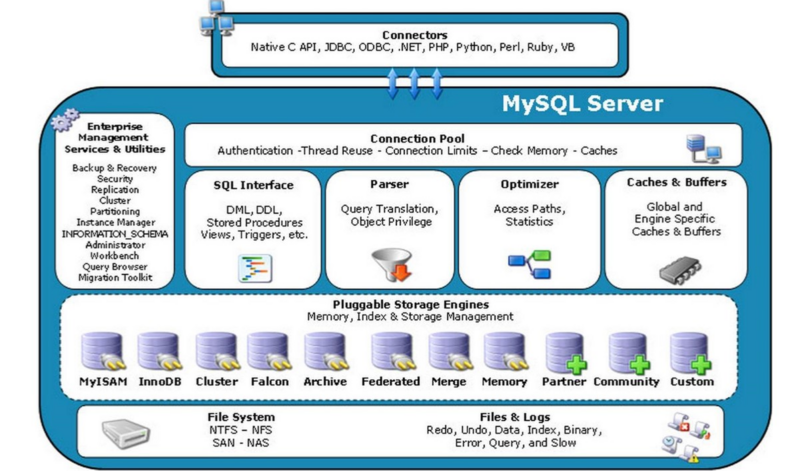
由以下几个部分组成
连接池组件(Connection Pool)
管理服务和工具组件(Enterprise Management Services & Utilities)
SQL 接口组件(SQL Interface)
查询分析器(Parser)
优化器组件(Optimizer)
缓冲组件(Cache & Buffer)
插件式储存引擎(Pluggable Storage Engines)
物理文件(File System , Files & Logs)
关于储存引擎
InnoDB储存引擎
Mysql 5.5 版本后默认的储存引擎,优点是支持事务、行级锁、外键约束、支持崩溃后的安全恢复
Myisam储存引擎
不支持事务和外键,支持全文索引(只对英文有效),特点是查询速度快
Memory储存引擎
数据放在内存当中(类似memcache)以便得到更快的响应速度,但是崩掉的话数据会丢失
NDB储存引擎
主要用于Mysql Cluster 分布式集群
Archive储存引擎
有很好的压缩机制,用于文件文档,写入时会进行压缩
3. 常用库/表操作语句
1. mysql -h localhost -u root -p # 以root用户连接本地数据库
2. show databases; # 查看Mysql服务中的所有数据库
3. create database database_name; # 创建数据库
4. use databases; # 更改操作的数据库对象
5. \c # 取消执行当前未输入mysql语句
6. show tables; # 查看该操作数据库对象中所有的数据表名和视图名
7. desc table_name/view_name; # 查看表/视图结构
8. truncate table_name; # 清空表数据【表结构不变】
9. delete from table_name; # 删除表
10. show create table table_name; # 查看建表/视图过程
11. show table status \G; # 查看数据库中的所有表信息;\G 竖行显示
12. show table status where name = table_name \G; # 指定表
13. rename table_name; # 改表名
14. drop table/view table_name/view_name; # 删除表/视图
4. 增删改查
1.insert
insert into table_name (column1,column2 ……) values (value1,value2 ……);
2.delete
delete from table_name where …… ; # where表示指定条件,不用where将针对表整表操作
3.update
update table_name set column1 = new_value , column2 = new_value …… where ……;
4. select
select cloumn1,cloumn2…… from table_name where …… group by …… having …… order by …… limit …… ;
# where|group by|having|order by|limit 可以没有其中某些项,若有必须按照先后顺序
5.深入理解select
select 是增删改查的重点,也是难点,能否写出高性能的sql语句,select是否熟练占很大一部分
列是变量,变量就可以进行各种运算,包括算术运算、逻辑运算 等
where后面的语句是表达式,表达式的值为真或假 eg:where 1 则恒为真 查询整张表,反之 where 0 恒位假 查询结果位Empty
select 语句还可以配合算术运算符、逻辑运算符、位运算符以及相关函数写出更高性能的查询语句
常用的select用法以goods表为例
数字筛选
select goods_id,goods_name,shop_price from goods where shop_price > 300;
字符筛选
select goods_id,goods_name,shop_price from goods where goods_name = 'kd876';
区间筛选
select goods_id,goods_name,shop_price from goods where shop_price between 300 and 3000;
多条件筛选
select goods_id,goods_name,shop_price from goods where shop_price between 300 and 3000 and goods_id > 10 ;
模糊条件筛选
select goods_id,goods_name,shop_price from goods where goods_name like '诺基亚%';
# 通配符% 表示任意多个字符 _ 表示任意单个字符
在字符串组里筛选
select goods_id,goods_name,shop_price from goods where goods_id in (3,10);
# goods_id in(3,10)等价于goods_id = 3 or goods_id = 10
借助函数优化筛选
select goods_id,goods_name,shop_price from goods where left(goods_name,2)='kd';
# 函数left(a,n)表示在a字符串中从左到右取n个字符
全字符段筛选
select * from goods;
不重复筛选
select distinct goods_id,goods_name,shop_price from goods; # distinct 不重复的意思
排序筛选
