本文主要是介绍Linux:使用fdisk和parted对硬盘分区等操作,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
fdisk
prated
查看硬盘
配置硬盘
查看帮助
配置新的磁盘标签类型
创建分区
查看分区情况
编辑
退出编辑
删除分区
格式化
误删恢复分区
fdisk
Linux:磁盘管理 | 查看 磁盘,创建分区,格式化文件系统,添加&开启swap交换系统 ,格式化硬盘后进行挂载 ,挂载光盘, 挂载USB ,取消挂载(卸载),开机自动挂载_开机挂载swap-CSDN博客![]() https://blog.csdn.net/w14768855/article/details/130772080?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170289621016800225567563%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170289621016800225567563&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-3-130772080-null-null.nonecase&utm_term=fdisk&spm=1018.2226.3001.4450
https://blog.csdn.net/w14768855/article/details/130772080?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522170289621016800225567563%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=170289621016800225567563&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~blog~first_rank_ecpm_v1~rank_v31_ecpm-3-130772080-null-null.nonecase&utm_term=fdisk&spm=1018.2226.3001.4450
prated
如果我们使用的是fdisk那么只能有4个主分区,到第五个就开始逻辑分区
但是我们使用prated可以创建128个主分区。
查看硬盘
现在我加了块硬盘
parted -l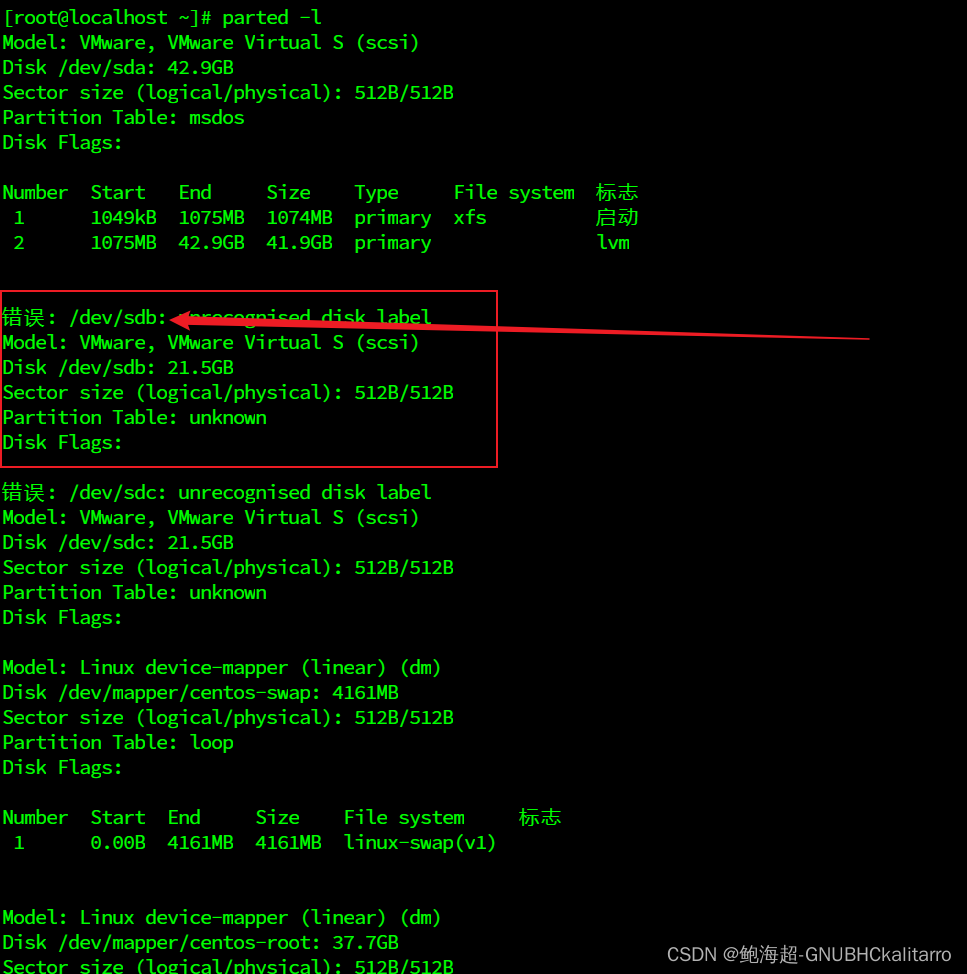
我这个第二块硬盘为/dev/sdb 由于我还没编辑所以他显示的是错误,这个属于正常的等会编辑完就好了。
配置硬盘
parted 要配置硬盘的路径
我这里是sdb所以要配置的路径就是/dev/sdb
parted /dev/sdb
进入成功
查看帮助
当进入成功之后,输入help
help
配置新的磁盘标签类型
要配置了标签才可以实现全是主分区这里我用gpt
mklabel 
输入gpt
创建分区
mkpart 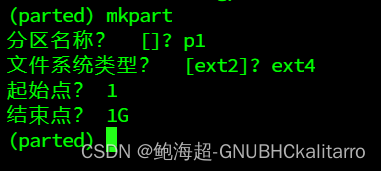
第一个分区的起点为1,我这里创建6个

