本文主要是介绍【DataSophon】大数据服务组件之Flink升级,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

🦄 个人主页——🎐开着拖拉机回家_Linux,大数据运维-CSDN博客 🎐✨🍁
🪁🍁🪁🍁🪁🍁🪁🍁 🪁🍁🪁🍁🪁🍁🪁 🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁🪁🍁
感谢点赞和关注 ,每天进步一点点!加油!
目录
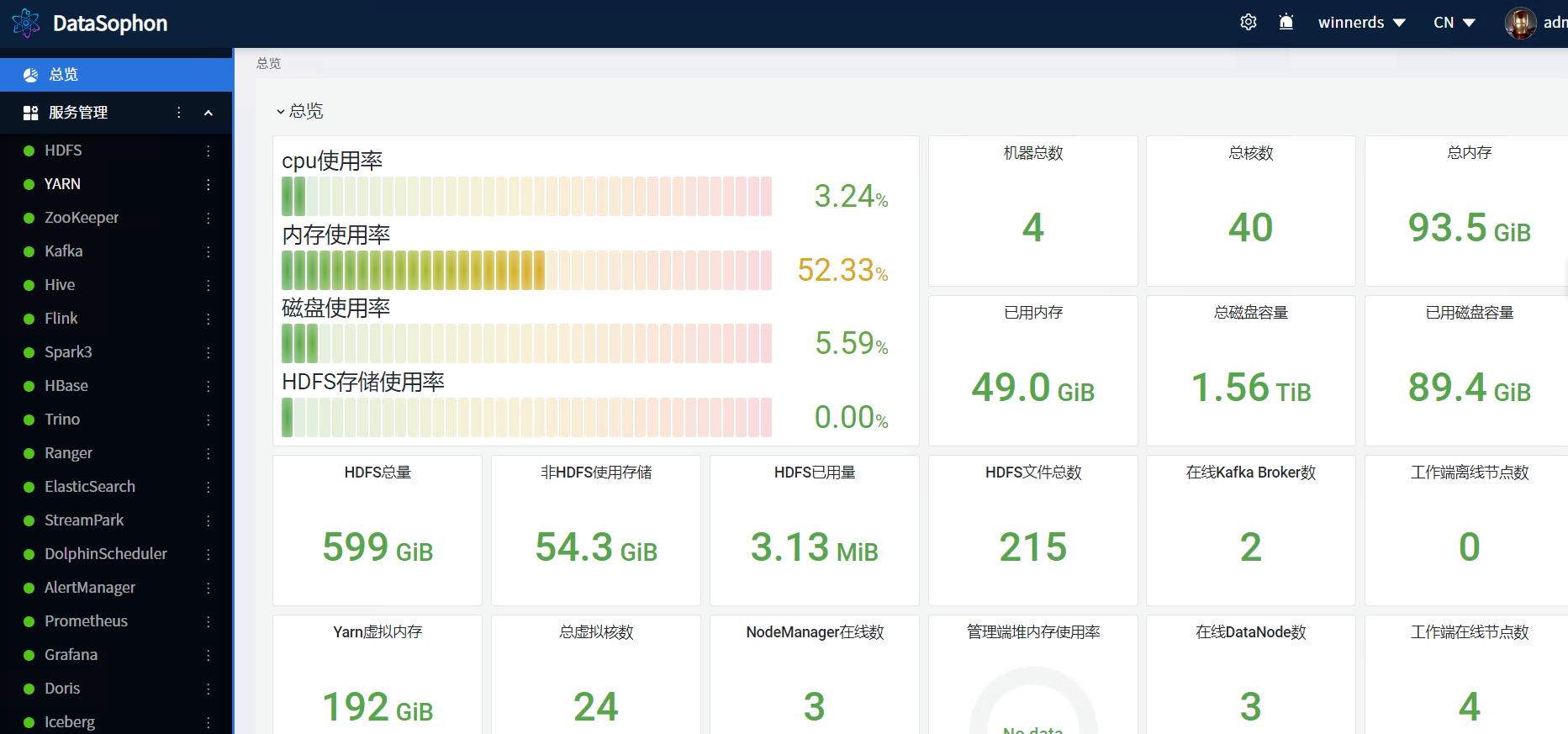
一、DataSophon是什么
1.1 DataSophon概述
1.2 架构概览
1.3 设计思想
二、解压新旧组件安装包
三、 修改安装包中文件和目录
四、重新生成安装包
3.1 重新打包
3.2 生成加密码
3.3 生成md5加密文件
五、 删除已装的组件包flink(ALL)
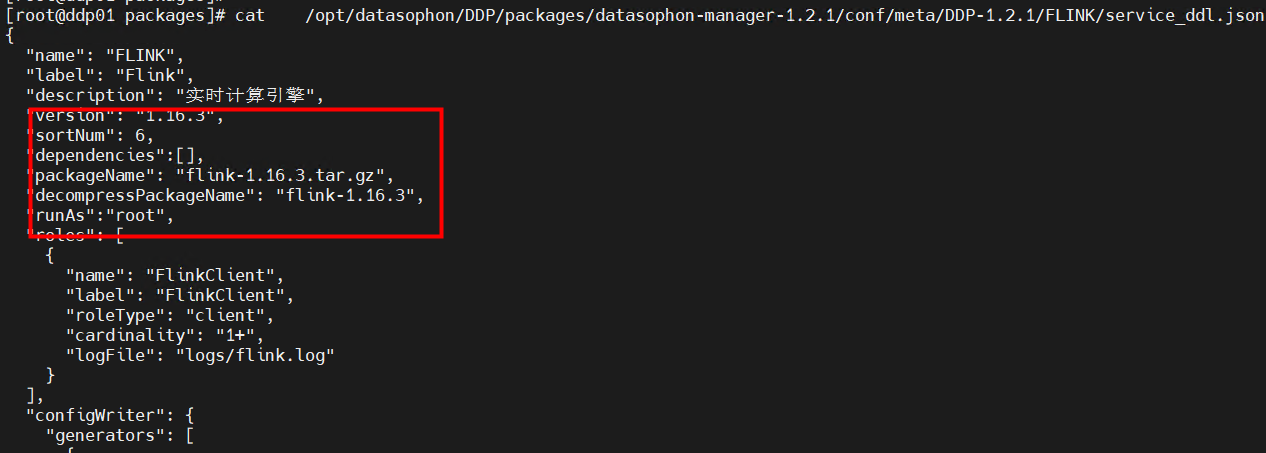
六、修改service_ddl.json
七、修改env环境变量(ALL)
7.1修改环境变量配置参数(ALL)
7.2 重启manager服务
八、重新安装服务
九、测试验证
一、DataSophon是什么
1.1 DataSophon概述