select goods_id,goods_name,shop_price from goods where shop_price >300 order by shop_price desc;
# asc升序(默认)/ desc 降序
补上后续练习所需要的表格代码
create table goods (
goods_id mediumint(8) unsigned primary key auto_increment,
goods_name varchar(120) not null default '',
cat_id smallint(5) unsigned not null default '0',
brand_id smallint(5) unsigned not null default '0',
goods_sn char(15) not null default '',
goods_number smallint(5) unsigned not null default '0',
shop_price decimal(10,2) unsigned not null default '0.00',
market_price decimal(10,2) unsigned not null default '0.00',
click_count int(10) unsigned not null default '0'
) engine=InnoDB default charset=utf8;
insert into `goods` values (1,'kd876',4,8,'ecs000000',1,1388.00,1665.60,9),
(4,'诺基亚n85原装充电器',8,1,'ecs000004',17,58.00,69.60,0),
(3,'诺基亚原装5800耳机',8,1,'ecs000002',24,68.00,81.60,3),
(5,'索爱原装m2卡读卡器',11,7,'ecs000005',8,20.00,24.00,3),
(6,'胜创kingmax内存卡',11,0,'ecs000006',15,42.00,50.40,0),
(7,'诺基亚n85原装立体声耳机hs-82',8,1,'ecs000007',20,100.00,120.00,0),
(8,'飞利浦9@9v',3,4,'ecs000008',1,399.00,478.79,10),
(9,'诺基亚e66',3,1,'ecs000009',4,2298.00,2757.60,20),
(10,'索爱c702c',3,7,'ecs000010',7,1328.00,1593.60,11),
(11,'索爱c702c',3,7,'ecs000011',1,1300.00,0.00,0),
(12,'摩托罗拉a810',3,2,'ecs000012',8,983.00,1179.60,13),
(13,'诺基亚5320 xpressmusic',3,1,'ecs000013',8,1311.00,1573.20,13),
(14,'诺基亚5800xm',4,1,'ecs000014',1,2625.00,3150.00,6),
(15,'摩托罗拉a810',3,2,'ecs000015',3,788.00,945.60,8),
(16,'恒基伟业g101',2,11,'ecs000016',0,823.33,988.00,3),
(17,'夏新n7',3,5,'ecs000017',1,2300.00,2760.00,2),
(18,'夏新t5',4,5,'ecs000018',1,2878.00,3453.60,0),
(19,'三星sgh-f258',3,6,'ecs000019',12,858.00,1029.60,7),
(20,'三星bc01',3,6,'ecs000020',12,280.00,336.00,14),
(21,'金立 a30',3,10,'ecs000021',40,2000.00,2400.00,4),
(22,'多普达touch hd',3,3,'ecs000022',1,5999.00,7198.80,16),
(23,'诺基亚n96',5,1,'ecs000023',8,3700.00,4440.00,17),
(24,'p806',3,9,'ecs000024',100,2000.00,2400.00,35),
(25,'小灵通/固话50元充值卡',13,0,'ecs000025',2,48.00,57.59,0),
(26,'小灵通/固话20元充值卡',13,0,'ecs000026',2,19.00,22.80,0),
(27,'联通100元充值卡',15,0,'ecs000027',2,95.00,100.00,0),
(28,'联通50元充值卡',15,0,'ecs000028',0,45.00,50.00,0),
(29,'移动100元充值卡',14,0,'ecs000029',0,90.00,0.00,0),
(30,'移动20元充值卡',14,0,'ecs000030',9,18.00,21.00,1),
(31,'摩托罗拉e8 ',3,2,'ecs000031',1,1337.00,1604.39,5),
(32,'诺基亚n85',3,1,'ecs000032',4,3010.00,3612.00,9);
create table category (
cat_id smallint unsigned auto_increment primary key,
cat_name varchar(90) not null default '',
parent_id smallint unsigned
)engine=InnoDB charset utf8;
INSERT INTO `category` VALUES
(1,'手机类型',0),
(2,'CDMA手机',1),
(3,'GSM手机',1),
(4,'3G手机',1),
(5,'双模手机',1),
(6,'手机配件',0),
(7,'充电器',6),
(8,'耳机',6),
