本文主要是介绍sqlalchemy中的预排序树sqlalchemy_mptt,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
sqlalchemy_mptt
简介:
无限极分类是一种比较常见的数据格式,生成组织结构,生成商品分类信息,权限管理当中的细节权限设置,都离不开无限极分类的管理。常见的有链表式,即有一个Pid指向上级的ID,以此来设置结构。写的时候简单,用的时候效果一班,比如说,同一级没有办法手动重新排序,查询所有子孙的时候不方便。 所以有了预排序树,它是修改后的前序遍历,即左右值树形管理。
树形结构图:

优点:可以快速确定关系,最短路径,同级排序,查找所有子孙(最好的地方)
安装:
pip install sqlalchemy
pip install sqlalchemy_mptt
还需安装MySQLdb或者可以用PyMySQL代替。
pip install PyMySQL
在使用import sqlalchemy时加上:
import pymysql
pymysql.install_as_MySQLdb()
使用:
引用
import pymysql
pymysql.install_as_MySQLdb()
from sqlalchemy import create_engine
from sqlalchemy.orm import scoped_session, sessionmaker
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy_mptt import mptt_sessionmaker
from sqlalchemy_mptt.mixins import BaseNestedSets
Base = declarative_base()
连接数据库
'''
create_engine()返回一个Engine的实例,并且它表示通过数据库语法处理细节的核心接口,在这种情况下,数据库语法将会被解释成python的类方法。
echo参数为True时,会显示每条执行的SQL语句,可以关闭。
mysql: 指定是哪种数据库连接
第一个root: 用户名
123456: root用户对应的密码
localhost: 数据库的ip
mptt: 数据库需要连接库的名字
'''
engine = create_engine('mysql://root:123456@localhost/mptt', echo=False)
# conn = engine.connect() # 可以检验是否连接成功
# sql = '''
# create table student(
# id int not null primary key,
# name varchar(50),
# age int,
# address varchar(100));
# '''
# conn.execute(sql)
# engine.connect() # 表示获取到数据库连接。类似我们在MySQLdb中游标course的作用。
mptt_ession = mptt_sessionmaker(sessionmaker(bind=engine))
db_session = scoped_session(sessionmaker(autocommit=False,autoflush=False,bind=engine))
首先定义一个数据对象
定义一个数据库Tree,主键id,name名字两个字段
class Tree(Base, BaseNestedSets):__tablename__ = "tree"id = Column(Integer, primary_key=True)name = Column(String(8))def __repr__(self):return "<Node (%s)>" % self.id
对应的数据库结构