DataSophon也是个类似的管理平台,只不过与智子不同的是,智子的目的是锁死人类的基础科学阻碍人类技术爆炸,而DataSophon是致力于自动化监控、运维、管理大数据基础组件和节点的,帮助您快速构建起稳定,高效的大数据集群服务。
主要特性有:
- 快速部署,可快速完成300个节点的大数据集群部署
- 兼容复杂环境,极少的依赖使其很容易适配各种复杂环境
- 监控指标全面丰富,基于生产实践展示用户最关心的监控指标
- 灵活便捷的告警服务,可实现用户自定义告警组和告警指标
- 可扩展性强,用户可通过配置的方式集成或升级大数据组件
官方地址:DataSophon | DataSophon
GITHUB地址:datasophon/README_CN.md at dev · datavane/datasophon
1.2 架构概览

1.3 设计思想
为设计出轻量级,高性能,高可扩的,可满足国产化环境要求的大数据集群管理平台。需满足以下设计要求:
(1)一次编译,处处运行,项目部署仅依赖java环境,无其他系统环境依赖。
(2)DataSophon工作端占用资源少,不占用大数据计算节点资源。
(3)可扩展性高,可通过配置的方式集成托管第三方组件。
二、解压新旧组件安装包
flink-1.6.2升级到flink-1.6.3,安装包下载
https://mirrors.tuna.tsinghua.edu.cn/apache/
