本文主要是介绍手把手入门MO | 如何通过通过 FineBI 实现 MatrixOne 的可视化报表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 概述
FineBI 是新一代大数据分析工具,它有助于企业的业务人员深入了解和充分利用他们的数据。在 FineBI 中,用户可以轻松地制作多样化的数据可视化信息,自由分析和探索数据。FineBI 具有多种数据连接功能,可用于创建各种复杂的报表,构建数据决策分析系统,广泛应用于公司经营管理、生产管理、财务智能核算、销售运营等领域。
MatrixOne 支持连接到数据可视化工具 FineBI。本文将指导您如何通过 FineBI 连接到单机版 MatrixOne,并创建各种可视化数据报表,将它们组装成仪表板,以便进行数据分析和探索。
2. 前期准备
- 已完成安装和启动 MatrixOne。
- 已完成安装 FineBI 和 FineBI 初始化设置。
#Note
本篇文档所展示的操作示例中使用的 FineBI 版本为 Linux 6.0 版本,你可以选择安装包 Linux_unix_FineBI6_0-CN.sh。
3. 通过 FineBI 连接 MatrixOne 服务
Step 1 - 登录 FineBI 后,选择管理系统 > 数据连接 > 数据连接管理 > 新建数据连接,如下图所示,选择 MySQL
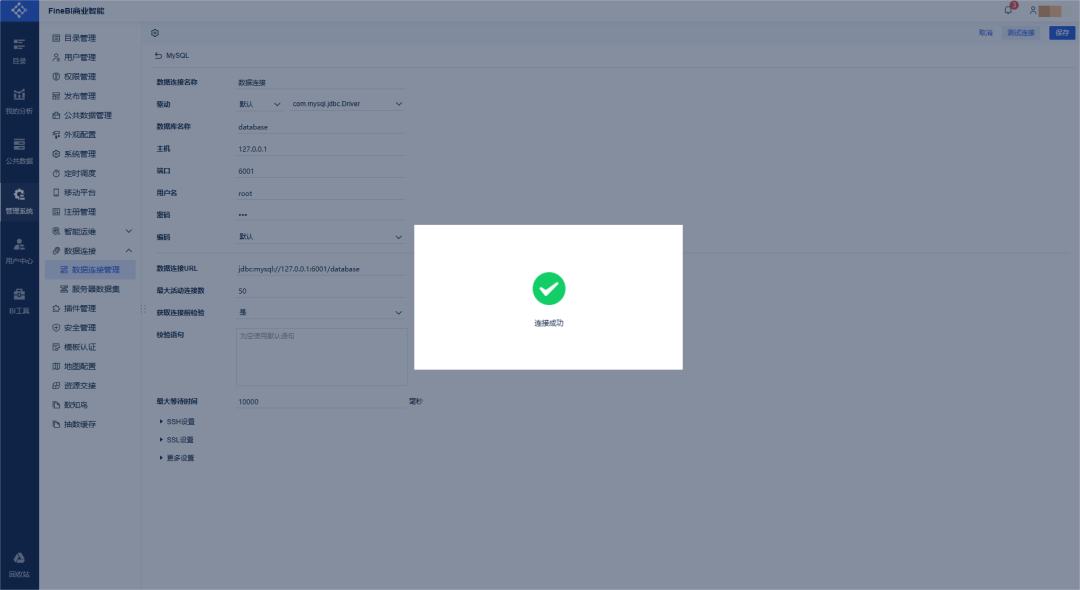
Step 2 - 填写 MatrixOne 连接配置,包括数据库名称、主机、端口、用户名、密码,其他参数可以按默认设置。您可以点击测试连接按钮来验证连接是否可用,然后点击保存进行连接保存:
4. 利用 MatrixOne 数据制作可视化报表
1. 创建 Demo 数据
首先,登录到 MatrixOne 数据库,然后执行以下 SQL 语句来创建演示所需的数据表和视图:
create database orders;
use orders;
CREATE TABLE `category` (`product_category_name` VARCHAR(255) DEFAULT NULL,
`product_category_name_english` VARCHAR(255) DEFAULT NULL );
CREATE TABLE `item` (`order_id` VARCHAR(255) NOT NULL, `order_item_id` INT DEFAULT null,
`product_id` VARCHAR(255) DEFAULT null,
`seller_id` VARCHAR(255) DEFAULT null, `shipping_limit_date` DATETIME DEFAULT null,
`price` DECIMAL(10,2) DEFAULT null,
`freight_value` DECIMAL(10,2) DEFAULT null
);
CREATE TABLE `review` (
`review_id` VARCHAR(255) NOT NULL,
`order_id` VARCHAR(255) DEFAULT null,
`review_score` TINYINT DEFAULT null,
`review_comment_title` VARCHAR(255) DEFAULT null,
`review_comment_message` TEXT DEFAULT null,
`review_creation_date` DATETIME DEFAULT null,
`review_answer_timestamp` DATETIME DEFAULT null,
PRIMARY KEY (`review_id`)
);
CREATE TABLE `order_time` (
`order_id` VARCHAR(255) NOT NULL,
`customer_id` VARCHAR(255) DEFAULT null,
`y` INT DEFAULT null,
`q` INT DEFAULT null,
`m` INT DEFAULT null,
`d` DATE DEFAULT null,
`h` INT DEFAULT null,
`order_purchase_timestamp` DATETIME DEFAULT null
);
CREATE TABLE `orders` (
`order_id` VARCHAR(255) NOT NULL,
`customer_id` VARCHAR(255) DEFAULT null,
`order_status` VARCHAR(255) DEFAULT null,
`order_purchase_timestamp` DATETIME DEFAULT null,
`order_approved_at` DATETIME DEFAULT null,
`order_delivered_carrier_date` DATETIME DEFAULT null,
`order_delivered_customer_date` DATETIME DEFAULT null,
`order_estimated_delivery_date` DATETIME DEFAULT null,
PRIMARY KEY (`order_id`)
);
CREATE TABLE `product` (
`product_id` VARCHAR(255) NOT NULL,
`product_category_name` VARCHAR(255) DEFAULT null,
`product_name_lenght` INT DEFAULT null,
`product_description_lenght` INT DEFAULT null,
`product_photos_qty` INT DEFAULT null,
`product_weight_g` INT DEFAULT null,
`product_length_cm` INT DEFAULT null,
`product_height_cm` INT DEFAULT null,
`product_width_cm` INT DEFAULT null,
PRIMARY KEY (`product_id`)
);
CREATE TABLE `rfm` (
`customer_id` VARCHAR(255) DEFAULT null,
`user_type` VARCHAR(255) DEFAULT null,
`shijian` DATE DEFAULT null
);CREATE view total_order_value as select t.order_id,product_id,seller_id,(price*total)+(freight_value*total) as order_value from (select order_id,count(*) as total from item group by order_id) t join item on t.order_id=item.order_id;CREATE view order_detail as select a.order_id,product_id,seller_id, customer_id,round(order_value,2) as order_value, y,q,m,d,h,order_purchase_timestamp from total_order_value a inner join order_time b on a.order_id=b.order_id;接下来,使用以下 SQL 导入语句,将预先准备的 Demo 数据导入到 MatrixOne 数据库的相应表中。
#Note
请注意,路径 /root/data/table_name.csv 是各表数据文件的路径,您可以参考此过程自行生成数据。
use orders;
load data local infile '/root/data/category.csv' into table category FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";
load data local infile '/root/data/review.csv' into table review FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";
load data local infile '/root/data/product.csv' into table product FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";
load data local infile '/root/data/item.csv' into table item FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";
load data local infile '/root/data/order_time.csv' into table order_time FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";
load data local infile '/root/data/orders.csv' into table orders FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";
load data local infile '/root/data/rfm.csv' into table rfm FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"' LINES TERMINATED BY "\r\n";2. 添加数据集
在 FineBI 中,点击公共数据,然后点击新建文件夹,创建并选择一个文件夹,然后点击新建数据集,选择 SQL 数据集,将 SQL 查询添加到选定的文件夹中。输入数据集名称并填写 SQL 查询,如下所示:
select d,
count(order_id) as order_num,
count(DISTINCT customer_id)
from orders.order_detail
group by d
order by d您可以点击预览按钮查看 SQL 查询的结果,然后点击确定进行保存:

下面是本示例中使用的所有查询 SQL 的示例:
-- 日活用户数及订单数
select d,
count(order_id) as order_num,
count(DISTINCT customer_id)
from orders.order_detail
group by d
order by d-- 月活用户数及订单数
select count(DISTINCT customer_id),
count(order_id),
concat(y, '-', m)
from orders.order_detail
group by y,m
order by y,m-- 各时段活跃用户数及订单数
select h,
count(DISTINCT customer_id),
count(order_id) order_num
from orders.order_detail
group by h
order by h-- 各类型用户数量
SELECT count(*),
user_type
from orders.rfm
GROUP BY user_type-- 月 GMV
select y,m,
sum(order_value),
concat(y, "-", m) month
from orders.order_detail
group by y,m
order by y,m-- 季度 GMV
select y,q,
sum(order_value) gmv,
concat(y, "季度", q) as quator
from orders.order_detail
group by y,q
order by concat(y, "季度", q) asc-- 季度 ARPU
select y,q,
round((sum(order_value)/count(DISTINCT customer_id)),2) arpu,
concat(y, "季度", q) as quator
from orders.order_detail
group by y,q
order by y,q-- 月度 ARPU
select y,m,
round((sum(order_value)/count(DISTINCT customer_id)),2) arpu,
concat(y, "-", m) as month
from orders.order_detail
group by y,m
order by y,m-- 重要挽留用户热门指数
SELECT e.product_category_name_english good_type,
SUM(a.order_value) ordder_total_value,
ROUND(AVG(c.review_score), 2) good_review_score,
(0.7*SUM(a.order_value)+0.3*10000*ROUND(AVG(c.review_score), 7))
top_rank_rate
FROM orders.order_detail a
INNER JOIN
(SELECT customer_id
from orders.rfm
WHERE user_type='重要挽留用户' ) as b ON a.customer_id=b.customer_id
LEFT JOIN orders.review c ON a.order_id=c.order_id
LEFT JOIN orders.product d ON a.product_id=d.product_id
LEFT JOIN orders.category e ON d.product_category_name=e.product_category_name
where e.product_category_name_english is not NULL
GROUP BY e.product_category_name_english limit 50-- 一般挽留用户热门指数
SELECT e.product_category_name_english good_type,
SUM(a.order_value) ordder_total_value,
ROUND(AVG(c.review_score), 2) good_review_score,
(0.7*SUM(a.order_value)+0.3*10000*ROUND(AVG(c.review_score), 7))
top_rank_rate
FROM orders.order_detail a
INNER JOIN
(SELECT customer_id from orders.rfm
WHERE user_type='一般挽留用户' ) as b ON a.customer_id=b.customer_id
LEFT JOIN orders.review c ON a.order_id=c.order_id
LEFT JOIN orders.product d ON a.product_id=d.product_id
LEFT JOIN orders.category e ON d.product_category_name=e.product_category_name
where e.product_category_name_english is not NULL
GROUP BY e.product_category_name_english limit 503. 更新数据
保存数据集后,您需要点击更新数据按钮,等待数据更新完成后才能进行分析:

4. 创建分析主题
本示例的分析主题用于可视化展示电商平台的一般挽留用户、重要挽留用户、月 ARPU、季度 ARPU、不同时段活跃用户、日活跃用户、月活跃用户数及订单数等数据,以辅助决策和提升业务。创建分析主题的具体步骤如下:
- 点击我的分析,然后点击新建文件夹,创建并选择一个文件夹。
- 点击新建分析主题,选择上一步创建的数据集,然后点击确定。

#Note
您可以使用批量选择功能来选择多个数据集进行主题分析。

点击添加组件按钮,选择图表类型,将左侧的字段按需要拖动到右侧,双击修改字段可视化名称,在下方修改组件名称,组件名称即该组件所分析的报表内容:


5. 组装仪表板
点击添加仪表板,将刚刚创建的组件添加到仪表板中。您可以自由拖动和缩放组件的大小和位置,并在下方修改组件名称,以描述该组件所分析的报表内容。

6. 发布仪表板
组装完成后,点击申请发布,设置发布名称、发布节点和展示平台。然后点击

现在,您可以在首页导航下找到刚刚发布的仪表板,并查看其展示效果。

关于矩阵起源
矩阵起源是是业界领先的大数据及数据库管理系统(DBMS)技术和服务提供商,主要团队成员来自国内外知名科技公司,具备强大的创新能力。矩阵起源的目标是打造并使用世界一流的数据基础设施技术和产品,协助企业实现从信息化、数字化到智能化的转型和升级。矩阵起源在云计算、数据库、大数据及人工智能相关领域拥有核心竞争力,具备广阔的行业和国际视野以及前瞻性,能够快速有效的将先进技术在不同领域实用化并规模化扩展。
关于MatrixOne
矩阵起源的核心产品MatrixOne,是基于云原生技术,可同时在公有云和私有云部署的多模数据库。该产品使用存算分离、读写分离、冷热分离的原创技术架构,能够在一套存储和计算系统下同时支持事务、分析、流、时序和向量等多种负载,并能够实时、按需的隔离或共享存储和计算资源。MatrixOne能够帮助用户大幅简化日益复杂的IT架构,提供极简、极灵活、高性价比和高性能的数据服务。
MatrixOrigin 官网:新一代超融合异构开源数据库-矩阵起源(深圳)信息科技有限公司 MatrixOne
Github 仓库:GitHub - matrixorigin/matrixone: Hyperconverged cloud-edge native database
关键词:超融合数据库、多模数据库、云原生数据库、国产数据库。
这篇关于手把手入门MO | 如何通过通过 FineBI 实现 MatrixOne 的可视化报表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