(9,'电池',6),
(11,'读卡器和内存卡',6),
(12,'充值卡',0),
(13,'小灵通/固话充值卡',12),
(14,'移动手机充值卡',12),
(15,'联通手机充值卡',12);
CREATE TABLE `result` (
`name` varchar(20) DEFAULT NULL,
`subject` varchar(20) DEFAULT NULL,
`score` tinyint(4) DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into result
values
('张三','数学',90),
('张三','语文',50),
('张三','地理',40),
('李四','语文',55),
('李四','政治',45),
('王五','政治',30);
create table a (
id char(1),
num int
)engine=InnoDB charset utf8;
insert into a values ('a',5),('b',10),('c',15),('d',10);
create table b (
id char(1),
num int
)engine=InnoDB charset utf8;
insert into b values ('b',5),('c',15),('d',20),('e',99);
create table m(
mid int,
hid int,
gid int,
mres varchar(10),
matime date
)engine=InnoDB charset utf8;
insert into m
values
(1,1,2,'2:0','2006-05-21'),
(2,2,3,'1:2','2006-06-21'),
(3,3,1,'2:5','2006-06-25'),
(4,2,1,'3:2','2006-07-21');
create table t (
tid int,
tname varchar(20)
)engine=InnoDB charset utf8;
insert into t
values
(1,'国安'),
(2,'申花'),
(3,'布尔联队');
create table mian ( num int) engine=InnoDB;
insert into mian values
(3),
(12),
(15),
(25),
(23),
(29),
(34),
(37),
(32);
create table user (
uid int primary key auto_increment,
name varchar(20) not null default '',
age smallint unsigned not null default 0
) engine=InnoDB charset utf8;
create table boy (
hid char(1),
bname varchar(20)
)engine=InnoDB charset utf8;
insert into boy (bname,hid)
values
('屌丝','A'),
('杨过','B'),
('陈冠希','C');
create table girl (
hid char(1),
gname varchar(20)
)engine=InnoDB charset utf8;
insert into girl(gname,hid)
values
('小龙女','B'),
('张柏芝','C'),
('死宅女','D');
?注:上述包含的表格有goods、category、result、a、b、m、t、mian、user、boy、girl
?
6.查询练习以goods表为例
查询出名字为’诺基亚NXX’的手机
select * from goods where goods_id in(4,11);
查询出名字不以’诺基亚’开头的商品
select * from goods where goods_name not like '诺基亚%';
查询出第4和第11行的所有信息
把goods表中商品名为’诺基亚xxxx’改为’HTCxxxx’
select goods_id, concat('HTC',substring(goods_name,4)) from goods where goods_name like '诺基亚%';
# 1. 函数concat(a,b) 将ab两个字符串连接成一个字符串
# 2. 函数substring(string,position)从特定位置开始的字符串返回一个给定长度的子字符串
小结:当涉及到多重条件查询需要用到运算符、and、or、not……之类来修饰条件时
* 一定要先弄清楚条件之间的分类
* 使用( )将其分类,避免优先级之类的问题
面试题mian表
将mian表中处于[20,29]之间的num值改成20,[30,39]之间的num值改成30,一句sql完成。
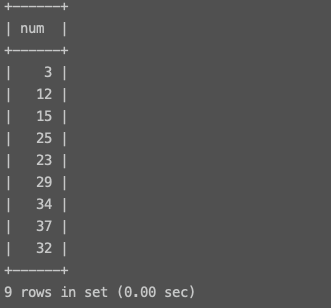
update mian set num = (floor(num/10)*10) where num between 20 an 39; # 函数floor(x) 取不大于x的最大整数值
7. group by 分组与统计函数
常用统计函数
max()# 获取最大值
min()# 获取最小值
avg()# 求取平均值
sum()# 求和
count()# 计算行数/条数 *特别注意count()返回的是一个总行数
distinct()# 求有多少种不同解
另外注意:当出现group by分组种不能配对的情况,该字段取查询时候第一次出现的值
8. having 筛选结果集
注:having 并不一定 与 where共存(这种情况可以看做类似where 1这种语句可以忽略),但一定在where之后;可以存在只有having而没有where的情况
查询goods表中商品比市场价低出多少?