https://archive.apache.org/dist/flink/flink-1.6.3/
解压
tar -zxvf flink-1.16.3-bin-scala_2.12.tgz -C /opt/datasophon/DDP/packages三、 修改安装包中文件和目录
cd /opt/datasophon/DDP/packages
chown -R root:root flink-1.16.3四、重新生成安装包
4.1 重新打包
cd /opt/datasophon/DDP/packages
tar -zcvf flink-1.16.3.tar.gz flink-1.16.3
4.2 生成加密码
md5sum flink-1.16.3.tar.gz4.3 生成md5加密文件
echo '4d292114646f220e43ec56b75c53dfdb' > flink-1.16.3.tar.gz.md5
五、 删除已装的组件包flink(ALL)
从DataSophon上把flink停止并删除

删除已装的组件包,所有安装的服务器都要执行
rm -rf /opt/datasophon/flink*六、修改service_ddl.json
vim /opt/datasophon/DDP/packages/datasophon-manager-1.2.1/conf/meta/DDP-1.2.1/FLINK/service_ddl.json
*datasophon-manager-1.2.1 为当前的datasohon安装版本,可能多处地方需要修改
七、修改env环境变量(ALL)
7.1修改环境变量配置参数(ALL)
[root@ddp01 packages]# cat /etc/profile.d/datasophon-env.sh
export FLINK_HOME=/opt/datasophon/flink-1.16.3[root@ddp01 packages]# source /etc/profile.d/datasophon-env.sh
7.2 重启manager服务
rm -rf /opt/datasophon/DDP/packages/datasophon-manager-1.2.1/logs/*
/opt/datasophon/DDP/packages/datasophon-manager-1.2.1/bin/datasophon-api.sh restart api
cd /opt/datasophon/DDP/packages/datasophon-manager-1.2.1/logs查看相应的表配置数据
