本文主要是介绍try catch 应该在 for 循环里面还是外面?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.使用场景
为什么要把 使用场景 摆在第一个 ?
因为本身try catch 放在 for循环 外面 和里面 ,如果出现异常,产生的效果是不一样的。
怎么用,就需要看好业务场景,去使用了。
1.1 try catch 在 for 循环 外面
public static void tryOutside() { try { for (int count = 1; count <= 5; count++) { if (count == 3) { //故意制造一下异常 int num = 1 / 0; } else { System.out.println("count:" + count + " 业务正常执行"); } } } catch (Exception e) { System.out.println("try catch 在for 外面的情形, 出现了异常,for循环显然被中断"); }
}
结果:

效果结论:
try catch 在 for 循环 外面 的时候, 如果 for循环过程中出现了异常, 那么for循环会终止。
1.2 try catch 在 for 循环 里面
代码示例 :
public static void tryInside() { for (int count = 1; count <= 5; count++) { try { if (count == 3) { //故意制造一下异常 int num = 1 / 0; } else { System.out.println("count:" + count + " 业务正常执行"); } } catch (Exception e) { System.out.println("try catch 在for 里面的情形, 出现了异常,for循环显然继续执行"); } }
}
结果:
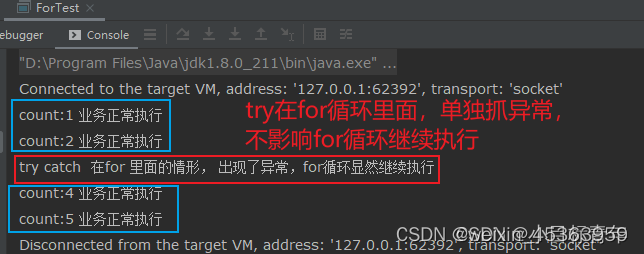
效果结论:
try catch 在 for 循环 里面 的时候, 如果 for循环过程中出现了异常,异常被catch抓掉,不影响for循环 继续执行。
2.性能
时间上, 其实算是无差别。
内存上, 如果没出异常,其实也是无差别。
但是如果出现了异常, 那就要注意了。
注意点是什么 ?看代码:
我们简单用
Runtime runtime = Runtime.getRuntime();
long memory = runtime.freeMemory();
来统计一下内存消耗情况:
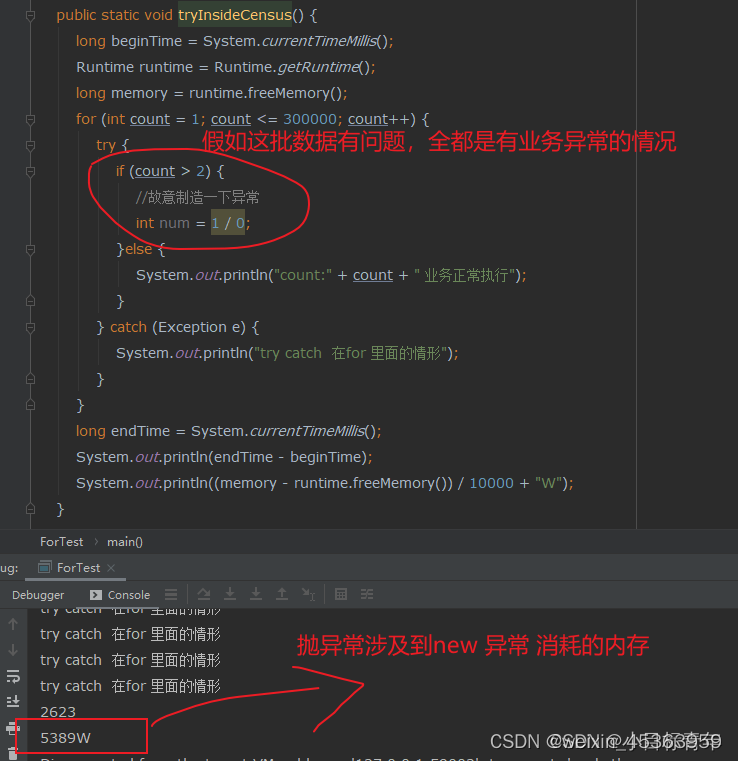
结论:
也就是说, try catch 放在 for 循环里面 ,因为出现异常不会终止 for循环。所以如果真的存在大批量业务处理全是异常,有那么一定的内存消耗情况。
如果说代码没出错的话, try catch 在 for 里面 和 外面 ,都是几乎没区别的。
为啥, 因为 异常try catch 其实一早编译完就标记了 如果从哪儿(from)出现异常,会直接去到(to)的那行代码去。
Exception table : 当前函数程序代码编译涉及到的异常;
type :异常类型;
target:表示异常的处理起始位;
from:表示 try-catch 的开始地址;
to:表示 try-catch 的结束地址;
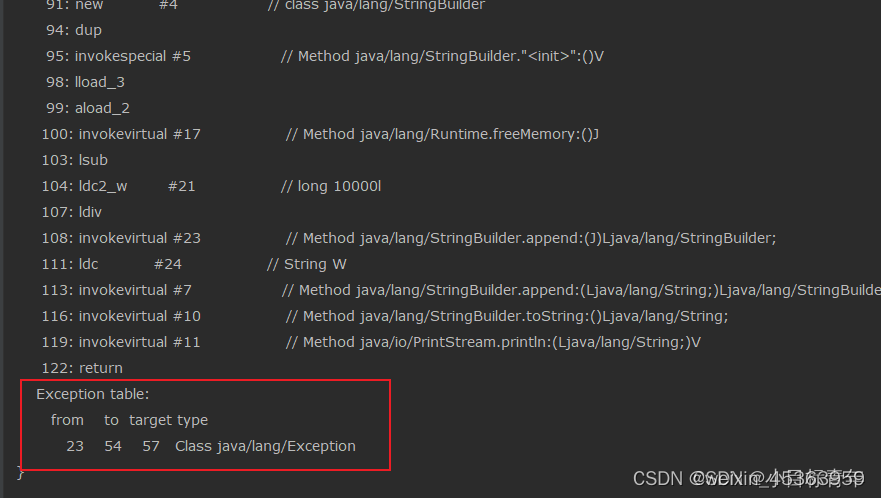
所以如果不考虑业出错,是否终止循环, 这个try catch 放里放外没啥区别。
这篇关于try catch 应该在 for 循环里面还是外面?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