select goods_id ,goods_name,market_price - shop_price from goods ;
查询goods表中商品比市场价低出至少200元的商品
select goods_id ,goods_name,(market_price - shop_price) as discount from goods where market_price - shop_price ;
# 注意为什么where后面不能用 discount
select goods_id,goods_name,(market_price-shop_price) as discount from goods having discount>200;
9. where __ group by __ having 综合练习result表
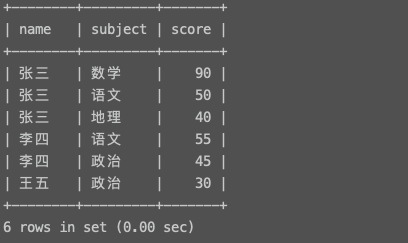
有以上result表,要求查询出2门及2门以上不及格的平均成绩 ※※※经典题目※※※
难点分析:如何找出2门及2门以上不及格的同学
一种典型错误 ? 【错误点:对count和比较运算两者结合的理解错误】
msyql> select name , count(score<60) as gks , avg(score) as pjf from result group by name having gks >= 2;
+--------+-----+---------+
| name | gks | pjf |
+--------+-----+---------+
| 张三 | 3 | 60.0000 |
| 李四 | 2 | 50.0000 |
+--------+-----+---------+
2 rows in set (0.00 sec) # 貌似是正确的,但只针对此种情况
验证:假如增加1行数据 values('赵六','语文',88),('赵六','数学',99),('赵六','物理',100)
再次执行上面的sql语句,将会得到如下结果
+--------+-----+---------+
| name | gks | pjf |
+--------+-----+---------+
| 张三 | 3 | 60.0000 |
| 李四 | 2 | 50.0000 |
| 赵六 | 3 | 95.6667 |
+--------+-----+---------+
3 rows in set (0.00 sec)
# 很明显有语义上的错误!实际上count(score)和count(score<60)查询出的结果是一样的,函数count()返回的是总行数!
正确解题思路?(逆向思维)
1. select name ,avg(score),as pjf from result group by name;
+--------+---------+
| name | pjf |
+--------+---------+
| 张三 | 60.0000 |
| 李四 | 50.0000 |
| 王五 | 30.0000 |
| 赵六 | 95.6667 |
+--------+---------+
4 rows in set (0.00 sec)# 1. 查询出所有同学的平均分,并分组
2. select name, score<60 from result;
+--------+----------+
| name | score<60 |
+--------+----------+
| 张三 | 0 |
| 张三 | 1 |
| 张三 | 1 |
| 李四 | 1 |
| 李四 | 1 |
| 王五 | 1 |
| 赵六 | 0 |
| 赵六 | 0 |
| 赵六 | 0 |
+--------+----------+
9 rows in set (0.00 sec)
# 2. 查看每个同学的挂科情况;这里运用了逻辑运算,这个点也很重要!score<60 若真则返回0 若假则返回1
3. select name , sum(score<60) as gks from result group by name;
+--------+------+
| name | gks |
+--------+------+
| 张三 | 2 |
| 李四 | 2 |
| 王五 | 1 |
| 赵六 | 0 |
+--------+------+
4 rows in set (0.00 sec)# 3. 计算每位同学的总挂科数
4. select name ,sum(score<60) as gks ,avg(score) as pjf from result group by name having gks >=2;
+--------+------+------------+
| name | gks | pjf |
+--------+------+------------+
| 张三 | 2 | 60.0000 |
| 李四 | 2 | 50.0000 |
+--------+------+------------+
2 rows in set (0.00 sec)# 4. 整合1.3步,得到结果集,并筛选出gks大于等于2的同学
10. order by 排序(在内存中排序)与limit(限制范围)综合查询goods表
按栏目由低到高排序,栏目内部按价格由高到低排序
select goods_id ,goods_name ,shop_price ,cat_id from goods order by cat_id desc,shop_price asc;
取出价格最高的前3名商品
select goods_id ,goods_name,shop_price from goods order by shop_price desc limit 0,3;
# limit x,y 其中x代表起始位置也就是偏移量,y代表返回最大行数;x初始值为0
取出商品市场价前10到25的商品信息
select goods_id ,goods_name,market_price from goods order by market_price limit 11,15;
11. 子查询
mysql子查询是嵌套在另一个查询(如select、insert、update或者delete)中的查询。这里重点总结了嵌套在select中的子查询
where 子查询【以内层查询结果通常为变量作为外层查询的比较条件】
如何查询每个栏目下面最新的那件产品?