select * from t_ddh_frame_service;select * from t_ddh_frame_service_role;
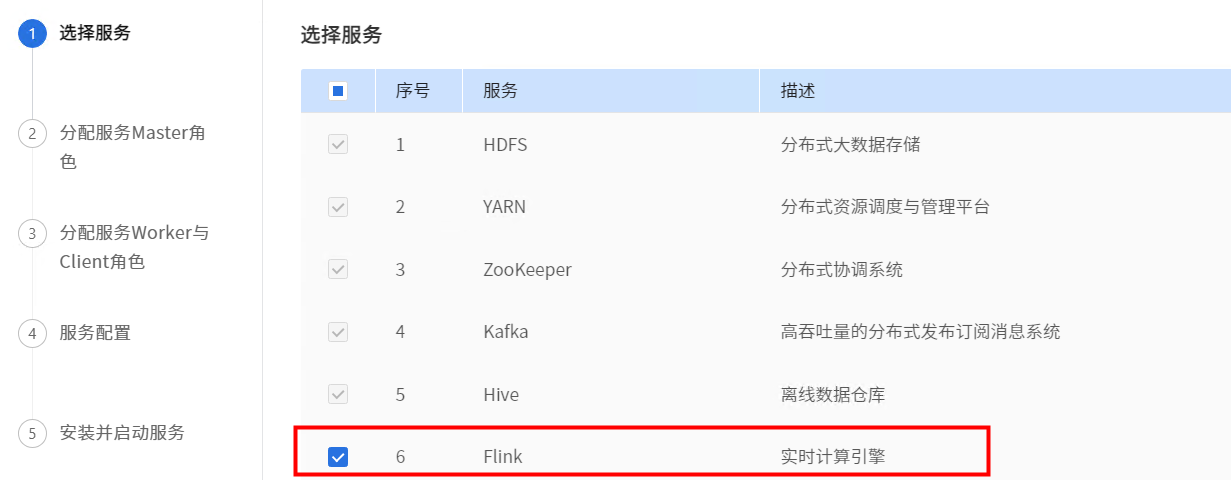
八、重新安装服务
选择Flink服务
选择 FlinkClient 安装

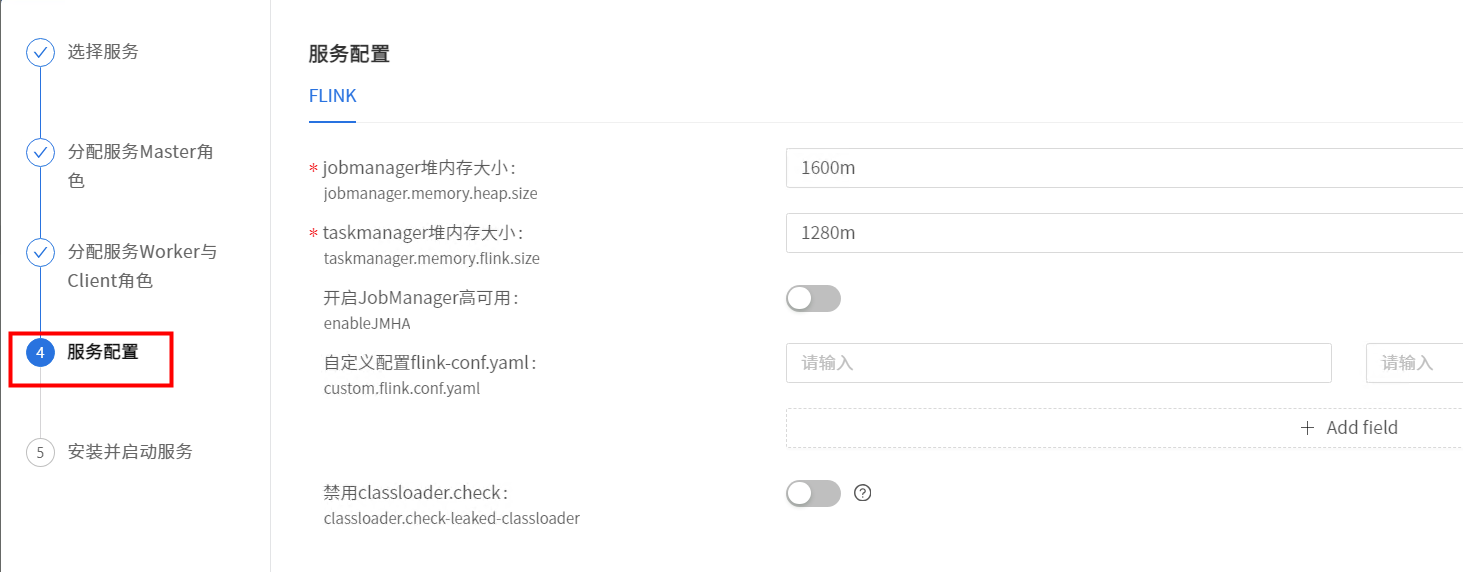
配置根据实际情况调整
安装成功,如若失败可查看失败原因再重新安装
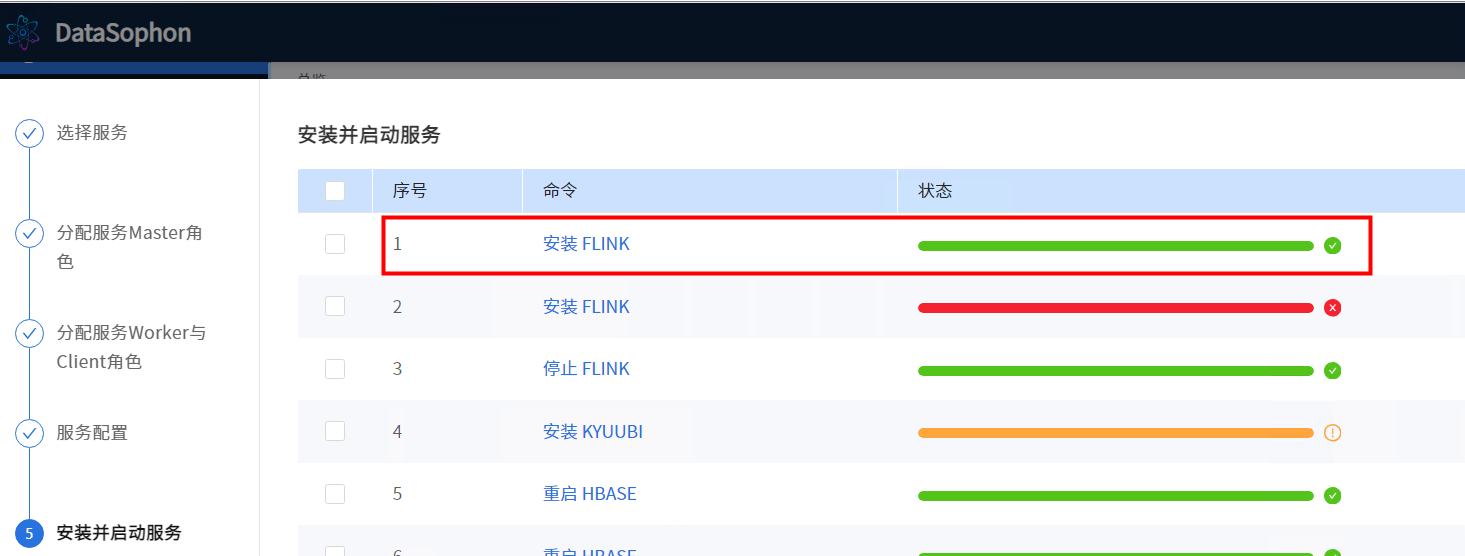
客户端查看版本

九、测试验证
运行WordCount测试程序
export HADOOP_CLASSPATH=`hadoop classpath`
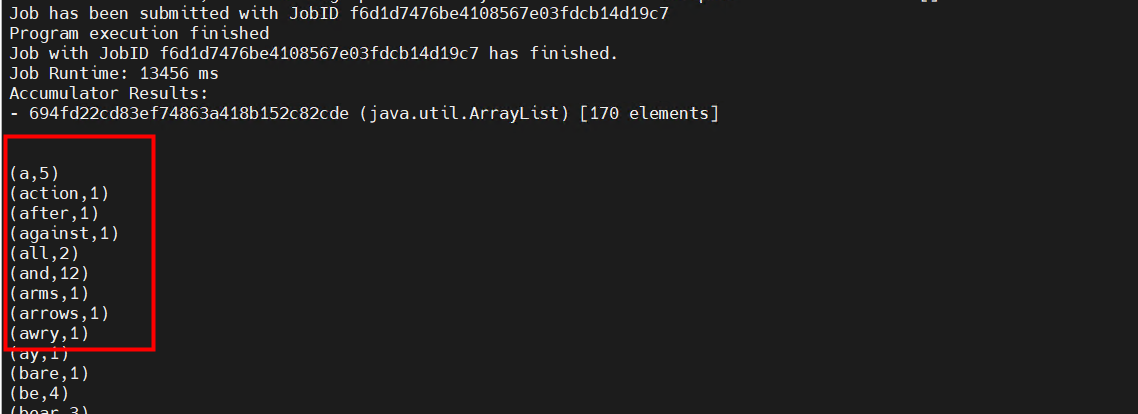
flink run -m yarn-cluster /opt/datasophon/flink/examples/batch/WordCount.jar集群提交,日志需要在yarn上查看
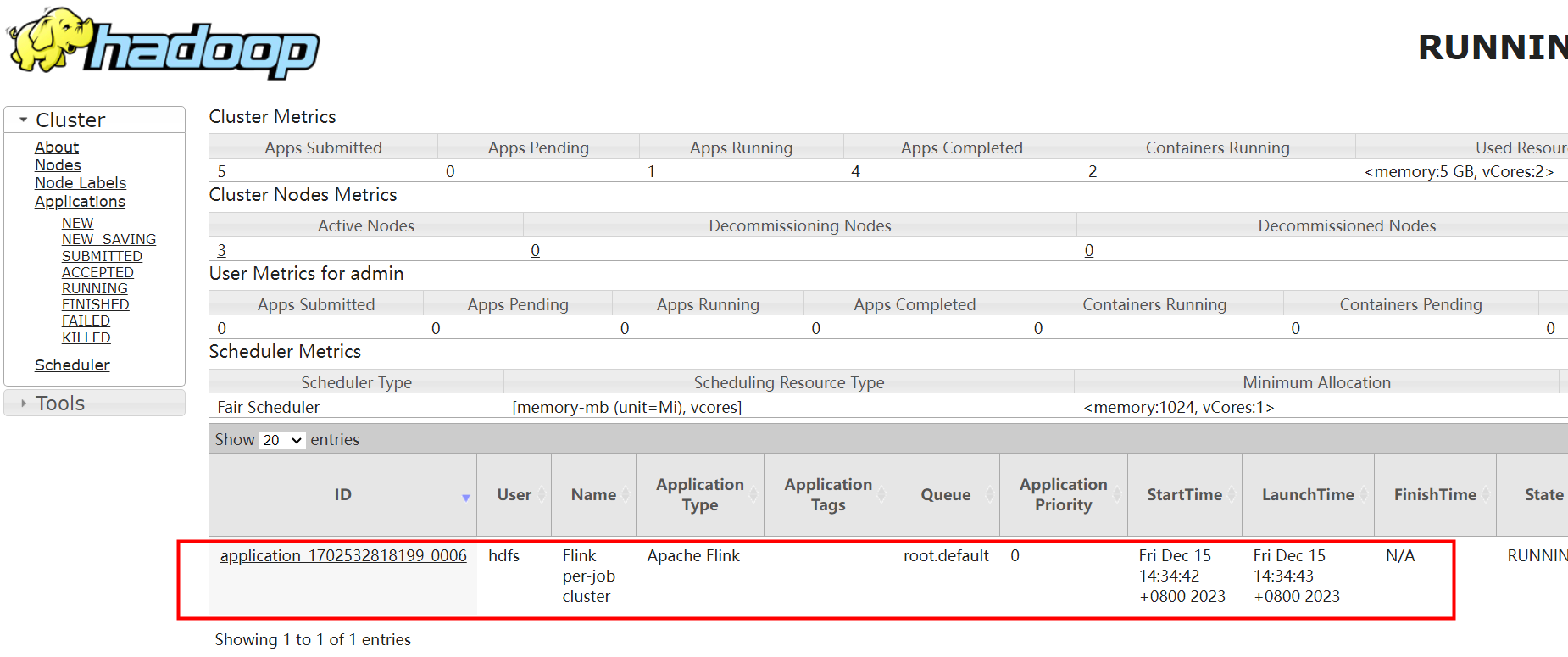
执行成功
这篇关于【DataSophon】大数据服务组件之Flink升级的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