每次下一个分区的开始都要衔接上上一个的结束
查看分区情况
p
可以看到创建了6个
退出编辑
quit或者
q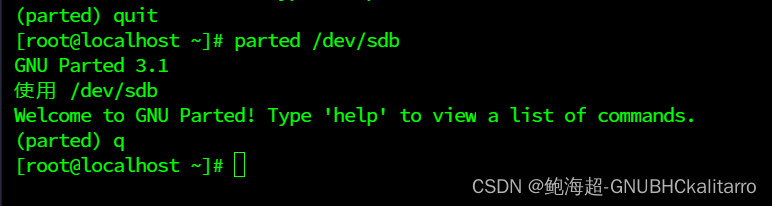
删除分区
rm 编号
rm 2现在删除p2 也就是/dev/sdb2
通过第一排的编号去删除的


!!!注意,数据无价不要随意删除数据,如果多次覆盖或者重要文件可能会造成丢失无法挽回
!!!注意,数据无价不要随意删除数据,如果多次覆盖或者重要文件可能会造成丢失无法挽回
!!!注意,数据无价不要随意删除数据,如果多次覆盖或者重要文件可能会造成丢失无法挽回
格式化
我们刚刚是分好区了,他们都是主分区,再去格式化就能正常使用了

mkfs.~ ~就是格式化的文件系统类型
比如我想把他们都格式化为ext4类型
mkfs.ext4 /dev/sdb1
mkfs.ext4 /dev/sdb2
mkfs.ext4 /dev/sdb3
mkfs.ext4 /dev/sdb4
mkfs.ext4 /dev/sdb5
mkfs.ext4 /dev/sdb6 
这样格式化完就可以正常使用了
误删恢复分区
现在我在/dev/sdb1里写了一些文件,但是不小心删除了,模拟一下如何恢复
mount /dev/sdb1 /sdb1/
我把sdb1挂载了,并往里面写入了一些文件

rm 1 
现在删除了1

rescue

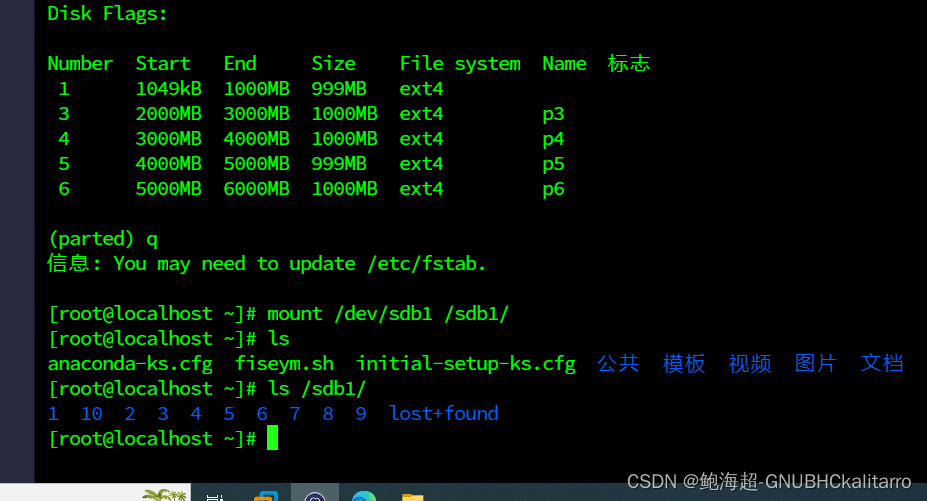
里面的东西依旧存在
!!!注意,数据无价不要随意删除数据,如果多次覆盖或者重要文件可能会造成丢失无法挽回
!!!注意,数据无价不要随意删除数据,如果多次覆盖或者重要文件可能会造成丢失无法挽回
!!!注意,数据无价不要随意删除数据,如果多次覆盖或者重要文件可能会造成丢失无法挽回
恢复成功了,建议拿没有用的东西练手,如果乱删或者操作不当,很可能无法恢复 ,这个就当做后路了
这篇关于Linux:使用fdisk和parted对硬盘分区等操作的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