语义解析:栏目列 :cat_id ;最新的那件产品?goods_id 为最大值时所对应的那一件产品
# 1. 陷阱演示 ?
# 思路:最新的商品 max(goods_id);每个栏目 group by cat_id
select max(goods_id) ,goods_name ,cat_id ,shop_price from goods group by cat_id ;
# 报错:ERROR 1055 (42000): Expression #2 of SELECT list is not in GROUP BY clause and contains nonaggregated
# column 'zion.goods.goods_name' which is not functionally dependent on columns in GROUP BY clause;
# this is incompatible with sql_mode=only_full_group_by 大概意思是 语义缺陷,不兼容
#分析:”先查询再排序“ group by cat_id 但是goods_name,shop_price应该取谁的呢?
# 2. 正确方法 ?
# 思路:”先排序再查询“ 需要用到子查询/连接查询
# ”先排序“
select max(goods_id),cat_id from goods group by cat_id;
+---------------+--------+
| max(goods_id) | cat_id |
+---------------+--------+
| 16 | 2 |
| 32 | 3 |
| 18 | 4 |
| 23 | 5 |
| 7 | 8 |
| 6 | 11 |
| 26 | 13 |
| 30 | 14 |
| 28 | 15 |
+---------------+--------+
9 rows in set (0.00 sec)
# ”再查询“
select cat_id ,goods_id, goods_name, shop_price from goods where goods_id in (select max(goods_id) from goods group by cat_id);
+--------+----------+----------------------------------------+------------+
| cat_id | goods_id | goods_name | shop_price |
+--------+----------+----------------------------------------+------------+
| 11 | 6 | 胜创kingmax内存卡 | 42.00 |
| 8 | 7 | 诺基亚n85原装立体声耳机hs-82 | 100.00 |
| 2 | 16 | 恒基伟业g101 | 823.33 |
| 4 | 18 | 夏新t5 | 2878.00 |
| 5 | 23 | 诺基亚n96 | 3700.00 |
| 13 | 26 | 小灵通/固话20元充值卡 | 19.00 |
| 15 | 28 | 联通50元充值卡 | 45.00 |
| 14 | 30 | 移动20元充值卡 | 18.00 |
| 3 | 32 | 诺基亚n85 | 3010.00 |
+--------+----------+----------------------------------------+------------+
9 rows in set (0.00 sec)
# 分析:1.由此可见 select max(goods_id) ,goods_name ,shop_price from goods 除了goods_id符合题意,其它的在语义上就是存在缺陷的;
# 这是一个有缺陷的语句。
# 2.列就是变量;把查询这个变量(列)的sql语句作为外层sql语句的比较条件,这么做的目的是为了我们每次更新商品后,都能取得最新的那个商品。
# 这样也不会出现 列与列不匹配错乱的情况
查询出编号位19的商品的栏目名称[栏目名称放在category表中]
select cat_id,cat_name from category where cat_id = ( select cat_id from goods where goods_id = 19 );
+--------+-----------+
| cat_id | cat_name |
+--------+-----------+
| 3 | GSM手机 |
+--------+-----------+
1 row in set (0.00 sec)
from 子查询 【将查询出来的结果当成一个新”表“来操作】
==============未完待续……
这篇关于mysql 申花球队面试题_Mysql基础知识的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