我们只定义了主键id,name名字。但是数据库里面多了几列:lft,rgt,level,tree_id,parent_id
这些结构就是左右值树用的东西,可以很方便的查到结构。
添加一些数据
if __name__ == '__main__':Base.metadata.create_all(bind=engine)node = Tree()node.name = "脉脉" # 当不给parent_id赋值时,相当于新建一个树,tree_id递增db_session.add(node)db_session.commit()parent_id1 = db_session.query(Tree.id).filter_by(name="脉脉").first()[0]level1_node = []level1_node_names = ["PN", "招聘", "广告", "增长"]for item in level1_node_names:node = Tree()node.name = itemnode.parent_id = parent_id1level1_node.append(node)db_session.add_all(level1_node)db_session.commit()level2_node = []level2_node_names = ["认证", "network", "profile"]parent_id2 = db_session.query(Tree.id).filter_by(name="PN").first()[0]for item in level2_node_names:node = Tree()node.name = itemnode.parent_id = parent_id2level2_node.append(node)db_session.add_all(level2_node)db_session.commit()level3_node = []level3_node_names = ["sk", "lxx"]parent_id3 = db_session.query(Tree.id).filter_by(name="network").first()[0]for item in level3_node_names:node = Tree()node.name = itemnode.parent_id = parent_id3level3_node.append(node)db_session.add_all(level3_node)db_session.commit()print_tree("脉脉")
输出:
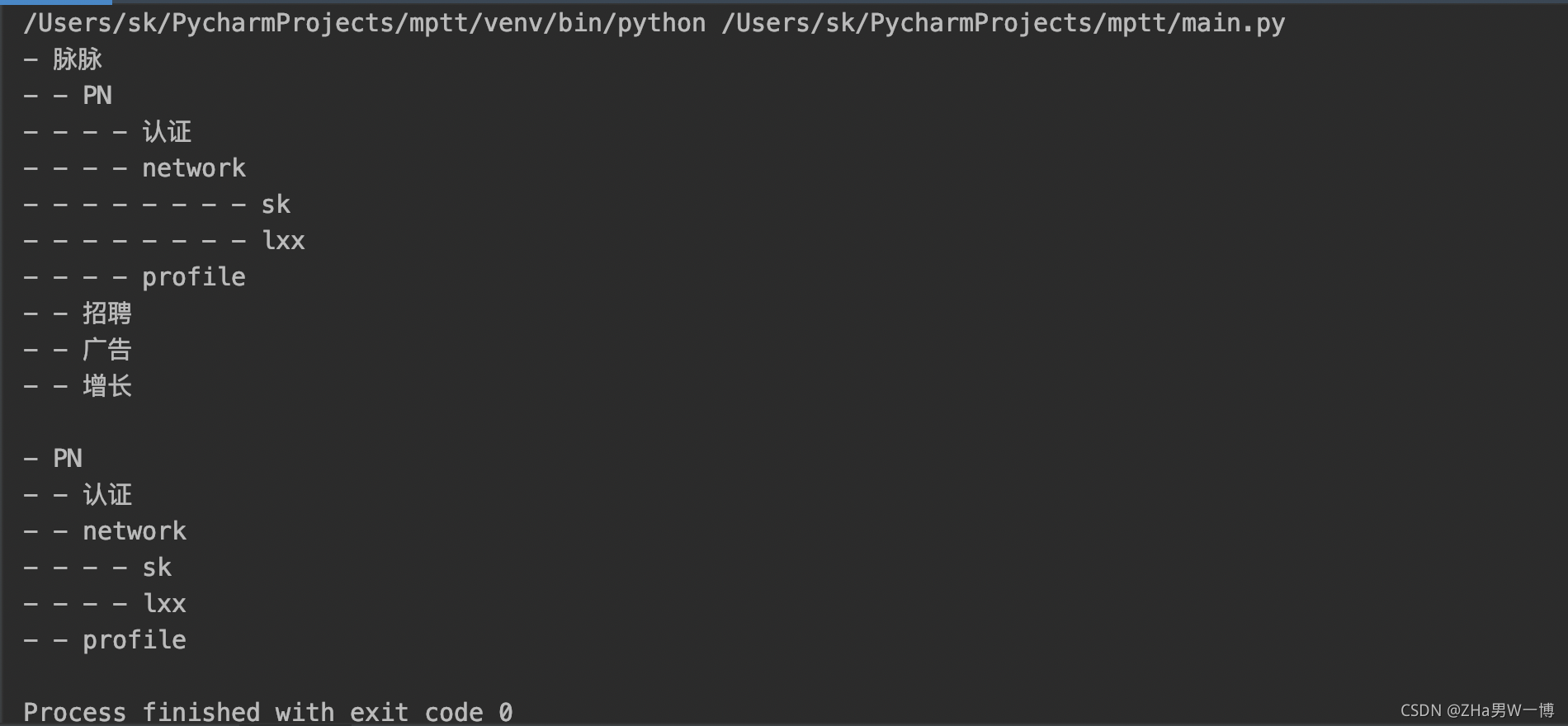
我加入的顺序可不是这个顺序,但是数据结构sqlalchemy_mptt帮我们处理了层级数据结构,就显示为树形结构了。
数据库数据
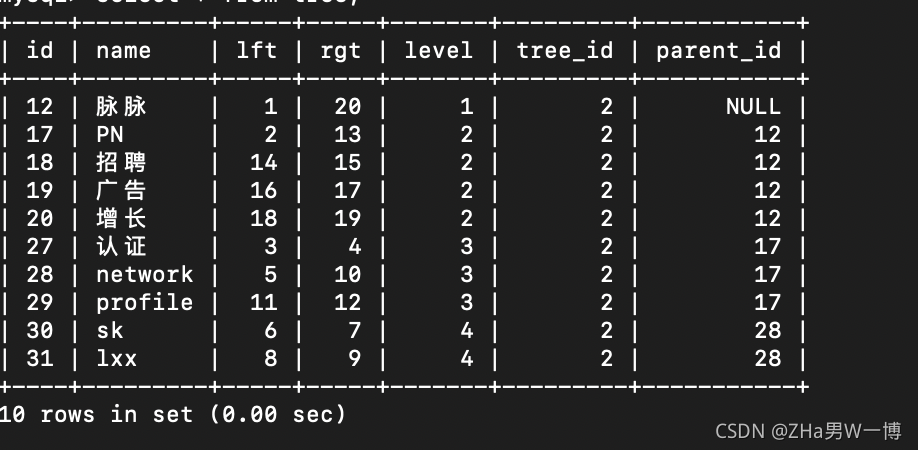
数据操作

查询
查找“脉脉”的子孙
“脉脉”作为参考点,左值为1,右值为18,所有的子孙,就是数据库中左值大于1,小于18的。
查找“PN”的子孙
"PN"作为参考点,左值为2,右值为11,所有的子孙,就是数据库中左值大于2,小于11的。
找到所有的子节点(不包括孙节点):
查找“脉脉”的子节点,“脉脉”作为参考点,level=1,tree_id=1。那么所有的子节点为tree_id=1,level=1+1 层级为2的。
查找最短路径:
一般用在导航中,也有用在组合显示上,因为需要知道上一级,上N级的路径结构:查找sk的上级路径,sk作为参考点,左值为6,右值为7,那么路径就是数据库中左值小于6,并且右值大于7的。结果就是 脉脉–>PN–>network–>sk
算法
增加
按sqlalchemy_mptt的用法,
如果没有parent_id,那么就创建为一个新树的根节点,parent_id是空的,level是1,tree_id根据数据库的情况顺序向上加。
如果有提供parent_id,那么久创建为parent的子节点,parent_id是提供的,level是parent的level+1,tree_id和parent一致。
同时要更新受影响的其他节点。
左值处理一遍。
大于parent_id右值的所有左值,+2
右值处理一遍。
大于等于parent_id右值的所有右值,+2
删除
和增加差不多,删除一个节点以后,也要更新受影响的左值和右值。
移动
这个其实就是删除一个老节点,再创建一个新节点。
这篇关于sqlalchemy中的预排序树sqlalchemy_mptt的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






